NDepend Rules Explorer
- All
- Quality Gates
- Hot Spots
- Code Smells
- Code Smells Regression
- Object Oriented Design
- Design
- Architecture
- API Breaking Changes
- Code Coverage
- Dead Code
- Security
- Visibility
- Immutability
- Naming Conventions
- Source Files Organization
- .NET Framework Usage
- API Usage
- Defining JustMyCode
- Trend Metrics
- Code Diff Summary
- Statistics
- Samples of Custom rules
All
- Quality Gates Evolution
- Percentage Coverage
- Percentage Coverage on New Code
- Percentage Coverage on Refactored Code
- Blocker Issues
- Critical Issues
- New Blocker / Critical / High Issues
- Critical Rules Violated
- Treat Compiler Warnings as Error
- Percentage Debt
- Debt
- New Debt since Baseline
- Debt Rating per Namespace
- Annual Interest
- New Annual Interest since Baseline
- Unnecessary NDepend SuppressMessageAttribute Usage
- Avoid types too big
- Avoid types with too many methods
- Avoid types with too many fields
- Avoid methods too big, too complex
- Avoid methods with too many parameters
- Avoid methods with too many overloads
- Avoid methods potentially poorly commented
- Avoid types with poor cohesion
- Avoid methods with too many local variables
- Avoid unmaintainable code
- From now, all types added should respect basic quality principles
- From now, all types added should be 100% covered by tests
- From now, all methods added should respect basic quality principles
- Avoid decreasing code coverage by tests of types
- Avoid making complex methods even more complex
- Avoid making large methods even larger
- Avoid adding methods to a type that already had many methods
- Avoid adding instance fields to a type that already had many instance fields
- Avoid transforming an immutable type into a mutable one
- Avoid interfaces too big
- Base class should not use derivatives
- Class shouldn't be too deep in inheritance tree
- Class with no descendant should be sealed if possible
- Overrides of Method() should call base.Method()
- Do not hide base class methods
- A stateless class or structure might be turned into a static type
- Non-static classes should be instantiated or turned to static
- Methods should be declared static if possible
- Constructor should not call a virtual method
- Avoid the Singleton pattern
- Don't assign static fields from instance methods
- Avoid empty interfaces
- Avoid types initialization cycles
- Avoid custom delegates
- Types with disposable instance fields must be disposable
- Disposable types with unmanaged resources should declare finalizer
- Methods that create disposable object(s) and that don't call Dispose()
- Disposable Types Must Unsubscribe Events
- Classes that are candidate to be turned into structures
- Avoid namespaces with few types
- Nested types should not be visible
- Declare types in namespaces
- Empty static constructor can be discarded
- Instances size shouldn't be too big
- Attribute classes should be sealed
- Don't use obsolete types, methods or fields
- Do implement methods that throw NotImplementedException
- Override equals and operator equals on value types
- Boxing/unboxing should be avoided
- Avoid namespaces mutually dependent
- Avoid namespaces dependency cycles
- Avoid partitioning the code base through many small library Assemblies
- Enforcing Clean Architecture
- UI layer shouldn't use directly DB types
- UI layer shouldn't use directly DAL layer
- Assemblies with poor cohesion (RelationalCohesion)
- Namespaces with poor cohesion (RelationalCohesion)
- Assemblies that don't satisfy the Abstractness/Instability principle
- Avoid excessive class coupling
- Higher cohesion - lower coupling
- Avoid mutually-dependent types
- Example of custom rule to check for dependency
- API Breaking Changes: Types
- API Breaking Changes: Methods
- API Breaking Changes: Fields
- API Breaking Changes: Interfaces and Abstract Classes
- Broken serializable types
- Avoid changing enumerations Flags status
- API: New publicly visible types
- API: New publicly visible methods
- API: New publicly visible fields
- Code should be tested
- New Types and Methods should be tested
- Methods refactored should be tested
- Assemblies and Namespaces should be tested
- Types almost 100% tested should be 100% tested
- Namespaces almost 100% tested should be 100% tested
- Types that used to be 100% covered by tests should still be 100% covered
- Types tagged with FullCoveredAttribute should be 100% covered
- Types 100% covered should be tagged with FullCoveredAttribute
- Methods should have a low C.R.A.P score
- Complex Methods should be 100% tested
- Test Methods
- Methods directly called by test Methods
- Methods directly and indirectly called by test Methods
- Software Composition Analysis (SCA)
- Transitive Software Composition Analysis (SCA)
- Don't use CoSetProxyBlanket and CoInitializeSecurity
- Don't use System.Random for security purposes
- Don't use DES/3DES weak cipher algorithms
- Don't disable certificate validation
- Review publicly visible event handlers
- Pointers should not be publicly visible
- Seal methods that satisfy non-public interfaces
- Review commands vulnerable to SQL injection
- Review data adapters vulnerable to SQL injection
- Methods that could have a lower visibility
- Types that could have a lower visibility
- Fields that could have a lower visibility
- Types that could be declared as private, nested in a parent type
- Avoid publicly visible constant fields
- Fields should be declared as private or protected
- Constructors of abstract classes should be declared as protected or private
- Avoid public methods not publicly visible
- Event handler methods should be declared as private or protected
- Wrong usage of CannotDecreaseVisibilityAttribute
- Exception classes should be declared as public
- Methods that should be declared as 'public' in C#, 'Public' in VB.NET
- Fields should be marked as ReadOnly when possible
- Avoid non-readonly static fields
- Avoid static fields with a mutable field type
- Structures should be immutable
- Immutable struct should be declared as readonly
- Property Getters should be pure
- A field must not be assigned from outside its parent hierarchy types
- Don't assign a field from many methods
- Do not declare read only fields with mutable reference types
- Public read only array fields can be modified
- Types tagged with ImmutableAttribute must be immutable
- Types immutable should be tagged with ImmutableAttribute
- Methods tagged with PureAttribute must be pure
- Pure methods should be tagged with PureAttribute
- Record should be immutable
- Instance fields naming convention
- Static fields naming convention
- Interface name should begin with a 'I'
- Abstract base class should be suffixed with 'Base'
- Exception class name should be suffixed with 'Exception'
- Attribute class name should be suffixed with 'Attribute'
- Types name should begin with an Upper character
- Methods name should begin with an Upper character
- Do not name enum values 'Reserved'
- Avoid types with name too long
- Avoid methods with name too long
- Avoid fields with name too long
- Avoid having different types with same name
- Avoid prefixing type name with parent namespace name
- Avoid naming types and namespaces with the same identifier
- Don't call your method Dispose
- Methods prefixed with 'Try' should return a boolean
- Properties and fields that represent a collection of items should be named Items.
- DDD ubiquitous language check
- Avoid fields with same name in class hierarchy
- Avoid various capitalizations for method name
- Controller class name should be suffixed with 'Controller'
- Nested class members should not mask outer class' static members
- Avoid referencing source file out of the project directory
- Avoid duplicating a type definition across assemblies
- Avoid defining multiple types in a source file
- Namespace name should correspond to file location
- Types with source files stored in the same directory, should be declared in the same namespace
- Types declared in the same namespace, should have their source files stored in the same directory
- Mark ISerializable types with SerializableAttribute
- Mark assemblies with CLSCompliant (deprecated)
- Mark assemblies with ComVisible (deprecated)
- Mark attributes with AttributeUsageAttribute
- Remove calls to GC.Collect()
- Don't call GC.Collect() without calling GC.WaitForPendingFinalizers()
- Enum Storage should be Int32
- Do not raise too general exception types
- Do not raise reserved exception types
- Uri fields or properties should be of type System.Uri
- Types should not derive from System.ApplicationException
- Don't Implement ICloneable
- Don't create threads explicitly
- Don't use dangerous threading methods
- Monitor TryEnter/Exit must be both called within the same method
- ReaderWriterLock AcquireLock/ReleaseLock must be both called within the same method
- Don't tag instance fields with ThreadStaticAttribute
- Method non-synchronized that read mutable states
- Classes tagged with InitializeOnLoad should have a static constructor
- Avoid using non-generic GetComponent
- Avoid empty Unity message
- Avoid using Time.fixedDeltaTime with Update
- Use CreateInstance to create a scriptable object
- The SerializeField attribute is redundant on public fields
- InitializeOnLoadMethod should tag only static and parameterless methods
- Prefer using SetPixels32() over SetPixels()
- Don't use System.Reflection in performance critical messages
- # Lines of Code
- # Lines of Code (JustMyCode)
- # Lines of Code (NotMyCode)
- # Lines of Code Added since the Baseline
- # Source Files
- # Line Feed
- # IL Instructions
- # IL Instructions (NotMyCode)
- # Lines of Comments
- Percentage of Comments
- # Assemblies
- # Namespaces
- # Types
- # Public Types
- # Classes
- # Abstract Classes
- # Interfaces
- # Structures
- # Methods
- # Abstract Methods
- # Concrete Methods
- # Fields
- Max # Lines of Code for Methods (JustMyCode)
- Average # Lines of Code for Methods
- Average # Lines of Code for Methods with at least 3 Lines of Code
- Max # Lines of Code for Types (JustMyCode)
- Average # Lines of Code for Types
- Max Cyclomatic Complexity for Methods
- Average Cyclomatic Complexity for Methods
- Max IL Cyclomatic Complexity for Methods
- Average IL Cyclomatic Complexity for Methods
- Max IL Nesting Depth for Methods
- Average IL Nesting Depth for Methods
- Max # of Methods for Types
- Average # Methods for Types
- Max # of Methods for Interfaces
- Average # Methods for Interfaces
- Percentage Code Coverage
- # Lines of Code Covered
- # Lines of Code Not Covered
- # Lines of Code Uncoverable
- # Lines of Code in Types 100% Covered
- # Lines of Code in Methods 100% Covered
- Max C.R.A.P Score
- Average C.R.A.P Score
- Percentage JustMyCode Coverage
- # Lines of JustMyCode Covered
- # Lines of JustMyCode Not Covered
- New assemblies
- Assemblies removed
- Assemblies where code was changed
- New namespaces
- Namespaces removed
- Namespaces where code was changed
- New types
- Types removed
- Types where code was changed
- Heuristic to find types moved from one namespace or assembly to another
- Types directly using one or several types changed
- Types indirectly using one or several types changed
- New methods
- Methods removed
- Methods where code was changed
- Methods directly calling one or several methods changed
- Methods indirectly calling one or several methods changed
- New fields
- Fields removed
- Third party types that were not used and that are now used
- Third party types that were used and that are not used anymore
- Third party methods that were not used and that are now used
- Third party methods that were used and that are not used anymore
- Third party fields that were not used and that are now used
- Third party fields that were used and that are not used anymore
- Most used types (Rank)
- Most used methods (Rank)
- Most used assemblies (#AssembliesUsingMe)
- Most used namespaces (#NamespacesUsingMe )
- Most used types (#TypesUsingMe )
- Most used methods (#MethodsCallingMe )
- Namespaces that use many other namespaces (#NamespacesUsed )
- Types that use many other types (#TypesUsed )
- Methods that use many other methods (#MethodsCalled )
- High-level to low-level assemblies (Level)
- High-level to low-level namespaces (Level)
- High-level to low-level types (Level)
- High-level to low-level methods (Level)
- Check that the assembly Asm1 is not using the assembly Asm2
- Check that the namespace N1.N2 is not using the namespace N3.N4.N5
- Check that the assembly Asm1 is only using the assemblies Asm2, Asm3 or System.Runtime
- Check that the namespace N1.N2 is only using the namespaces N3.N4, N5 or System
- Check that AsmABC is the only assembly that is using System.Collections.Concurrent
- Check that only 3 assemblies are using System.Collections.Concurrent
- Check that all methods that call Foo.Fct1() also call Foo.Fct2(Int32)
- Check that all types that derive from Foo, also implement IFoo
- Check that all types that has the attribute FooAttribute are declared in the namespace N1.N2*
- Check that all synchronization objects are only used from the namespaces under MyNamespace.Sync
NDepend Rules
The best way to get introduced to these rules, is to analyze with NDepend a .NET code base you are working on, and browse these default rules to see what they can tell about the code.
Documentation to learn CQLinq:
Related documentation:
- Compute and Manage the Technical Debt
- Suppress Issues
- Validating Quality Gates and Code Rules in Visual Studio
- Reporting Code Rules Violations in the Report
- Query Generation with Rich Code Search
- Quality Gates and Build Failure
- Share Rules among Projects with NDepend Rule Files (.ndrules)
- Declare Rules in C# or VB.NET Source Code
- Code Metrics Definitions
Introduction to NDepend Rules (4 minutes) :
CQLinq rules are edited, compiled and executed live. Some facilities are proposed to browse and export the result:
Search results Save results for later use
Quality Gates Evolution
Show quality gates evolution between baseline and now.
When a quality gate relies on diff between now and baseline (like New Debt since Baseline) it is not executed against the baseline and as a consequence its evolution is not available.
Double-click a quality gate for editing.
Percentage Coverage
Code coverage is a measure used to describe the degree to which the source code of a program is tested by a particular test suite. A program with high code coverage, measured as a percentage, has had more of its source code executed during testing which suggests it has a lower chance of containing undetected software bugs compared to a program with low code coverage.
Code coverage is certainly the most important quality code metric. But coverage is not enough the team needs to ensure that results are checked at test-time. These checks can be done both in test code, and in application code through assertions. The important part is that a test must fail explicitly when a check gets unvalidated during the test execution.
This quality gate defines a warn threshold (80%) and a fail threshold (70%). These are indicative thresholds and in practice the more the better. To achieve high coverage and low risk, make sure that new and refactored classes gets 100% covered by tests and that the application and test code contains as many checks/assertions as possible.
Percentage Coverage on New Code
New Code is defined as methods added since the baseline.
To achieve high code coverage it is essential that new code gets properly tested and covered by tests. It is advised that all non-UI new classes gets 100% covered.
Typically 90% of a class is easy to cover by tests and 10% is hard to reach through tests. It means that this 10% remaining is not easily testable, which means it is not well designed, which often means that this code is especially error-prone. This is the reason why it is important to reach 100% coverage for a class, to make sure that potentially error-prone code gets tested.
Percentage Coverage on Refactored Code
Refactored Code is defined as methods where code was changed since the baseline.
Comment changes and formatting changes are not considered as refactoring.
To achieve high code coverage it is essential that refactored code gets properly tested and covered by tests. It is advised that when refactoring a class or a method, it is important to also write tests to make sure it gets 100% covered.
Typically 90% of a class is easy to cover by tests and 10% is hard to reach through tests. It means that this 10% remaining is not easily testable, which means it is not well designed, which often means that this code is especially error-prone. This is the reason why it is important to reach 100% coverage for a class, to make sure that potentially error-prone code gets tested.
Blocker Issues
An issue with the severity Blocker cannot move to production, it must be fixed.
The severity of an issue is either defined explicitly in the rule source code, either inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > Issue and Debt.
Critical Issues
An issue with a severity level Critical shouldn't move to production. It still can for business imperative needs purposes, but at worst it must be fixed during the next iterations.
The severity of an issue is either defined explicitly in the rule source code, either inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > Issue and Debt.
New Blocker / Critical / High Issues
An issue with the severity Blocker cannot move to production, it must be fixed.
An issue with a severity level Critical shouldn't move to production. It still can for business imperative needs purposes, but at worth it must be fixed during the next iterations.
An issue with a severity level High should be fixed quickly, but can wait until the next scheduled interval.
The severity of an issue is either defined explicitly in the rule source code, either inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > Issue and Debt.
Critical Rules Violated
The concept of critical rule is useful to pinpoint certain rules that should not be violated.
A rule can be made critical just by checking the Critical button in the rule edition control and then saving the rule.
This quality gate fails if any critical rule gets any violations.
When no baseline is available, rules that rely on diff are not counted. If you observe that this quality gate count slightly decreases with no apparent reason, the reason is certainly that rules that rely on diff are not counted because the baseline is not defined.
Treat Compiler Warnings as Error
Many compiler warnings, if ignored, could lead to runtime errors, unpredictable behavior, or security vulnerabilities. Addressing these warnings early can prevent such issues from becoming real problems in production.
Also, this approach encourages developers to follow best coding practices and to use language features correctly. It helps in maintaining a high standard of coding within a team, especially in projects with multiple contributors.
This Quality Gate requires Roslyn or R# Analyzers issues to be imported: https://www.ndepend.com/docs/roslyn-analyzer-issue-import https://www.ndepend.com/docs/resharper-code-inspection-issue-import
C# and VB.NET compiler warnings are Roslyn Analyzers issues whose rule id starts with "CS" or "VB".
This Quality Gate warns if there are any such warning. It fails if there are 10 or more such warnings.
See list of C# compiler warnings here: https://learn.microsoft.com/en-us/dotnet/csharp/misc/cs0183
Percentage Debt
% Debt total is defined as a percentage on:
• the estimated total effort to develop the code base
• and the the estimated total time to fix all issues (the Debt)
Estimated total effort to develop the code base is inferred from # lines of code of the code base and from the Estimated number of man-day to develop 1000 logical lines of code setting found in NDepend Project Properties > Issue and Debt.
Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
This quality gates fails if the estimated debt is more than 30% of the estimated effort to develop the code base, and warns if the estimated debt is more than 20% of the estimated effort to develop the code base
Debt
This Quality Gate is disabled per default because the fail and warn thresholds of unacceptable Debt in man-days can only depend on the project size, number of developers and overall context.
However you can refer to the default Quality Gate Percentage Debt.
The Debt is defined as the sum of estimated effort to fix all issues. Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
New Debt since Baseline
This Quality Gate fails if the estimated effort to fix new or worsened issues (what is called the New Debt since Baseline) is higher than 2 man-days.
This Quality Gate warns if this estimated effort is positive.
Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
Debt Rating per Namespace
Forbid namespaces with a poor Debt Rating equals to E or D.
The Debt Rating for a code element is estimated by the value of the Debt Ratio and from the various rating thresholds defined in this project Debt Settings.
The Debt Ratio of a code element is a percentage of Debt Amount (in floating man-days) compared to the estimated effort to develop the code element (also in floating man-days).
The estimated effort to develop the code element is inferred from the code elements number of lines of code, and from the project Debt Settings parameters estimated number of man-days to develop 1000 logical lines of code.
The logical lines of code corresponds to the number of debug breakpoints in a method and doesn't depend on code formatting nor comments.
The Quality Gate can be modified to match assemblies, types or methods with a poor Debt Rating, instead of matching namespaces.
Annual Interest
This Quality Gate is disabled per default because the fail and warn thresholds of unacceptable Annual-Interest in man-days can only depend on the project size, number of developers and overall context.
However you can refer to the default Quality Gate New Annual Interest since Baseline.
The Annual-Interest is defined as the sum of estimated annual cost in man-days, to leave all issues unfixed.
Each rule can either provide a formula to compute the Annual-Interest per issue, or assign a Severity level for each issue. Some thresholds defined in Project Properties > Issue and Debt > Annual Interest are used to infer an Annual-Interest value from a Severity level. Annual Interest documentation: https://www.ndepend.com/docs/technical-debt#AnnualInterest
New Annual Interest since Baseline
This Quality Gate fails if the estimated annual cost to leave all issues unfixed, increased from more than 2 man-days since the baseline.
This Quality Gate warns if this estimated annual cost is positive.
This estimated annual cost is named the Annual-Interest.
Each rule can either provide a formula to compute the Annual-Interest per issue, or assign a Severity level for each issue. Some thresholds defined in Project Properties > Issue and Debt > Annual Interest are used to infer an Annual-Interest value from a Severity level. Annual Interest documentation: https://www.ndepend.com/docs/technical-debt#AnnualInterest
Unnecessary NDepend SuppressMessageAttribute Usage
This quality gate identifies usages of SuppressMessageAttribute("NDepend", ...) that do not actually suppress any NDepend issues. These redundant attributes can be safely removed.
Note: This quality gate is disabled by default, as it is intended for advanced NDepend usage only.
Doc: https://www.ndepend.com/docs/suppress-issues
Types Hot Spots
This query lists types with most Debt, or in other words, types with issues that would need the largest effort to get fixed.
Both issues on the type and its members are taken account.
Since untested code often generates a lot of Debt, the type size and percentage coverage is shown (just uncomment t.PercentageCoverage in the query source code once you've imported the coverage data).
The Debt Rating and Debt Ratio are also shown for informational purpose.
--
The amount of Debt is not a measure to prioritize the effort to fix issues, it is an estimation of how far the team is from clean code that abides by the rules set.
For each issue the Annual Interest estimates the annual cost to leave the issues unfixed. The Severity of an issue is estimated through thresholds from the Annual Interest.
The Debt Breaking Point represents the duration from now when the estimated cost to leave the issue unfixed costs as much as the estimated effort to fix it.
Hence the shorter the Debt Breaking Point the largest the Return on Investment for fixing the issue. The Breaking Point is the right metric to prioritize issues fix.
Types to Fix Priority
This query lists types per increasing Debt Breaking Point.
For each issue the Debt estimates the effort to fix the issue, and the Annual Interest estimates the annual cost to leave the issue unfixed. The Severity of an issue is estimated through thresholds from the Annual Interest of the issue.
The Debt Breaking Point represents the duration from now when the estimated cost to leave the issue unfixed costs as much as the estimated effort to fix it.
Hence the shorter the Debt Breaking Point the largest the Return on Investment for fixing the issues.
Often new and refactored types since baseline will be listed first, because issues on these types get a higher Annual Interest because it is important to focus first on new issues.
--
Both issues on the type and its members are taken account.
Only types with at least 30 minutes of Debt are listed to avoid polluting the list with the numerous types with small Debt, on which the Breaking Point value makes less sense.
The Annual Interest estimates the cost per year in man-days to leave these issues unfixed.
Since untested code often generates a lot of Debt, the type size and percentage coverage is shown (just uncomment t.PercentageCoverage in the query source code once you've imported the coverage data).
The Debt Rating and Debt Ratio are also shown for informational purpose.
Issues to Fix Priority
This query lists issues per increasing Debt Breaking Point.
Double-click an issue to edit its rule and select the issue in the rule result. This way you can view all information concerning the issue.
For each issue the Debt estimates the effort to fix the issue, and the Annual Interest estimates the annual cost to leave the issue unfixed. The Severity of an issue is estimated through thresholds from the Annual Interest of the issue.
The Debt Breaking Point represents the duration from now when the estimated cost to leave the issue unfixed costs as much as the estimated effort to fix it.
Hence the shorter the Debt Breaking Point the largest the Return on Investment for fixing the issue.
Often issues on new and refactored code elements since baseline will be listed first, because such issues get a higher Annual Interest because it is important to focus first on new issues on recent code.
More documentation: https://www.ndepend.com/docs/technical-debt
Debt and Issues per Rule
This query lists violated rules with most Debt first.
A rule violated has issues. For each issue the Debt estimates the effort to fix the issue.
--
The amount of Debt is not a measure to prioritize the effort to fix issues, it is an estimation of how far the team is from clean code that abides by the rules set.
For each issue the Annual Interest estimates the annual cost to leave the issues unfixed. The Severity of an issue is estimated through thresholds from the Annual Interest.
The Debt Breaking Point represents the duration from now when the estimated cost to leave the issue unfixed costs as much as the estimated effort to fix it.
Hence the shorter the Debt Breaking Point the largest the Return on Investment for fixing the issue. The Breaking Point is the right metric to prioritize issues fix.
--
Notice that rules can be grouped in Rule Category. This way you'll see categories that generate most Debt.
Typically the rules that generate most Debt are the ones related to Code Coverage by Tests, Architecture and Code Smells.
More documentation: https://www.ndepend.com/docs/technical-debt
New Debt and Issues per Rule
This query lists violated rules that have new issues since baseline, with most new Debt first.
A rule violated has issues. For each issue the Debt estimates the effort to fix the issue.
--
New issues since the baseline are consequence of recent code refactoring sessions. They represent good opportunities of fix because the code recently refactored is fresh in the developers mind, which means fixing now costs less than fixing later.
Fixing issues on recently touched code is also a good way to foster practices that will lead to higher code quality and maintainability, including writing unit-tests and avoiding unnecessary complex code.
--
Notice that rules can be grouped in Rule Category. This way you'll see categories that generate most Debt.
Typically the rules that generate most Debt are the ones related to Code Coverage by Tests, Architecture and Code Smells.
More documentation: https://www.ndepend.com/docs/technical-debt
Debt and Issues per Code Element
This query lists code elements that have issues, with most Debt first.
For each code element the Debt estimates the effort to fix the element issues.
The amount of Debt is not a measure to prioritize the effort to fix issues, it is an estimation of how far the team is from clean code that abides by the rules set.
For each element the Annual Interest estimates the annual cost to leave the elements issues unfixed. The Severity of an issue is estimated through thresholds from the Annual Interest of the issue.
The Debt Breaking Point represents the duration from now when the estimated cost to leave the issues unfixed costs as much as the estimated effort to fix it.
Hence the shorter the Debt Breaking Point the largest the Return on Investment for fixing the issue. The Breaking Point is the right metric to prioritize issues fix.
New Debt and Issues per Code Element
This query lists code elements that have new issues since baseline, with most new Debt first.
For each code element the Debt estimates the effort to fix the element issues.
New issues since the baseline are consequence of recent code refactoring sessions. They represent good opportunities of fix because the code recently refactored is fresh in the developers mind, which means fixing now costs less than fixing later.
Fixing issues on recently touched code is also a good way to foster practices that will lead to higher code quality and maintainability, including writing unit-tests and avoiding unnecessary complex code.
Avoid types too big
This rule matches types with more than 200 lines of code. Only lines of code in JustMyCode methods are taken account.
Types where NbLinesOfCode > 200 are extremely complex to develop and maintain. See the definition of the NbLinesOfCode metric here https://www.ndepend.com/docs/code-metrics#NbLinesOfCode
Maybe you are facing the God Class phenomenon: A God Class is a class that controls way too many other classes in the system and has grown beyond all logic to become The Class That Does Everything.
How to Fix:
Types with many lines of code should be split in a group of smaller types.
To refactor a God Class you'll need patience, and you might even need to recreate everything from scratch. Here are a few refactoring advices:
• The logic in the God Class must be split in smaller classes. These smaller classes can eventually become private classes nested in the original God Class, whose instances objects become composed of instances of smaller nested classes.
• Smaller classes partitioning should be driven by the multiple responsibilities handled by the God Class. To identify these responsibilities it often helps to look for subsets of methods strongly coupled with subsets of fields.
• If the God Class contains way more logic than states, a good option can be to define one or several static classes that contains no static field but only pure static methods. A pure static method is a function that computes a result only from inputs parameters, it doesn't read nor assign any static or instance field. The main advantage of pure static methods is that they are easily testable.
• Try to maintain the interface of the God Class at first and delegate calls to the new extracted classes. In the end the God Class should be a pure facade without its own logic. Then you can keep it for convenience or throw it away and start to use the new classes only.
• Unit Tests can help: write tests for each method before extracting it to ensure you don't break functionality.
The estimated Debt, which means the effort to fix such issue, varies linearly from 1 hour for a 200 lines of code type, up to 10 hours for a type with 2.000 or more lines of code.
In Debt and Interest computation, this rule takes account of the fact that static types with no mutable fields are just a collection of static methods that can be easily split and moved from one type to another.
Avoid types with too many methods
This rule matches types with more than 20 methods. Such type might be hard to understand and maintain.
This rule doesn't match type with at least a non-constant field because it is ok to have a class with many stateless methods
Notice that methods like constructors or property and event accessors are not taken account.
Having many methods for a type might be a symptom of too many responsibilities implemented.
Maybe you are facing the God Class phenomenon: A God Class is a class that controls way too many other classes in the system and has grown beyond all logic to become The Class That Does Everything.
How to Fix:
To refactor properly a God Class please read HowToFix advices from the default rule Types too Big.
The estimated Debt, which means the effort to fix such issue, varies linearly from 1 hour for a type with 20 methods, up to 10 hours for a type with 200 or more methods.
In Debt and Interest computation, this rule takes account of the fact that static types with no mutable fields are just a collection of static methods that can be easily split and moved from one type to another.
Avoid types with too many fields
This rule matches types with more than 15 fields. Such type might be hard to understand and maintain.
Notice that constant fields and static-readonly fields are not counted. Enumerations types are not counted also.
Having many fields for a type might be a symptom of too many responsibilities implemented.
How to Fix:
To refactor such type and increase code quality and maintainability, certainly you'll have to group subsets of fields into smaller types and dispatch the logic implemented into the methods into these smaller types.
More refactoring advices can be found in the default rule Types to Big, HowToFix section.
The estimated Debt, which means the effort to fix such issue, varies linearly from 1 hour for a type with 15 fields, to up to 10 hours for a type with 200 or more fields.
Avoid methods too big, too complex
This rule matches methods where ILNestingDepth > 2 and CyclomaticComplexity > 17 Such method is typically hard to understand and maintain.
Maybe you are facing the God Method phenomenon. A "God Method" is a method that does way too many processes in the system and has grown beyond all logic to become The Method That Does Everything. When the need for new processes increases suddenly some programmers realize: why should I create a new method for each process if I can only add an if.
See the definition of the CyclomaticComplexity metric here: https://www.ndepend.com/docs/code-metrics#CC
See the definition of the ILNestingDepth metric here: https://www.ndepend.com/docs/code-metrics#ILNestingDepth
How to Fix:
A large and complex method should be split in smaller methods, or even one or several classes can be created for that.
During this process it is important to question the scope of each variable local to the method. This can be an indication if such local variable will become an instance field of the newly created class(es).
Large switch…case structures might be refactored through the help of a set of types that implement a common interface, the interface polymorphism playing the role of the switch cases tests.
Unit Tests can help: write tests for each method before extracting it to ensure you don't break functionality.
The estimated Debt, which means the effort to fix such issue, varies from 20 minutes to 3 hours, linearly from a weighted complexity score.
Avoid methods with too many parameters
This rule matches methods with 8 or more parameters. Such method is painful to call and might degrade performance. See the definition of the NbParameters metric here: https://www.ndepend.com/docs/code-metrics#NbParameters
This rule doesn't match a method that overrides a third-party method with 10 or more parameters because such situation is the consequence of a lower-level problem.
For the same reason, this rule doesn't match a constructor that calls a base constructor with 8 or more parameters.
How to Fix:
More properties/fields can be added to the declaring type to handle numerous states. An alternative is to provide a class or a structure dedicated to handle arguments passing. For example see the class System.Diagnostics.ProcessStartInfo and the method System.Diagnostics.Process.Start(ProcessStartInfo).
The estimated Debt, which means the effort to fix such issue, varies linearly from 1 hour for a method with 8 parameters, up to 6 hours for a methods with 40 or more parameters.
Avoid methods with too many overloads
Method overloading is the ability to create multiple methods of the same name with different implementations, and various set of parameters.
This rule matches sets of methods with 7 overloads or more.
The "too many overloads" phenomenon typically arises when an algorithm accepts a diverse range of input parameters. Each overload is introduced as a means to accommodate a different combination of input parameters.
Such method set might be a problem to maintain and provokes ambiguity and make the code less readable.
The too many overloads phenomenon can also be a consequence of the usage of the visitor design pattern http://en.wikipedia.org/wiki/Visitor_pattern since a method named Visit() must be provided for each sub type. For this reason, the default version of this rule doesn't match overloads whose name start with "visit" or "dispatch" (case-insensitive) to avoid match overload visitors, and you can adapt this rule to your own naming convention.
Sometime too many overloads phenomenon is not the symptom of a problem, for example when a numeric to something conversion method applies to all numeric and nullable numeric types.
See the definition of the NbOverloads metric here https://www.ndepend.com/docs/code-metrics#NbOverloads
Notice that this rule doesn't include in the overloads list methods that override a third-party method nor constructors that call a base constructor. Such situations are consequences of lower-level problems.
How to Fix:
In such situation, the C# language feature optional parameters, named arguments or parameter array (with the params keyword) can be used instead.
The estimated Debt, which means the effort to fix such issue, is of 3 minutes per method overload.
Avoid methods potentially poorly commented
This rule matches methods with less than 10% of comment lines and that have at least 20 lines of code. Such method might need to be more commented.
See the definitions of the Comments metric here: https://www.ndepend.com/docs/code-metrics#PercentageComment https://www.ndepend.com/docs/code-metrics#NbLinesOfComment
Notice that only comments about the method implementation (comments in method body) are taken account.
How to Fix:
Typically add more comment. But code commenting is subject to controversy. While poorly written and designed code would needs a lot of comment to be understood, clean code doesn't need that much comment, especially if variables and methods are properly named and convey enough information. Unit-Test code can also play the role of code commenting.
However, even when writing clean and well-tested code, one will have to write hacks at a point, usually to circumvent some API limitations or bugs. A hack is a non-trivial piece of code, that doesn't make sense at first glance, and that took time and web research to be found. In such situation comments must absolutely be used to express the intention, the need for the hacks and the source where the solution has been found.
The estimated Debt, which means the effort to comment such method, varies linearly from 2 minutes for 10 lines of code not commented, up to 20 minutes for 200 or more, lines of code not commented.
Avoid types with poor cohesion
This rule is based on the LCOM code metric, LCOM stands for Lack Of Cohesion of Methods. See the definition of the LCOM metric here https://www.ndepend.com/docs/code-metrics#LCOM
The LCOM metric measures the fact that most methods are using most fields. A class is considered utterly cohesive (which is good) if all its methods use all its instance fields.
Only types with enough methods and fields are taken account to avoid bias. The LCOM takes its values in the range [0-1].
This rule matches types with LCOM higher than 0.84. Such value generally pinpoints a poorly cohesive class.
How to Fix:
To refactor a poorly cohesive type and increase code quality and maintainability, certainly you'll have to split the type into several smaller and more cohesive types that together, implement the same logic.
For each matched type, you can right-click it then click the menu "Show on the Dependency Graph". This way you can visualize how the fields are used by methods and plan the refactoring based on this information.
The estimated Debt, which means the effort to fix such issue, varies linearly from 5 minutes for a type with a low poorCohesionScore, up to 4 hours for a type with high poorCohesionScore.
Avoid methods with too many local variables
This rule matches methods with more than 15 variables.
Methods where NbVariables > 8 are hard to understand and maintain. Methods where NbVariables > 15 are extremely complex and must be refactored.
The number of variables is inferred from the compiled IL code of the method. The C# and VB.NET compiler might introduce some hidden variables for language constructs like lambdas, so the default threshold of this rule is set to 15 to avoid matching false positives.
How to Fix:
To refactor such method and increase code quality and maintainability, certainly you'll have to split the method into several smaller methods or even create one or several classes to implement the logic.
During this process it is important to question the scope of each variable local to the method. This can be an indication if such local variable will become an instance field of the newly created class(es).
The estimated Debt, which means the effort to fix such issue, varies linearly from 10 minutes for a method with 15 variables, up to 2 hours for a methods with 80 or more variables.
Avoid unmaintainable code
This rule detects methods with a low maintainability index and high cyclomatic complexity. Such code is hard to understand, error prone and risky to modify. Refactor it to improve reliability, readability, and long-term maintainability.
See the maintainability index, cyclomatic complexity and Halstead volume definitions here:
https://www.ndepend.com/docs/code-metrics#MaintainabilityIndex
https://www.ndepend.com/docs/code-metrics#CC
https://www.ndepend.com/docs/code-metrics#HalsteadVolume
How to Fix:
To resolve this issue, refactor the method by splitting it into smaller, more focused components
From now, all types added should respect basic quality principles
This rule is executed only if a baseline for comparison is defined (diff mode). This rule operates only on types added since baseline.
This rule can be easily modified to also match types refactored since baseline, that don't satisfy all quality criteria.
Types matched by this rule not only have been recently added or refactored, but also somehow violate one or several basic quality principles, whether it has too many methods, it has too many fields, or is using too many types. Any of these criteria are often a symptom of a type with too many responsibilities.
Notice that to count methods and fields, methods like constructors or property and event accessors are not taken account. Notice that constants fields and static-readonly fields are not counted. Enumerations types are not counted also.
How to Fix:
To refactor such type and increase code quality and maintainability, certainly you'll have to split the type into several smaller types that together, implement the same logic.
Issues of this rule have a constant 10 minutes Debt, because the Debt, which means the effort to fix such issue, is already estimated for issues of rules in the category Code Smells.
However issues of this rule have a High severity, with even more interests for issues on new types since baseline, because the proper time to increase the quality of these types is now, before they get committed in the next production release.
From now, all types added should be 100% covered by tests
This rule is executed only if a baseline for comparison is defined (diff mode). This rule operates only on types added since baseline.
This rule can be easily modified to also match types refactored since baseline, that are not 100% covered by tests.
This rule is executed only if some code coverage data is imported from some code coverage files.
Often covering 10% of remaining uncovered code of a class, requires as much work as covering the first 90%. For this reason, typically teams estimate that 90% coverage is enough. However untestable code usually means poorly written code which usually leads to error prone code. So it might be worth refactoring and making sure to cover the 10% remaining code because most tricky bugs might come from this small portion of hard-to-test code.
Not all classes should be 100% covered by tests (like UI code can be hard to test) but you should make sure that most of the logic of your application is defined in some easy-to-test classes, 100% covered by tests.
In this context, this rule warns when a type added or refactored since the baseline, is not fully covered by tests.
How to Fix:
Write more unit-tests dedicated to cover code not covered yet. If you find some hard-to-test code, it is certainly a sign that this code is not well designed and hence, needs refactoring.
You'll find code impossible to cover by unit-tests, like calls to MessageBox.Show(). An infrastructure must be defined to be able to mock such code at test-time.
Issues of this rule have a constant 10 minutes Debt, because the Debt, which means the effort to write tests for the culprit type, is already estimated for issues in the category Code Coverage.
However issues of this rule have a High severity, with even more interests for issues on new types since baseline, because the proper time to write tests for these types is now, before they get committed in the next production release.
From now, all methods added should respect basic quality principles
This rule is executed only if a baseline for comparison is defined (diff mode). This rule operates only on methods added or refactored since the baseline.
This rule can be easily modified to also match methods refactored since baseline, that don't satisfy all quality criteria.
Methods matched by this rule not only have been recently added or refactored, but also somehow violate one or several basic quality principles, whether it is too large (too many lines of code), too complex (too many if, switch case, loops…) has too many variables, too many parameters or has too many overloads.
How to Fix:
To refactor such method and increase code quality and maintainability, certainly you'll have to split the method into several smaller methods or even create one or several classes to implement the logic.
During this process it is important to question the scope of each variable local to the method. This can be an indication if such local variable will become an instance field of the newly created class(es).
Large switch…case structures might be refactored through the help of a set of types that implement a common interface, the interface polymorphism playing the role of the switch cases tests.
Unit Tests can help: write tests for each method before extracting it to ensure you don't break functionality.
Issues of this rule have a constant 5 minutes Debt, because the Debt, which means the effort to fix such issue, is already estimated for issues of rules in the category Code Smells.
However issues of this rule have a High severity, with even more interests for issues on new methods since baseline, because the proper time to increase the quality of these methods is now, before they get committed in the next production release.
Avoid decreasing code coverage by tests of types
This rule is executed only if a baseline for comparison is defined (diff mode).
This rule is executed only if some code coverage data is imported from some code coverage files.
This rule warns when the number of lines of a type covered by tests decreased since the baseline. In case the type faced some refactoring since the baseline, this loss in coverage is estimated only for types with more lines of code, where # lines of code covered now is lower than # lines of code covered in baseline + the extra number of lines of code.
Such situation can mean that some tests have been removed but more often, this means that the type has been modified, and that changes haven't been covered properly by tests.
To visualize changes in code, right-click a matched type and select:
• Compare older and newer versions of source file
• or Compare older and newer versions decompiled with Reflector
How to Fix:
Write more unit-tests dedicated to cover changes in matched types not covered yet. If you find some hard-to-test code, it is certainly a sign that this code is not well designed and hence, needs refactoring.
The estimated Debt, which means the effort to cover by test code that used to be covered, varies linearly 15 minutes to 3 hours, depending on the number of lines of code that are not covered by tests anymore.
Severity of issues of this rule varies from High to Critical depending on the number of lines of code that are not covered by tests anymore. Because the loss in code coverage happened since the baseline, the severity is high because it is important to focus on these issues now, before such code gets released in production.
Avoid making complex methods even more complex
This rule is executed only if a baseline for comparison is defined (diff mode).
The method complexity is measured through the code metric Cyclomatic Complexity defined here: https://www.ndepend.com/docs/code-metrics#CC
This rule warns when a method already complex (i.e with Cyclomatic Complexity higher than 6) become even more complex since the baseline.
This rule needs assemblies PDB files and source code to be available at analysis time, because the Cyclomatic Complexity is inferred from the source code and source code location is inferred from PDB files. See: https://www.ndepend.com/docs/ndepend-analysis-inputs-explanation
To visualize changes in code, right-click a matched method and select:
• Compare older and newer versions of source file
• or Compare older and newer versions decompiled with Reflector
How to Fix:
A large and complex method should be split in smaller methods, or even one or several classes can be created for that.
During this process it is important to question the scope of each variable local to the method. This can be an indication if such local variable will become an instance field of the newly created class(es).
Large switch…case structures might be refactored through the help of a set of types that implement a common interface, the interface polymorphism playing the role of the switch cases tests.
Unit Tests can help: write tests for each method before extracting it to ensure you don't break functionality.
The estimated Debt, which means the effort to fix such issue, varies linearly from 15 to 60 minutes depending on the extra complexity added.
Issues of this rule have a High severity, because it is important to focus on these issues now, before such code gets released in production.
Avoid making large methods even larger
This rule is executed only if a baseline for comparison is defined (diff mode).
This rule warns when a method already large (i.e with more than 15 lines of code) become even larger since the baseline.
The method size is measured through the code metric # Lines of Code defined here: https://www.ndepend.com/docs/code-metrics#NbLinesOfCode
This rule needs assemblies PDB files to be available at analysis time, because the # Lines of Code is inferred from PDB files. See: https://www.ndepend.com/docs/ndepend-analysis-inputs-explanation
To visualize changes in code, right-click a matched method and select:
• Compare older and newer versions of source file
• or Compare older and newer versions decompiled with Reflector
How to Fix:
Usually too big methods should be split in smaller methods.
But long methods with no branch conditions, that typically initialize some data, are not necessarily a problem to maintain, and might not need refactoring.
The estimated Debt, which means the effort to fix such issue, varies linearly from 5 to 20 minutes depending on the number of lines of code added.
The estimated Debt, which means the effort to fix such issue, varies linearly from 10 to 60 minutes depending on the extra complexity added.
Issues of this rule have a High severity, because it is important to focus on these issues now, before such code gets released in production.
Avoid adding methods to a type that already had many methods
This rule is executed only if a baseline for comparison is defined (diff mode).
Types where number of methods is greater than 40 might be hard to understand and maintain.
This rule lists types that already had more than 40 methods at the baseline time, and for which new methods have been added.
Having many methods for a type might be a symptom of too many responsibilities implemented.
Notice that constructors and methods generated by the compiler are not taken account.
How to Fix:
To refactor such type and increase code quality and maintainability, certainly you'll have to split the type into several smaller types that together, implement the same logic.
The estimated Debt, which means the effort to fix such issue, is equal to 10 minutes per method added.
Issues of this rule have a High severity, because it is important to focus on these issues now, before such code gets released in production.
Avoid adding instance fields to a type that already had many instance fields
This rule is executed only if a baseline for comparison is defined (diff mode).
Types where number of fields is greater than 15 might be hard to understand and maintain.
This rule lists types that already had more than 15 fields at the baseline time, and for which new fields have been added.
Having many fields for a type might be a symptom of too many responsibilities implemented.
Notice that constants fields and static-readonly fields are not taken account. Enumerations types are not taken account also.
How to Fix:
To refactor such type and increase code quality and maintainability, certainly you'll have to group subsets of fields into smaller types and dispatch the logic implemented into the methods into these smaller types.
The estimated Debt, which means the effort to fix such issue, is equal to 10 minutes per field added.
Issues of this rule have a High severity, because it is important to focus on these issues now, before such code gets released in production.
Avoid transforming an immutable type into a mutable one
This rule is executed only if a baseline for comparison is defined (diff mode).
A type is considered as immutable if its instance fields cannot be modified once an instance has been built by a constructor.
Being immutable has several fortunate consequences for a type. For example its instance objects can be used concurrently from several threads without the need to synchronize accesses.
Hence users of such type often rely on the fact that the type is immutable. If an immutable type becomes mutable, there are chances that this will break users code.
This is why this rule warns about such immutable type that become mutable.
The estimated Debt, which means the effort to fix such issue, is equal to 2 minutes per instance field that became mutable.
How to Fix:
If being immutable is an important property for a matched type, then the code must be refactored to preserve immutability.
The estimated Debt, which means the effort to fix such issue, is equal to 10 minutes plus 10 minutes per instance fields of the matched type that is now mutable.
Issues of this rule have a High severity, because it is important to focus on these issues now, before such code gets released in production.
Avoid interfaces too big
This rule matches interfaces with more than 14 methods, properties or events. Interfaces are abstractions and are meant to simplify the code. They should have a single responsibility, and when they become overly large and complex, it means they have too many responsibilities.
The Interface Segregation Principle (ISP) advises us that when a large interface is used by various consumers, each of which only requires specific methods, unnecessarily coupling those consumers through the same interface can occur.
Furthermore, when dealing with large interfaces, we often end up with larger classes that attempt to handle too many unrelated tasks.
A property with a getter or setter or both count as one member. An event count as one member.
How to Fix:
Typically to fix such issue, the interface must be refactored in a grape of smaller single-responsibility interfaces.
For example if an interface IFoo handles both read and write operations, it can be split into two interfaces: IFooReader and IFooWriter.
A usual problem for a large public interface is that it has many clients that consume it. As a consequence splitting it in smaller interfaces has an important impact and it is not always feasible.
The estimated Debt, which means the effort to fix such issue, varies linearly from 20 minutes for an interface with 10 methods, up to 7 hours for an interface with 100 or more methods. The Debt is divided by two if the interface is not publicly visible, because in such situation only the current project is impacted by the refactoring.
Base class should not use derivatives
In Object-Oriented Programming, the open/closed principle states: software entities (components, classes, methods, etc.) should be open for extension, but closed for modification. http://en.wikipedia.org/wiki/Open/closed_principle
Hence a base class should be designed properly to make it easy to derive from, this is extension. But creating a new derived class, or modifying an existing one, shouldn't provoke any modification in the base class. And if a base class is using some derivative classes somehow, there are good chances that such modification will be needed.
Extending the base class is not anymore a simple operation, this is not good design.
Note that this rule doesn't warn when a base class is using a derived class that is nested in the base class and declared as private. In such situation we consider that the derived class is an encapsulated implementation detail of the base class.
How to Fix:
Understand the need for using derivatives, then imagine a new design, and then refactor.
Typically an algorithm in the base class needs to access something from derived classes. You can try to encapsulate this access behind an abstract or a virtual method.
If you see in the base class some conditions on typeof(DerivedClass) not only urgent refactoring is needed. Such condition can easily be replaced through an abstract or a virtual method.
Sometime you'll see a base class that creates instance of some derived classes. In such situation, certainly using the factory method pattern http://en.wikipedia.org/wiki/Factory_method_pattern or the abstract factory pattern http://en.wikipedia.org/wiki/Abstract_factory_pattern will improve the design.
The estimated Debt, which means the effort to fix such issue, is equal to 3 minutes per derived class used by the base class + 3 minutes per member of a derived class used by the base class.
Class shouldn't be too deep in inheritance tree
This rule warns about classes having 4 or more base classes. Notice that third-party base classes are not counted because this rule is about your code design, not third-party libraries consumed design.
In theory, there is nothing wrong having a long inheritance chain, if the modeling has been well thought out, if each base class is a well-designed refinement of the domain.
In practice, modeling properly a domain demands a lot of effort and experience and more often than not, a long inheritance chain is a sign of confused design, that is hard to work with and maintain.
How to Fix:
In Object-Oriented Programming, a well-known motto is Favor Composition over Inheritance.
This is because inheritance comes with pitfalls. In general, the implementation of a derived class is very bound up with the base class implementation. Also a base class exposes implementation details to its derived classes, that's why it's often said that inheritance breaks encapsulation.
On the other hands, Composition favors binding with interfaces over binding with implementations. Hence, not only the encapsulation is preserved, but the design is clearer, because interfaces make it explicit and less coupled.
Hence, to break a long inheritance chain, Composition is often a powerful way to enhance the design of the refactored underlying logic.
You can also read: http://en.wikipedia.org/wiki/Composition_over_inheritance and http://stackoverflow.com/questions/49002/prefer-composition-over-inheritance
The estimated Debt, which means the effort to fix such issue, depends linearly upon the depth of inheritance.
Class with no descendant should be sealed if possible
If a non-static class isn't declared with the keyword sealed, it means that it can be subclassed everywhere the non-sealed class is visible.
Making a class a base class requires significant design effort. Subclassing a non-sealed class, not initially designed to be subclassed, will lead to unanticipated design issue.
Most classes are non-sealed because developers don't care about the keyword sealed, not because the primary intention was to write a class that can be subclassed.
There are performance gain in declaring a class as sealed. See a benchmark here: https://www.meziantou.net/performance-benefits-of-sealed-class.htm
But the real benefit of doing so, is actually to express the intention: this class has not be designed to be a base class, hence it is not allowed to subclass it.
Notice that by default this rule doesn't match public class to avoid matching classes that are intended to be sub-classed by third-party code using your library. If you are developing an application and not a library, just uncomment the clause !t.IsPubliclyVisible.
How to Fix:
For each matched class, take the time to assess if it is really meant to be subclassed. Certainly most matched class will end up being declared as sealed.
Overrides of Method() should call base.Method()
Typically overrides of a base method, should refine or complete the behavior of the base method. If the base method is not called, the base behavior is not refined but it is replaced.
Violations of this rule are a sign of design flaw, especially if the actual design provides valid reasons that advocates that the base behavior must be replaced and not refined.
How to Fix:
You should investigate if inheritance is the right choice to bind the base class implementation with the derived classes implementations. Does presenting the method with polymorphic behavior through an interface, would be a better design choice?
In such situation, often using the design pattern template method http://en.wikipedia.org/wiki/Template_method_pattern might help improving the design.
Do not hide base class methods
Method hiding is when a base class defines non-virtual method M(), and a derived class has also a method M() with the same signature. In such situation, calling base.M() does something different than calling derived.M().
Notice that this is not polymorphic behavior. With polymorphic behavior, calling both base.M() and derived.M() on an instance object of derived, invoke the same implementation.
This situation should be avoided because it obviously leads to confusion. This rule warns about all method hiding cases in the code base.
How to Fix:
To fix a violation of this rule, remove or rename the method, or change the parameter signature so that the method does not hide the base method.
However method hiding is for those times when you need to have two things to have the same name but different behavior. This is a very rare situations, described here: https://learn.microsoft.com/en-us/archive/blogs/ericlippert/method-hiding-apologia
A stateless class or structure might be turned into a static type
This rule matches classes and structures that are not static, nor generic, that doesn't have any instance fields, that doesn't implement any interface nor has a base class (different than System.Object).
Such class or structure is a stateless collection of pure functions, that doesn't act on any this object data. Such collection of pure functions is better hosted in a static class. Doing so simplifies the client code that doesn't have to create an object anymore to invoke the pure functions.
How to Fix:
Declare all methods as static and transform the class or structure into a static class.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Non-static classes should be instantiated or turned to static
If the constructors of a class are never called, the class is never instantiated, and should be defined as a static class.
However this rule doesn't match instantiation through reflection. As a consequence, plug-in root classes, instantiated through reflection via IoC frameworks, can be false positives for this rule.
This rule doesn't match also classes instantiated by the ASP.NET infrastructure, ASP.NET view model classes and Entity Framework ModelSnapshot, DbContext and Migration classes.
Notice that by default this rule matches also public class. If you are developing a framework with classes that are intended to be instantiated by your clients, just uncomment the line !t.IsPublic.
How to Fix:
First it is important to investigate why the class is never instantiated. If the reason is the class hosts only static methods then the class can be safely declared as static.
Others reasons like, the class is meant to be instantiated via reflection, or is meant to be instantiated only by client code should lead to adapt this rule code to avoid these matches.
Methods should be declared static if possible
When an instance method can be safely declared as static you should declare it as static.
Whenever you write a method, you fulfill a contract in a given scope. The narrower the scope is, the smaller the chance is that you write a bug.
When a method is static, you can't access non-static members; hence, your scope is narrower. So, if you don't need and will never need (even in subclasses) instance fields to fulfill your contract, why give access to these fields to your method? Declaring the method static in this case will let the compiler check that you don't use members that you do not intend to use.
Declaring a method as static if possible is also good practice because clients can tell from the method signature that calling the method can't alter the object's state.
Doing so, is also a micro performance optimization, since a static method is a bit cheaper to invoke than an instance method, because the this reference* doesn't need anymore to be passed.
Notice that if a matched method is a handler, bound to an event through code generated by a designer, declaring it as static might break the designer generated code, if the generated code use the this invocation syntax, (like this.Method()).
How to Fix:
Declare matched methods as static.
Since such method doesn't use any instance fields and methods of its type and base-types, you should consider if it makes sense, to move such a method to a static utility class.
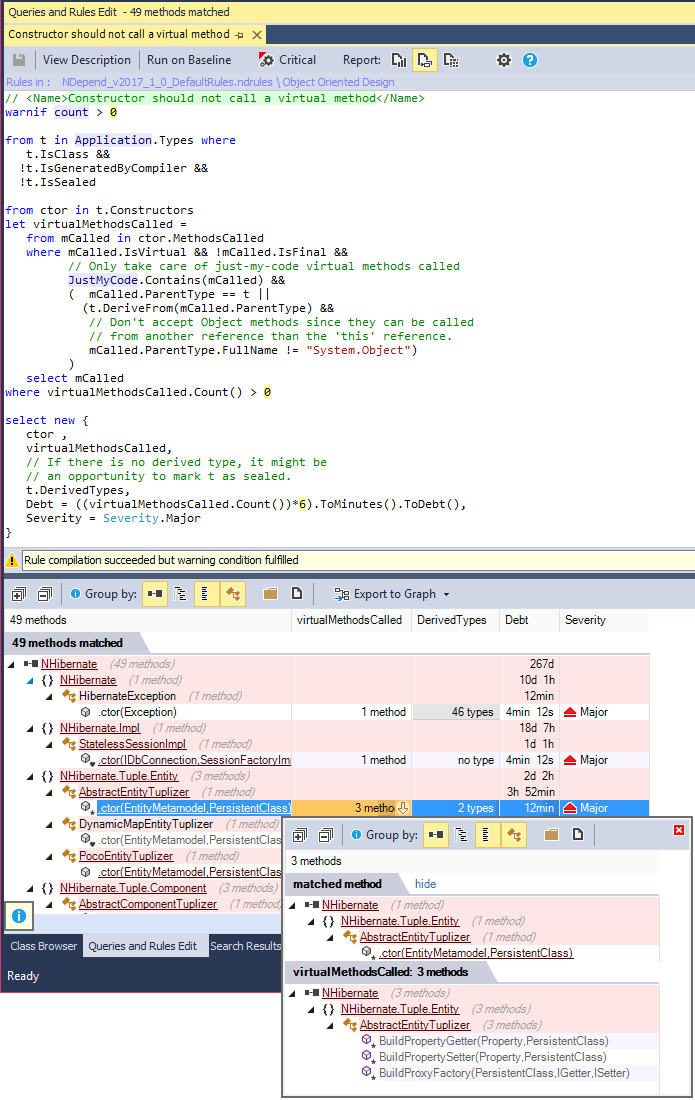
Constructor should not call a virtual method
This rule matches constructors of a non-sealed class that call one or several virtual methods.
During the construction of a .NET object at runtime, constructors execute sequentially, starting from the base class and progressing to the most derived class.
Objects maintain their type throughout construction; they begin as the most derived type with the method table corresponding to that type. Consequently, virtual method calls always execute on the most derived type, even when called from within the constructor.
Combining these two observations leads to the issue that when you invoke a virtual method within a constructor and the current class is not the most derived type in its inheritance hierarchy, the method will execute on a class whose constructor hasn't been executed yet. This may result in an unsuitable state for the method to be called.
Therefore, this situation renders the class error-prone when deriving from it.
How to Fix:
Issues reported can be solved by re-designing object initialisation or by declaring the parent class as sealed, if possible.
A constructor should primarily focus on initializing the state of its own class. Additional setup can be handled in constructors of derived classes or in dedicated methods called after object construction.
Avoid the Singleton pattern
The singleton pattern ensures a class has only one instance during runtime: http://en.wikipedia.org/wiki/Singleton_pattern Initially, this pattern may seem attractive due to its simplicity and applicability to common scenarios, making it widely adopted.
We advise against using singleton classes because they tend to produce code that is less testable and harder to maintain. Singleton, by design, is not conducive to testing, as it enforces the use of the same instance object across multiple unit tests, limiting the flexibility required for effective testing and maintenance.
Additionally, the static Instance getter method of the singleton pattern provides convenient but uncontrolled access to the single object and its state, leading to code that can become disorganized and messy over time, often requiring refactoring efforts.
This rule applies specifically to singleton types with mutable instance fields because the pitfalls of singletons arise from unregulated access and modification of instance data.
More details available in these discussions: https://blog.ndepend.com/the-proper-usages-of-the-keyword-static-in-c/
How to Fix:
This rule pertains to the usual syntax of singletons, where a single static field holds the instance of the parent class. We emphasize that the issue lies in this specific syntax, which hinders testability. The concern is not having a single instance of the class during runtime.
To address matches for this rule, create the single instance at the program's startup and pass it explicitly to all classes and methods requiring access.
When dealing with multiple singletons, consider consolidating them into a single program execution context. This unified context simplifies propagation across various program units.
The estimated Debt, which means the effort to fix such issue, is equal to 3 minutes per method relying on the singleton. It is not rare that hundreds of methods rely on the singleton and that it takes hours to get rid of a singleton, refactoring the way just explained above.
The severity of each singleton issue is Critical because as explained, using a the singleton pattern can really prevent the whole program to be testable and maintained.
Don't assign static fields from instance methods
Assigning static fields from instance methods leads to poorly maintainable and non-thread-safe code.
More discussion on the topic can be found here: https://blog.ndepend.com/the-proper-usages-of-the-keyword-static-in-c/
How to Fix:
If the static field is just assigned once in the program lifetime, make sure to declare it as readonly and assign it inline, or from the static constructor.
In Object-Oriented-Programming the natural artifact to hold states that can be modified is instance fields.
Hence to fix violations of this rule, make sure to hold assignable states through instance fields, not through static fields.
Avoid empty interfaces
Interfaces define members that provide a behavior or usage contract. The functionality that is described by the interface can be adopted by any type, regardless of where the type appears in the inheritance hierarchy. A type implements an interface by providing implementations for the members of the interface. An empty interface does not define any members. Therefore, it does not define a contract that can be implemented.
If your design includes empty interfaces that types are expected to implement, you are probably using an interface as a marker or a way to identify a group of types. If this identification will occur at run time, the correct way to accomplish this is to use a custom attribute. Use the presence or absence of the attribute, or the properties of the attribute, to identify the target types. If the identification must occur at compile time, then it is acceptable to use an empty interface.
Note that if an interface is empty but implements at least one other interface, it won't be matched by this rule. Such interface can be considered as not empty, since implementing it means that sub-interfaces members must be implemented.
How to Fix:
Remove the interface or add members to it. If the empty interface is being used to mark a set of types, replace the interface with a custom attribute.
The estimated Debt, which means the effort to fix such issue, is equal to 10 minutes to discard an empty interface plus 3 minutes per type implementing an empty interface.
Avoid types initialization cycles
The class constructor, also known as the static constructor and labeled as cctor in IL code, is executed by the runtime the first time a type is utilized. A cctor doesn't need to be explicitly declared in source code to exist in compiled IL code. Having a static field inline initialization is enough to have the cctor implicitly declared in the parent class or structure.
If the cctor of a type t1 is using the type t2 and if the cctor of t2 is using t1, some type initialization unexpected and hard-to-diagnose buggy behavior can occur. Such a cyclic chain of initialization is not necessarily limited to two types and can embrace N types in the general case. More information on types initialization cycles can be found here: http://codeblog.jonskeet.uk/2012/04/07/type-initializer-circular-dependencies/
The present code rule enumerates types initialization cycles. Some false positives can appear if some lambda expressions are defined in cctors or in methods called by cctors. In such situation, this rule considers these lambda expressions as executed at type initialization time, while it is not necessarily the case.
How to Fix:
Types initialization cycles create confusion and unexpected behaviors. If several states hold by several classes must be initialized during the first access of any of those classes, a better design option is to create a dedicated class whose responsibility is to initialize and hold all these states.
The estimated Debt, which means the effort to fix such issue, is equal to 20 minutes per cycle plus 10 minutes per type class constructor involved in the cycle.
Avoid custom delegates
Generic delegates should be preferred over custom delegates. Generic delegates are:
• Action<…> to represent any method with void return type.
• Func<…> to represent any method with a return type. The last generic argument is the return type of the prototyped methods.
• Predicate<T> to represent any method that takes an instance of T and that returns a boolean.
• Expression<…> that represents function definitions that can be compiled and subsequently invoked at runtime but can also be serialized and passed to remote processes.
Generic delegates not only enhance the clarity of code that uses them but also alleviate the burden of maintaining these delegate types.
Notice that delegates that are consumed by DllImport extern methods must not be converted, else this could provoke marshalling issues.
How to Fix:
Remove custom delegates and replace them with generic delegates shown in the replaceWith column.
The estimated Debt, which means the effort to fix such issue, is 5 minutes per custom delegates plus 3 minutes per method using such custom delegate.
Types with disposable instance fields must be disposable
This rule warns when a class declares and implements an instance field that whose type implement System.IDisposable or System.IAsyncDisposable and the class does not implement IDisposable.
A class implements the IDisposable interface to dispose of unmanaged resources that it owns. An instance field that is an IDisposable type indicates that the field owns an unmanaged resource. A class that declares an IDisposable field indirectly owns an unmanaged resource and should implement the IDisposable interface. If the class does not directly own any unmanaged resources, it should not implement a finalizer.
This rules might report false positive in case the lifetime of the disposable objects referenced, is longer than the lifetime of the object that hold the disposable references.
How to Fix:
To fix a violation of this rule, implement IDisposable and from the IDisposable.Dispose() method call the Dispose() method of the field(s).
Then for each method calling a constructor of the type, make sure that the Dispose() method is called on all objects created.
The estimated Debt, which means the effort to fix such issue, is 5 minutes per type matched plus 2 minutes per disposable instance field plus 4 minutes per method calling a constructor of the type.
Disposable types with unmanaged resources should declare finalizer
A type that implements System.IDisposable or System.IAsyncDisposable, and has fields that suggest the use of unmanaged resources, does not implement a finalizer as described by Object.Finalize(). A violation of this rule is reported if the disposable type contains fields of the following types:
• System.IntPtr
• System.UIntPtr
• System.Runtime.InteropServices.HandleRef
Notice that this default rule is disabled by default, because it typically reports false positive for classes that just hold some references to managed resources, without the responsibility to dispose them.
To enable this rule just uncomment warnif count > 0.
How to Fix:
To fix a violation of this rule, implement a finalizer that calls your Dispose() method.
Methods that create disposable object(s) and that don't call Dispose()
This code query enumerates methods that create one or several disposable object(s), without calling any Dispose() method.
This code query is not a code rule because it is acceptable to do so, as long as disposable objects are disposed somewhere else.
This code query is designed to be be easily refactored to look after only specific disposable types, or specific caller methods.
You can then refactor this code query to adapt it to your needs and transform it into a code rule.
Disposable Types Must Unsubscribe Events
Detects disposable types that subscribe to events in constructors but do not unsubscribe in Dispose() or any method called by Dispose(). This pattern can keep instances alive through event publisher references and lead to memory leaks or unexpected callbacks.
How to Fix:
1) Ensure each constructor event subscription has a matching unsubscription in Dispose() (or in a method always called by Dispose()). 2) Centralize subscriptions/unsubscriptions in dedicated methods to make symmetry explicit and easier to review. 3) If using inheritance, follow the full dispose pattern so derived types can safely release additional event subscriptions. 4) Prefer weak-event patterns or explicit lifetime ownership when publisher lifetime exceeds subscriber lifetime.
Classes that are candidate to be turned into structures
Int32, Double, Char or Boolean are structures and not classes. Structures are particularly suited to implement lightweight values. Hence a class is candidate to be turned into a structure when its instances are lightweight values.
This is a matter of performance. It is expected that a program works with plenty of short lived lightweight values. In such situation, the advantage of using struct instead of class, (in other words, the advantage of using values instead of objects), is that values are not managed by the garbage collector. This means that values are cheaper to deal with.
This rule matches classes that looks like being lightweight values. The characterization of such class is:
• It has instance fields.
• All instance fields are typed with value-types (primitive, structure or enumeration)
• It is immutable (the value of its instance fields cannot be modified once the constructor ended).
• It implements no interfaces.
• It has no parameterless constructor.
• It is not generic.
• It has no derived classes.
• It derives directly from System.Object.
• ASP.NETCore ViewModel (its name ends with Model) and Repository
This rule doesn't take account if instances of matched classes are numerous short-lived objects. These criteria are just indications. Only you can decide if it is performance wise to transform a class into a structure.
How to Fix:
Just use the keyword struct instead of the keyword class.
CAUTION: Before applying this rule, make sure to understand the deep implications of transforming a class into a structure explained in this article: https://blog.ndepend.com/class-vs-struct-in-c-making-informed-choices/
The estimated Debt, which means the effort to fix such issue, is 5 minutes per class matched plus one minute per method using such class transformed into a structure.
Avoid namespaces with few types
This rule warns about namespaces other than the global namespace that contain less than five types.
Make sure that each of your namespaces has a logical organization and that a valid reason exists to put types in a sparsely populated namespace. Because creating numerous detailed namespaces leads to the need for many using clauses in client code.
Namespaces should contain types that are used together in most scenarios. When their applications are mutually exclusive, types should be located in separate namespaces.
Careful namespace organization can also be helpful because it increases the discoverability of a feature. By examining the namespace hierarchy, library consumers should be able to locate the types that implement a feature.
Notice that this rule source code contains a list of common infrastructure namespace names that you can complete. Namespaces with ending name component in this list are not matched.
How to Fix:
To fix a violation of this rule, try to combine namespaces that contain just a few types into a single namespace.
Nested types should not be visible
This rule warns about nested types not declared as private.
A nested type is a type declared within the scope of another type. Nested types are useful for encapsulating private implementation details of the containing type. Used for this purpose, nested types should not be externally visible.
Do not use externally visible nested types for logical grouping or to avoid name collisions; instead use namespaces.
Nested types include the notion of member accessibility, which some programmers do not understand clearly.
Nested types declared as protected can be used in subclasses.
How to Fix:
If you do not intend the nested type to be externally visible, change the type's accessibility.
Otherwise, remove the nested type from its parent and make it non-nested.
If the purpose of the nesting is to group some nested types, use a namespace to create the hierarchy instead.
The estimated Debt, which means the effort to fix such issue, is 2 minutes per nested type plus 4 minutes per outer type using such nesting type.
Declare types in namespaces
Types are declared within namespaces to prevent name collisions, and as a way of organizing related types in an object hierarchy.
Types outside any named namespace are in a global namespace that cannot be referenced in code. Such practice results in naming collisions and ambiguity since types in the global namespace are accessible from anywhere in the code.
Also, placing types within namespaces allows to encapsulate related code and data, providing a level of abstraction and modularity. Global types lack this encapsulation, making it harder to understand the organization and structure of your code.
The global namespace has no name, hence it is qualified as being the anonymous namespace. This rule warns about anonymous namespaces.
How to Fix:
To fix a violation of this rule, declare all types of all anonymous namespaces in some named namespaces.
Empty static constructor can be discarded
The class constructor (also called static constructor, and named cctor in IL code) of a type, if any, is executed by the CLR at runtime, just before the first time the type is used.
This rule warns about the declarations of static constructors that don't contain any lines of code. Such cctors are useless and can be safely removed.
How to Fix:
Remove matched empty static constructors.
Instances size shouldn't be too big
Types where SizeOfInst > 128 might degrade performance if many instances are created at runtime. They can also be hard to maintain.
Notice that a class with a large SizeOfInst value doesn't necessarily have a lot of instance fields. It might derive from a class with a large SizeOfInst value.
This query doesn't match types that represent WPF and WindowsForm forms and controls nor Entity Framework special classes.
Some other namespaces like System.ComponentModel or System.Xml have base classes that typically imply large instances size so this rule doesn't match these situations.
This rule doesn't match custom DevExpress component and it is easy to modify this rule ro append other component vendors to avoid false positives.
See the definition of the SizeOfInst metric here https://www.ndepend.com/docs/code-metrics#SizeOfInst
How to Fix:
A type with a large SizeOfInst value hold directly a lot of data. Typically, you can group this data into smaller types that can then be composed.
The estimated Debt, which means the effort to fix such issue, varies linearly from severity Medium for 128 bytes per instance to twice interests for severity High for 2048 bytes per instance.
The estimated annual interest of issues of this rule is 10 times higher for structures, because large structures have a significant performance cost. Indeed, each time such structure value is passed as a method parameter it gets copied to a new local variable (note that the word value is more appropriate than the word instance for structures). For this reason, such structure should be declared as class.
Attribute classes should be sealed
.NET offers methods to fetch custom attributes. By default, these methods explore the attribute inheritance hierarchy. For instance, the System.Attribute.GetCustomAttribute() method scans for the specified attribute type or any attribute type that inherits from it. If the attribute is sealed, this removes the search within the inheritance hierarchy, potentially enhancing performance.
Sealing the attribute removes the need to search through the inheritance hierarchy, which can result in performance improvements.
How to Fix:
To fix a violation of this rule, seal the attribute type or make it abstract.
Don't use obsolete types, methods or fields
The attribute System.ObsoleteAttribute is used to tag types, methods, fields, properties or events of an API that clients shouldn't use because these code elements will be removed sooner or later.
This rule warns about methods that use a type, a method or a field, tagged with System.ObsoleteAttribute.
How to Fix:
Typically when a code element is tagged with System.ObsoleteAttribute, a workaround message is provided to clients.
This workaround message will tell you what to do to avoid using the obsolete code element.
The estimated Debt, which means the effort to fix such issue, is 5 minutes per type, method or field used.
Issues of this rule have a severity High because it is important to not rely anymore on obsolete code.
Do implement methods that throw NotImplementedException
This rule warns about method using NotImplementedException.
The exception NotImplementedException is used to declare a method stub that can be invoked, and defer the development of the method implementation.
This exception is especially useful when doing TDD (Test Driven Development) when tests are written first. This way tests fail until the implementation is written.
Hence using NotImplementedException is a temporary facility, and before releasing, will come a time when this exception shouldn't be used anywhere in code.
NotImplementedException should not be used permanently to mean something like this method should be overriden or this implementation doesn't support this facility. Artefact like abstract method or abstract class should be used instead, to favor a compile time error over a run-time error.
How to Fix:
Investigate why NotImplementedException is still thrown.
Such issue has a High severity if the method code consists only in throwing NotImplementedException. Such situation means either that the method should be implemented, either that what should be a compile time error is a run-time error by-design, and this is not good design. Sometime this situation also pinpoints a method stub that can be safely removed.
If NotImplementedException is thrown from a method with significant logic, the severity is considered as Medium, because often the fix consists in throwing another exception type, like InvalidOperationException.
Override equals and operator equals on value types
For value types, the inherited implementation of Equals() uses the Reflection library, and compares the contents of all instances fields. Reflection is computationally expensive, and comparing every field for equality might be unnecessary.
If you expect users to compare or sort instances, or use them as hash table keys, your value type should implement Equals(). In C# and VB.NET, you should also provide an implementation of GetHashCode() and of the equality and inequality operators.
How to Fix:
To fix a violation of this rule, provide an implementation of Equals() and GetHashCode() and implement the equality and inequality operators. Alternatively transform it into a record struct.
The estimated Debt, which means the effort to fix such issue, is equal to 15 minutes plus 2 minutes per instance field.
Boxing/unboxing should be avoided
Boxing is the process of converting a value type to the type object or to any interface type implemented by this value type. When the CLR boxes a value type, it wraps the value inside a System.Object and stores it on the managed heap.
Unboxing extracts the value type from the object. Boxing is implicit; unboxing is explicit.
The concept of boxing and unboxing underlies the C# unified view of the type system in which a value of any type can be treated as an object. More about boxing and unboxing here: https://msdn.microsoft.com/en-us/library/yz2be5wk.aspx
This rule has been disabled by default to avoid noise in issues found by the NDepend default rule set. If boxing/unboxing is important to your team, just re-activate this rule.
How to Fix:
Thanks to .NET generic, and especially thanks to generic collections, boxing and unboxing should be rarely used. Hence in most situations the code can be refactored to avoid relying on boxing and unboxing. See for example: http://stackoverflow.com/questions/4403055/boxing-unboxing-and-generics
With a performance profiler, indentify methods that consume a lot of CPU time. If such method uses boxing or unboxing, especially in a loop, make sure to refactor it.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Avoid namespaces mutually dependent
This rule lists types and methods from a low-level namespace that use types and methods from higher-level namespace.
The pair of low and high level namespaces is made of two namespaces that use each other.
For each pair of namespaces, to infer which one is low-level and which one is high-level, the rule computes the two coupling [from A to B] and [from B to A] in terms of number of types, methods and fields involved in the coupling. Typically the coupling from low-level to high-level namespace is significantly lower than the other legitimate coupling.
Following this rule is useful to avoid namespaces dependency cycles. This will get the code architecture close to a layered architecture, where low-level code is not allowed to use high-level code.
In other words, abiding by this rule will help significantly getting rid of what is often called spaghetti code: Entangled code that is not properly layered and structured.
More on this in our white books relative to partitioning code. https://www.ndepend.com/docs/white-books
How to Fix:
Refactor the code to make sure that the low-level namespace doesn't use the high-level namespace.
The rule lists in detail which low-level types and methods shouldn't use which high-level types and methods. The refactoring patterns that help getting rid of each listed dependency include:
• Moving one or several types from the low-level namespaces to the high-level one, or do the opposite.
• Use Dependency Inversion Principle (DIP): https://blog.ndepend.com/solid-design-the-dependency-inversion-principle-dip This consists in creating new interfaces in the low-level namespace, implemented by classes in the high-level namespace. This way low-level code can consume high-level code through interfaces, without using directly high-level implementations. Interfaces can be passed to low-level code through the high-level namespace code, or through even higher-level code. In related documentations you can see these interfaces named as callbacks, and the overall pattern is also known as Dependency Injection (DI): http://en.wikipedia.org/wiki/Dependency_injection
That rule might not be applicable for libraries that present public namespaces mutually dependent. In such situation the cost to break the API can be higher than the cost to let the code entangled.
-
The estimated Debt, which means the effort to fix such issue to make sure that the first namespace doesn't rely anymore on the second one, depends on the number of types and methods used.
Because both namespace are now forming a super-component that cannot be partitioned in smaller components, the cost to unfix each issue is proportional to the size of this super-component. As a consequence, the estimated Annual Interest, which means the annual cost to let both namespaces mutually dependend, is equal to an hour plus a number of minutes proportional to the size (in lines of code) of both namespaces. The obtained Annual Interest value is then divided by the number of detailled issues listed.
Often the estimated Annual Interest for each listed issue is higher than the Debt, which means that leaving such issue unfixed for a year costs more than taking the time to fix issue once.
--
To explore the coupling between the two namespaces mutually dependent:
1) from the becauseNamespace right-click menu choose Copy to Matrix Columns to export this low-level namespace to the horizontal header of the dependency matrix.
2) from the shouldntUseNamespace right-click menu choose Copy to Matrix Rows to export this high-level namespace to the vertical header of the dependency matrix.
3) double-click the black matrix cell (it is black because of the mutual dependency).
4) in the matrix command bar, click the button: Remove empty Row(s) and Column(s).
At this point, the dependency matrix shows types involved into the coupling.
• Blue cells represent types from low-level namespace using types from high-level namespace
• Green cells represent types from high-level namespace using types from low-level namespace
• Black cells represent types from low-level and high-level namespaces that use each other.
There are more green cells than blue and black cells because green cell represents correct coupling from high-level to low-level. The goal is to eliminate incorrect dependencies represented by blue and black cells.
Avoid namespaces dependency cycles
This rule lists all application namespace dependency cycles. Each row shows a different cycle, indexed with one of the namespace entangled in the cycle.
Read our white books relative to partitioning code, to know more about namespaces dependency cycles, and why avoiding them is a simple yet efficient solution to clean the architecture of a code base. https://www.ndepend.com/docs/white-books
How to Fix:
Removing first pairs of mutually dependent namespaces will eliminate most namespaces dependency cycles. This is why it is recommended to focus first on matches of the default rule Avoid namespaces mutually dependent before attempting to fix issues of the present rule.
Once all mutually dependent namespaces occurrences are solved, remaining cycles matched by the present rule necessarily involve 3 or more namespaces like in: A is using B is using C is using A.
To browse a cycle on the dependency graph or the dependency matrix, right click a cycle cell in the result of the present rule and export the matched namespaces to the dependency graph or matrix. This is illustrated here: https://www.ndepend.com/docs/visual-studio-dependency-graph#Entangled
With such a cycle graph visualized, you can determine which dependencies should be discarded to break the cycle. To do so, you need to identify which namespace should be at low-level and which one should be at high-level.
In the A is using B is using C is using A cycle example, if A should be at low level then C should be at a higher-level than A. As a consequence C shouldn't use A and this dependency should be removed. To remove a dependency you can refer to patterns described in the HowToFix section of the rule Avoid namespaces mutually dependent.
Notice that the dependency matrix can also help visualizing and breaking cycles. In the matrix cycles are represented with red squares and black cells. To easily browse dependency cycles, the dependency matrix comes with an option: Display Direct and Indirect Dependencies. See related documentation here: https://www.ndepend.com/docs/dependency-structure-matrix-dsm#Cycle https://www.ndepend.com/docs/dependency-structure-matrix-dsm#Mutual
The estimated Debt, which means the effort to fix such issue, doesn't depend on the cycle length. First because fixing the rule Avoid namespaces mutually dependent will fix most cycle reported here, second because even a long cycle can be broken by removing a single or a few dependencies.
Avoid partitioning the code base through many small library Assemblies
This rule matches assemblies that contain 3 or less types.
Each compiled assembly represents a DLL file and a project to maintain. Having too many library assemblies is a symptom of considering physical projects as logical components.
We advise having less, and bigger, projects and using the concept of namespaces to define logical components. Benefits are:
• Faster compilation time.
• Faster startup time for your program.
• Clearer Solution Explorer at development time.
• Easier deployment thanks to less files to manage.
• If you are developing a library, less assemblies to reference and manage for your clients.
How to Fix:
Consider using the physical concept of assemblies for physical needs only.
Our white book about Partitioning code base through .NET assemblies and Visual Studio projects explains in details valid and invalid reasons to use assemblies. Download it here: https://www.ndepend.com/Res/NDependWhiteBook_Assembly.pdf
Enforcing Clean Architecture
Ensures strict inward dependency flow between architectural layers. Allowed direction is only from outer layers to inner layers: Presentation -> Application -> Domain. This rule flags any forbidden dependency that points outward or sideways (for example Domain -> Infrastructure or Application -> Presentation).
How to Fix:
1) Move business rules used by multiple layers into Domain or Application. 2) Replace direct references to outer layers with abstractions (interfaces) defined in an inner layer. 3) Implement those abstractions in Infrastructure/Presentation and inject them from the composition root. 4) Move DTOs/view models to the boundary layer that owns them, and map at layer boundaries instead of sharing concrete outer-layer types.
UI layer shouldn't use directly DB types
This rule is more a sample rule to adapt to your need, than a rigid rule you should abide by. It shows how to define code layers in a rule and how to be warned about layers dependencies violations.
This rule first defines the UI layer and the DB framework layer. Second it checks if any UI layer type is using directly any DB framework layer type.
• The DB framework layer is defined as the set of third-party types in the framework ADO.NET, EntityFramework, NHibernate types, that the application is consuming. It is easy to append and suppress any DB framework.
• The UI layer (User Interface Layer) is defined as the set of types that use WPF, Windows Form, ASP.NET.
UI using directly DB frameworks is generally considered as poor design because DB frameworks accesses should be a concept hidden to UI, encapsulated into a dedicated Data Access Layer (DAL).
Notice that per defaut this rule estimates a technical debt proportional to the coupling between the UI and DB types.
How to Fix:
This rule lists precisely which UI type uses which DB framework type. Instead of fixing matches one by one, first imagine how DB framework accesses could be encapsulated into a dedicated layer.
UI layer shouldn't use directly DAL layer
This rule is more a sample rule to adapt to your need, than a rigid rule you should abide by. It shows how to define code layers in a rule and how to be warned about layers dependencies violations.
This rule first defines the UI layer and the DAL layer. Second it checks if any UI layer type is using directly any DAL layer type.
• The DB layer (the DAL, Data Access Layer) is defined as the set of types of the application that use ADO.NET, EntityFramework, NHibernate types. It is easy to append and suppress any DB framework.
• The UI layer (User Interface Layer) is defined as the set of types that use WPF, Windows Form, ASP.NET.
UI using directly DAL is generally considered as poor design because DAL accesses should be a concept hidden to UI, encapsulated into an intermediary domain logic.
Notice that per defaut this rule estimates a technical debt proportional to the coupling between the UI with the DAL layer.
How to Fix:
This rule lists precisely which UI type uses which DAL type.
More about this particular design topic here: http://www.kenneth-truyers.net/2013/05/12/the-n-layer-myth-and-basic-dependency-injection/
Assemblies with poor cohesion (RelationalCohesion)
This rule computes the Relational Cohesion metric for the application assemblies, and warns about wrong values.
The Relational Cohesion for an assembly, is the total number of relationship between types of the assemblies, divided by the number of types. In other words it is the average number of types in the assembly used by a type in the assembly.
As classes inside an assembly should be strongly related, the cohesion should be high.
Notice that assemblies with less than 20 types are ignored.
How to Fix:
Matches of this present rule might reveal either assemblies with specific coding constraints (like code generated that have particular structure) either issues in design.
In the second case, large refactoring can be planned not to respect this rule in particular, but to increase the overall design and code maintainability.
The severity of issues of this rule is Low because the code metric Relational Cohesion is an information about the code structure state but is not actionable, it doesn't tell precisely what to do obtain a better score.
Fixing actionable issues of others Architecture and Code Smells default rules will necessarily increase the Relational Cohesion scores.
Namespaces with poor cohesion (RelationalCohesion)
This rule computes the Relational Cohesion metric for the application namespaces, and warns about wrong values.
The Relational Cohesion for a namespace, is the total number of relationship between types of the namespaces, divided by the number of types. In other words it is the average number of types in the namespace used by a type in the namespace.
As classes inside an assembly should be strongly related, the cohesion should be high.
Notice that namespaces with less than 20 types are ignored.
How to Fix:
Matches of this present rule might reveal either namespaces with specific coding constraints (like code generated that have particular structure) either issues in design.
In the second case, refactoring sessions can be planned to increase the overall design and code maintainability.
You can get an overview of class coupling for a matched namespace by exporting the ChildTypes to the graph. (Right click the ChildTypes cells)
The severity of issues of this rule is Low because the code metric Relational Cohesion is an information about the code structure state but is not actionable, it doesn't tell precisely what to do obtain a better score.
Fixing actionable issues of others Architecture and Code Smells default rules will necessarily increase the Relational Cohesion scores.
Assemblies that don't satisfy the Abstractness/Instability principle
The Abstractness versus Instability Diagram that is shown in the NDepend report helps to assess which assemblies are potentially painful to maintain (i.e concrete and stable) and which assemblies are potentially useless (i.e abstract and instable).
• Abstractness: If an assembly contains many abstract types (i.e interfaces and abstract classes) and few concrete types, it is considered as abstract.
• Stability: An assembly is considered stable if its types are used by a lot of types from other assemblies. In this context stable means painful to modify.
From these metrics, we define the perpendicular normalized distance of an assembly from the idealized line A + I = 1 (called main sequence). This metric is an indicator of the assembly's balance between abstractness and stability. We precise that the word normalized means that the range of values is [0.0 … 1.0].
This rule warns about assemblies with a normalized distance greater than than 0.7.
This rules use the default code metric on assembly Normalized Distance from the Main Sequence explained here: https://www.ndepend.com/docs/code-metrics#DitFromMainSeq
These concepts have been originally introduced by Robert C. Martin in 1994 in this paper: http://www.objectmentor.com/resources/articles/oodmetrc.pdf
How to Fix:
Violations of this rule indicate assemblies with an improper abstractness / stability balance.
• Either the assembly is potentially painful to maintain (i.e is massively used and contains mostly concrete types). This can be fixed by creating abstractions to avoid too high coupling with concrete implementations.
• Either the assembly is potentially useless (i.e contains mostly abstractions and is not used enough). In such situation, the design must be reviewed to see if it can be enhanced.
The severity of issues of this rule is Low because the Abstractness/Instability principle is an information about the code structure state but is not actionable, it doesn't tell precisely what to do obtain a better score.
Fixing actionable issues of others Architecture and Code Smells default rules will necessarily push the Abstractness/Instability principle scores in the right direction.
Avoid excessive class coupling
This rule assesses class coupling for types and methods by counting the unique application types they consume and the number of namespaces those types belong to.
High class coupling suggests that the type or the method may be handling too many responsibilities and thus, violates The Single Responsibility Principle explained here:
https://blog.ndepend.com/solid-design-the-single-responsibility-principle-srp/
How to Fix:
To address this issue, refactor the type or method by breaking it into smaller, more focused components that each follow a single responsibility.
Higher cohesion - lower coupling
It is deemed as a good software architecture practice to clearly separate abstract namespaces that contain only abstractions (interfaces, enumerations, delegates) from concrete namespaces, that contain classes and structures.
Typically, the more concrete namespaces rely on abstract namespaces only, the more Decoupled is the architecture, and the more Cohesive are classes inside concrete namespaces.
The present code query defines sets of abstract and concrete namespaces and show for each concrete namespaces, which concrete and abstract namespaces are used.
How to Fix:
This query can be transformed into a code rule, depending if you wish to constraint your code structure coupling / cohesion ratio.
Avoid mutually-dependent types
This rule matches pairs of classes or structures that use each others.
In this situation both types are not isolated: each type cannot be reviewed, refactored or tested without the other one.
This rule is disabled by default because there are some common situations, like when implementing recursive data structures, complex serialization or using the visitor pattern, where having mutually dependent types is legitimate. Just enable this rule if you wish to fix most of its issues.
How to Fix:
Fixing mutually-dependent types means identifying the unwanted dependency (t1 using t2, or t2 using t1) and then removing this dependency.
Often you'll have to use the dependency inversion principle by creating one or several interfaces dedicated to abstract one implementation from the other one: https://blog.ndepend.com/solid-design-the-dependency-inversion-principle-dip
Example of custom rule to check for dependency
This rule is a sample rule that shows how to check if a particular dependency exists or not, from a code element A to a code element B, A and B being an Assembly, a Namespace, a Type, a Method or a Field, A and B being not necessarily of same kind (i.e two Assemblies or two Namespaces…).
Such rule can be generated:
• by right clicking the cell in the Dependency Matrix with B in row and A in column,
• or by right-clicking the concerned arrow in the Dependency Graph from A to B,
and in both cases, click the menu Generate a code rule that warns if this dependency exists
The generated rule will look like this one. It is now up to you to adapt this rule to check exactly your needs.
How to Fix:
This is a sample rule there is nothing to fix as is.
API Breaking Changes: Types
This rule is executed only if a baseline for comparison is defined (diff mode).
This rule warns if a type publicly visible in the baseline, is not publicly visible anymore or if it has been removed. Clients code using such type will be broken.
How to Fix:
Make sure that public types that used to be presented to clients, still remain public now, and in the future.
If a public type must really be removed, you can tag it with System.ObsoleteAttribute with a workaround message during a few public releases, until it gets removed definitely. Notice that this rule doesn't match types removed that were tagged as obsolete.
Issues of this rule have a severity equal to High because an API Breaking change can provoque significant friction with consumers of the API.
API Breaking Changes: Methods
This rule is executed only if a baseline for comparison is defined (diff mode).
This rule warns if a method publicly visible in the baseline, is not publicly visible anymore or if it has been removed. Clients code using such method will be broken.
How to Fix:
Make sure that public methods that used to be presented to clients, still remain public now, and in the future.
If a public method must really be removed, you can tag it with System.ObsoleteAttribute with a workaround message during a few public releases, until it gets removed definitely. Notice that this rule doesn't match methods removed that were tagged as obsolete.
Issues of this rule have a severity equal to High because an API Breaking change can provoque significant friction with consumers of the API.
API Breaking Changes: Fields
This rule is executed only if a baseline for comparison is defined (diff mode).
This rule warns if a field publicly visible in the baseline, is not publicly visible anymore or if it has been removed. Clients code using such field will be broken.
How to Fix:
Make sure that public fields that used to be presented to clients, still remain public now, and in the future.
If a public field must really be removed, you can tag it with System.ObsoleteAttribute with a workaround message during a few public releases, until it gets removed definitely. Notice that this rule doesn't match fields removed that were tagged as obsolete.
Issues of this rule have a severity equal to High because an API Breaking change can provoque significant friction with consumers of the API.
API Breaking Changes: Interfaces and Abstract Classes
This rule is executed only if a baseline for comparison is defined (diff mode).
This rule warns if a publicly visible interface or abstract class has been changed and contains new abstract methods or if some abstract methods have been removed.
Clients code that implement such interface or derive from such abstract class will be broken.
How to Fix:
Make sure that the public contracts of interfaces and abstract classes that used to be presented to clients, remain stable now, and in the future.
If a public contract must really be changed, you can tag abstract methods that will be removed with System.ObsoleteAttribute with a workaround message during a few public releases, until it gets removed definitely.
Issues of this rule have a severity equal to High because an API Breaking change can provoque significant friction with consummers of the API. The severity is not set to Critical because an interface is not necessarily meant to be implemented by the consummer of the API.
Broken serializable types
This rule is executed only if a baseline for comparison is defined (diff mode).
This rule warns about breaking changes in types tagged with SerializableAttribute.
To do so, this rule searches for serializable type with serializable instance fields added or removed. Notice that it doesn't take account of fields tagged with NonSerializedAttribute.
From http://msdn.microsoft.com/library/system.serializableattribute.aspx : "All the public and private fields in a type that are marked by the SerializableAttribute are serialized by default, unless the type implements the ISerializable interface to override the serialization process. The default serialization process excludes fields that are marked with the NonSerializedAttribute attribute."
How to Fix:
Make sure that the serialization process of serializable types remains stable now, and in the future.
Else you'll have to deal with Version Tolerant Serialization that is explained here: https://msdn.microsoft.com/en-us/library/ms229752(v=vs.110).aspx
Issues of this rule have a severity equal to High because an API Breaking change can provoque significant friction with consummers of the API.
Avoid changing enumerations Flags status
This rule is executed only if a baseline for comparison is defined (diff mode).
This rule matches enumeration types that used to be tagged with FlagsAttribute in the baseline, and not anymore. It also matches the opposite, enumeration types that are now tagged with FlagsAttribute, and were not tagged in the baseline.
Being tagged with FlagsAttribute is a strong property for an enumeration. Not so much in terms of behavior (only the enum.ToString() method behavior changes when an enumeration is tagged with FlagsAttribute) but in terms of meaning: is the enumeration a range of values or a range of flags?
As a consequence, changing the FlagsAttributes status of an enumeration can have significant impact for its clients.
How to Fix:
Make sure the FlagsAttribute status of each enumeration remains stable now, and in the future.
API: New publicly visible types
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists types that are new in the public surface of the analyzed assemblies.
API: New publicly visible methods
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists methods that are new in the public surface of the analyzed assemblies.
API: New publicly visible fields
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists fields that are new in the public surface of the analyzed assemblies.
Code should be tested
This rule lists methods not covered at all by test or partially covered by tests. When a type is 0% covered by tested, the type is matched instead of all its methods to reduce the number of issues.
For each match, the rules estimates the technical debt, i.e the effort to write unit and integration tests for the method. The estimation is based on the effort to develop the code element multiplied by factors in the range ]0,1.3] based on
• the method code size and complexity
• the actual percentage coverage
• the abstractness of types used, because relying on classes instead of interfaces makes the code more difficult to test
• the method visibility because testing private or protected methods is more difficult than testing public and internal ones
• the fields used by the method, because is is more complicated to write tests for methods that read mutable static fields whose changing state is shared across tests executions.
• whether the method is considered JustMyCode or not because NotMyCode is often generated easier to get tested since tests can be generated as well.
This rule is necessarily a large source of technical debt, since the code left untested is by definition part of the technical debt.
This rule also estimates the annual interest, i.e the annual cost to let the code uncovered, based on the effort to develop the code element, multiplied by factors based on usage of the code element.
When methods are aggregated within their parent type, the estimated debt and annual interest is aggregated as well.
How to Fix:
Write unit tests to test and cover the methods and their parent types matched by this rule.
New Types and Methods should be tested
This rule is executed only if a baseline for comparison is defined (diff mode). This rule operates only on types and methods added or refactored since the baseline.
This rule is executed only if some code coverage data is imported from some code coverage files.
It is important to write code mostly covered by tests to achieve maintainable and non-error-prone code.
In real-world, many code bases are poorly covered by tests. However it is not practicable to stop the development for months to refactor and write tests to achieve high code coverage ratio.
Hence it is recommended that each time a method (or a type) gets added, the developer takes the time to write associated unit-tests to cover it.
Doing so will help to increase significantly the maintainability of the code base. You'll notice that quickly, refactoring will also be driven by testability, and as a consequence, the overall code structure and design will increase as well.
Issues of this rule have a High severity because they reflect an actual trend to not care about writing tests on refactored code.
How to Fix:
Write unit-tests to cover the code of most methods and types added since the baseline.
Methods refactored should be tested
This rule is executed only if a baseline for comparison is defined (diff mode). This rule operates only on methods added or refactored since the baseline.
This rule is executed only if some code coverage data is imported from some code coverage files.
It is important to write code mostly covered by tests to achieve maintainable and non-error-prone code.
In real-world, many code bases are poorly covered by tests. However it is not practicable to stop the development for months to refactor and write tests to achieve high code coverage ratio.
Hence it is recommended that each time a method (or a type) gets refactored, the developer takes the time to write associated unit-tests to cover it.
Doing so will help to increase significantly the maintainability of the code base. You'll notice that quickly, refactoring will also be driven by testability, and as a consequence, the overall code structure and design will increase as well.
Issues of this rule have a High severity because they reflect an actual trend to not care about writing tests on refactored code.
How to Fix:
Write unit-tests to cover the code of most methods and classes refactored.
Assemblies and Namespaces should be tested
This rule lists assemblies and namespaces that are not covered at all by unit tests.
If an assembly is matched its children namespaces are not matched.
This rule goal is not to collide with the Code should be tested rule that lists uncovered code for each method and infer the effort to write unit tests (the Debt) and the annual cost to let the code untested (the Annual Interest).
This rule goal is to inform of large code elements left untested. As a consequence the Debt per issue is only 4 minutes and the severity of the issues is Low.
How to Fix:
Write unit and integration tests to cover, even partially, code elements matched by this rule.
Then use issues of the rules Code should be tested, New Types and Methods should be tested and Methods refactored should be tested to write more tests where it matters most, and eventually refactor some code to make it more testable.
Types almost 100% tested should be 100% tested
This rule is executed only if some code coverage data is imported from some code coverage files.
Often covering the few percents of remaining uncovered code of a class, requires as much work as covering the first 90%. For this reason, often teams estimate that 90% coverage is enough. However untestable code usually means poorly written code which usually leads to error prone code. So it might be worth refactoring and making sure to cover the few uncovered lines of code because most tricky bugs might come from this small portion of hard-to-test code.
Not all classes should be 100% covered by tests (like UI code can be hard to test) but you should make sure that most of the logic of your application is defined in some easy-to-test classes, 100% covered by tests.
Issues of this rule have a High severity because as explained, such situation is bug-prone.
How to Fix:
Write more unit-tests dedicated to cover code not covered yet. If you find some hard-to-test code, it is certainly a sign that this code is not well designed and hence, needs refactoring.
Namespaces almost 100% tested should be 100% tested
This rule is executed only if some code coverage data is imported from some code coverage files.
Often covering the few percents of remaining uncovered code of one or several classes in a namespace requires as much work as covering the first 90%. For this reason, often teams estimate that 90% coverage is enough. However untestable code usually means poorly written code which usually leads to error prone code. So it might be worth refactoring and making sure to cover the few uncovered lines of code because most tricky bugs might come from this small portion of hard-to-test code.
Not all classes should be 100% covered by tests (like UI code can be hard to test) but you should make sure that most of the logic of your application is defined in some easy-to-test classes, 100% covered by tests.
Issues of this rule have a High severity because as explained, such situation is bug-prone.
How to Fix:
Write more unit-tests dedicated to cover code not covered yet in the namespace. If you find some hard-to-test code, it is certainly a sign that this code is not well designed and hence, needs refactoring.
Types that used to be 100% covered by tests should still be 100% covered
This rule is executed only if a baseline for comparison is defined (diff mode).
This rule is executed only if some code coverage data is imported from some code coverage files.
Often covering 10% of remaining uncovered code of a class, requires as much work as covering the first 90%. For this reason, typically teams estimate that 90% coverage is enough. However untestable code usually means poorly written code which usually leads to error prone code. So it might be worth refactoring and making sure to cover the 10% remaining code because most tricky bugs might come from this small portion of hard-to-test code.
Not all classes should be 100% covered by tests (like UI code can be hard to test) but you should make sure that most of the logic of your application is defined in some easy-to-test classes, 100% covered by tests.
In this context, this rule warns when a type fully covered by tests is now only partially covered.
Issues of this rule have a High severity because often, a type that used to be 100% and is not covered anymore is a bug-prone situation that should be carefully handled.
How to Fix:
Write more unit-tests dedicated to cover code not covered anymore. If you find some hard-to-test code, it is certainly a sign that this code is not well designed and hence, needs refactoring.
You'll find code impossible to cover by unit-tests, like calls to MessageBox.Show(). An infrastructure must be defined to be able to mock such code at test-time.
Types tagged with FullCoveredAttribute should be 100% covered
This rule lists methods partially covered by tests, of types tagged with FullCoveredAttribute.
This rule is executed only if some code coverage data is imported from some code coverage files.
By using a FullCoveredAttribute, you can express in source code the intention that a class is 100% covered by tests, and should remain 100% covered in the future. If you don't want to link NDepend.API.dll, you can use your own attribute and adapt the source code of this rule.
Benefits of using a FullCoveredAttribute are twofold: Not only the intention is expressed in source code, but it is also continuously checked by the present rule.
Often covering 10% of remaining uncovered code of a class, requires as much work as covering the first 90%. For this reason, often teams estimate that 90% coverage is enough. However untestable code usually means poorly written code which usually means error prone code. So it might be worth refactoring and making sure to cover the 10% remaining code because most tricky bugs might come from this small portion of hard-to-test code.
Not all classes should be 100% covered by tests (like UI code can be hard to test) but you should make sure that most of the logic of your application is defined in some easy-to-test classes, 100% covered by tests.
Issues of this rule have a High severity because often, a type that used to be 100% and is not covered anymore is a bug-prone situation that should be carefully handled.
How to Fix:
Write more unit-tests dedicated to cover code of matched classes not covered yet. If you find some hard-to-test code, it is certainly a sign that this code is not well designed and hence, needs refactoring.
Types 100% covered should be tagged with FullCoveredAttribute
This rule is executed only if some code coverage data is imported from some code coverage files.
By using an attribute class named FullCoveredAttribute, you can express in source code the intention that a class is 100% covered by tests, and should remain 100% covered in the future.
Benefits of using a FullCoveredAttribute are twofold: Not only the intention is expressed in source code, but it is also continuously checked by the rule Types tagged with FullCoveredAttribute should be 100% covered.
Issues of this rule have an Low severity because they don't reflect a problem, but provide an advice for potential improvement.
How to Fix:
Just tag types 100% covered by tests with the FullCoveredAttribute class that can be found in NDepend.API.dll, or by an attribute of yours with this name defined in any namespace in your own code.
Methods should have a low C.R.A.P score
This rule is executed only if some code coverage data is imported from some code coverage files.
So far this rule is disabled because other code coverage rules assess properly code coverage issues.
Change Risk Analyzer and Predictor (i.e. CRAP) is a code metric that helps in pinpointing overly both complex and untested code. Is has been first defined here: http://www.artima.com/weblogs/viewpost.jsp?thread=215899
The Formula is: CRAP(m) = CC(m)^2 * (1 – cov(m)/100)^3 + CC(m)
• where CC(m) is the cyclomatic complexity of the method m
• and cov(m) is the percentage coverage by tests of the method m
Matched methods cumulates two highly error prone code smells:
• A complex method, difficult to develop and maintain.
• Non 100% covered code, difficult to refactor without introducing any regression bug.
The higher the CRAP score, the more painful to maintain and error prone is the method.
An arbitrary threshold of 30 is fixed for this code rule as suggested by inventors.
Notice that no amount of testing will keep methods with a Cyclomatic Complexity higher than 30, out of CRAP territory.
Notice that this rule doesn't match too short method with less than 10 lines of code.
How to Fix:
In such situation, it is recommended to both refactor the complex method logic into several smaller and less complex methods (that might belong to some new types especially created), and also write unit-tests to full cover the refactored logic.
You'll find code impossible to cover by unit-tests, like calls to MessageBox.Show(). An infrastructure must be defined to be able to mock such code at test-time.
Complex Methods should be 100% tested
This rule detects methods with a low maintainability index and insufficient test coverage. Such code is hard to understand, error prone and risky to modify. Refactoring and adding tests will improve reliability, readability, and long-term maintainability.
See the maintainability index definition here: https://www.ndepend.com/docs/code-metrics#MaintainabilityIndex
How to Fix:
1. Simplify the code by breaking down large or complex methods into smaller, focused units.
2. Improve readability with clear naming, consistent formatting, and reduced nesting.
3. Increase test coverage by writing unit tests that validate both common and edge cases.
4. Ensure all refactored code is fully covered by tests before merging.
Test Methods
We advise to not include test assemblies in code analyzed by NDepend. We estimate that it is acceptable and practical to lower the quality gate of test code, because the important measures for tests are:
• The coverage ratio,
• And the amount of logic results asserted: This includes both assertions in test code, and assertions in code covered by tests, like Code Contract assertions and Debug.Assert(…) assertions.
But if you wish to enforce the quality of test code, you'll need to consider test assemblies in your list of application assemblies analyzed by NDepend.
In such situation, this code query lists tests methods and you can reuse this code in custom rules.
Methods directly called by test Methods
This query lists all methods directly called by tests methods. Overrides of virtual and abstract methods, called through polymorphism, are not listed. Methods solely invoked through a delegate are not listed. Methods solely invoked through reflection are not listed.
We advise to not include test assemblies in code analyzed by NDepend. We estimate that it is acceptable and practical to lower the quality gate of test code, because the important measures for tests are:
• The coverage ratio,
• And the amount of logic results asserted: This includes both assertions in test code, and assertions in code covered by tests, like Code Contract assertions and Debug.Assert(…) assertions.
But if you wish to run this code query, you'll need to consider test assemblies in your list of application assemblies analyzed by NDepend.
Methods directly and indirectly called by test Methods
This query lists all methods directly or indirectly called by tests methods. Indirectly called by a test means that a test method calls a method, that calls a method… From this recursion, a code metric named depthOfCalledByTests is inferred, The value 1 means directly called by test, the value 2 means called by a method that is called by a test…
Overrides of virtual and abstract methods, called through polymorphism, are not listed. Methods solely invoked through a delegate are not listed. Methods solely invoked through reflection are not listed.
We advise to not include test assemblies in code analyzed by NDepend. We estimate that it is acceptable and practical to lower the quality gate of test code, because the important measures for tests are:
• The coverage ratio,
• And the amount of logic results asserted: This includes both assertions in test code, and assertions in code covered by tests, like Code Contract assertions and Debug.Assert(…) assertions.
But if you wish to run this code query, you'll need to consider test assemblies in your list of application assemblies analyzed by NDepend.
Potentially Dead Types
This rule lists potentially dead types. A dead type is a type that can be removed because it is never used by the program.
This rule lists not only types not used anywhere in code, but also types used only by types not used anywhere in code. This is why this rule comes with a column TypesusingMe and this is why there is a code metric named depth:
• A depth value of 0 means the type is not used.
• A depth value of 1 means the type is used only by types not used.
• etc…
By reading the source code of this rule, you'll see that by default, public types are not matched, because such type might not be used by the analyzed code, but still be used by client code, not analyzed by NDepend. This default behavior can be easily changed.
Note that this rule doesn't match Entity Framework ModelSnapshot classes that are used ony by the EF infrastructure.
How to Fix:
Static analysis cannot provide an exact list of dead types, because there are several ways to use a type dynamically (like through reflection).
For each type matched by this query, first investigate if the type is used somehow (like through reflection). If the type is really never used, it is important to remove it to avoid maintaining useless code. If you estimate the code of the type might be used in the future, at least comment it, and provide an explanatory comment about the future intentions.
If a type is used somehow, but still is matched by this rule, you can tag it with the attribute IsNotDeadCodeAttribute found in NDepend.API.dll to avoid matching the type again. You can also provide your own attribute for this need, but then you'll need to adapt this code rule.
Issues of this rule have a Debt equal to 15 minutes because it only takes a short while to investigate if a type can be safely discarded. The Annual Interest of issues of this rule, the annual cost to not fix such issue, is proportional to the type #lines of code, because the bigger the type is, the more it slows down maintenance.
Potentially Dead Methods
This rule lists potentially dead methods. A dead method is a method that can be removed because it is never called by the program.
This rule lists not only methods not called anywhere in code, but also methods called only by methods not called anywhere in code. This is why this rule comes with a column MethodsCallingMe and this is why there is a code metric named depth:
• A depth value of 0 means the method is not called.
• A depth value of 1 means the method is called only by methods not called.
• etc…
By reading the source code of this rule, you'll see that by default, public methods are not matched, because such method might not be called by the analyzed code, but still be called by client code, not analyzed by NDepend. This default behavior can be easily changed.
How to Fix:
Static analysis cannot provide an exact list of dead methods, because there are several ways to invoke a method dynamically (like through reflection).
For each method matched by this query, first investigate if the method is invoked somehow (like through reflection). If the method is really never invoked, it is important to remove it to avoid maintaining useless code. If you estimate the code of the method might be used in the future, at least comment it, and provide an explanatory comment about the future intentions.
If a method is invoked somehow, but still is matched by this rule, you can tag it with the attribute IsNotDeadCodeAttribute found in NDepend.API.dll to avoid matching the method again. You can also provide your own attribute for this need, but then you'll need to adapt this code rule.
Issues of this rule have a Debt equal to 10 minutes because it only takes a short while to investigate if a method can be safely discarded. On top of these 10 minutes, the depth of usage of such method adds up 3 minutes per unity because dead method only called by dead code takes a bit more time to be investigated.
The Annual Interest of issues of this rule, the annual cost to not fix such issue, is proportional to the type #lines of code, because the bigger the method is, the more it slows down maintenance.
Potentially Dead Fields
This rule lists potentially dead fields. A dead field is a field that can be removed because it is never used by the program.
By reading the source code of this rule, you'll see that by default, public fields are not matched, because such field might not be used by the analyzed code, but still be used by client code, not analyzed by NDepend. This default behavior can be easily changed. Some others default rules in the Visibility group, warn about public fields.
More restrictions are applied by this rule because of some by-design limitations. NDepend mostly analyzes compiled IL code, and the information that an enumeration value or a literal constant (which are fields) is used is lost in IL code. Hence by default this rule won't match such field.
How to Fix:
Static analysis cannot provide an exact list of dead fields, because there are several ways to assign or read a field dynamically (like through reflection).
For each field matched by this query, first investigate if the field is used somehow (like through reflection). If the field is really never used, it is important to remove it to avoid maintaining a useless code element.
If a field is used somehow, but still is matched by this rule, you can tag it with the attribute IsNotDeadCodeAttribute found in NDepend.API.dll to avoid matching the field again. You can also provide your own attribute for this need, but then you'll need to adapt this code rule.
Issues of this rule have a Debt equal to 10 minutes because it only takes a short while to investigate if a method can be safely discarded. The Annual Interest of issues of this rule, the annual cost to not fix such issue, is set by default to 8 minutes per unused field matched.
Wrong usage of IsNotDeadCodeAttribute
The attribute NDepend.Attributes.IsNotDeadCodeAttribute is defined in NDepend.API.dll. This attribute is used to mean that a code element is not used directly, but is used somehow, like through reflection.
This attribute is used in the dead code rules, Potentially dead Types, Potentially dead Methods and Potentially dead Fields. If you don't want to link NDepend.API.dll, you can use your own IsNotDeadCodeAttribute and adapt the source code of this rule, and the source code of the dead code rules.
In this context, this code rule matches code elements (types, methods, fields) that are tagged with this attribute, but still used directly somewhere in the code.
How to Fix:
Just remove IsNotDeadCodeAttribute tagging of types, methods and fields matched by this rule because this tag is not useful anymore.
Software Composition Analysis (SCA)
This rule identifies issues when the application uses a NuGet package version that has known security advisories listed on GitHub: https://github.com/advisories?query=+ecosystem%3Anuget
An issue is raised for each NuGet package consumed that is associated with at least one security advisory. The issue is reported on the first type (alphabetically) that uses a third-party assembly from the affected NuGet package.
How to Fix:
Update the affected NuGet package to a version that is at or above the patched version recommended in the advisory. The patched version resolves all matching security advisories known for the package. The patched version is not always the latest available version. For example, if an issue exists in version 4.0.2, it might be resolved in version 4.1.0, even though the highest available version could be 7.0.8.
Transitive Software Composition Analysis (SCA)
This rule identifies issues when the application uses an assembly that uses a NuGet package version that has known security advisories listed on GitHub: https://github.com/advisories?query=+ecosystem%3Anuget
An issue is raised for each package that is associated with at least one security advisory. An issue is reported on the first application type (alphabetically) that uses a third-party assembly that uses the affected package.
Unlike the rule Software Composition Analysis (SCA) that matches security advisories on Packages used the application, the present rule focuses on Packages used by the Packages used by the application, hence the qualifier transitive.
How to Fix:
Update the package that contains DirectAsm to a version that doesn't use a package that has known security advisories.
Don't use CoSetProxyBlanket and CoInitializeSecurity
As soon as some managed code starts being JIT’ed and executed by the CLR, it is too late to call CoInitializeSecurity() or CoSetProxyBlanket(). By this point in time, the CLR has already initialized the COM security environment for the entire Windows process.
How to Fix:
Don't call CoSetProxyBlanket() or CoInitializeSecurity() from managed code.
Instead write an unmanaged "shim" in C++ that will call one or both methods before loading the CLR within the process.
More information about writing such unmanaged "shim" can be found in this StackOverflow answer: https://stackoverflow.com/a/48545055/27194
Don't use System.Random for security purposes
The algorithm used by the implementation of System.Random is weak because random numbers generated can be predicted.
Using predictable random values in a security critical context can lead to vulnerabilities.
How to Fix:
If the matched method is meant to be executed in a security critical context use System.Security.Cryptography.RandomNumberGenerator or System.Security.Cryptography.RNGCryptoServiceProvider instead. These random implementations are slower to execute but the random numbers generated cannot be predicted.
Find more on using RNGCryptoServiceProvider to generate random values here: https://stackoverflow.com/questions/32932679/using-rngcryptoserviceprovider-to-generate-random-string
Otherwise you can use the faster System.Random implementation and suppress corresponding issues.
More information about the weakness of System.Random implementation can be found here: https://stackoverflow.com/a/6842191/27194
Don't use DES/3DES weak cipher algorithms
Since 2005 the NIST, the US National Institute of Standards and Technology, doesn't consider DES and 3DES cypher algorithms as secure. Source: https://www.nist.gov/news-events/news/2005/06/nist-withdraws-outdated-data-encryption-standard
How to Fix:
Use the AES (Advanced Encryption Standard) algorithms instead through the implementation: System.Security.Cryptography.AesCryptoServiceProvider.
You can still suppress issues of this rule when using DES/3DES algorithms for compatibility reasons with legacy applications and data.
Don't disable certificate validation
Matched methods are subscribing a custom certificate validation procedure through the delegate: ServicePointManager.ServerCertificateValidationCallback.
Doing so is often used to disable certificate validation to connect easily to a host that is not signed by a root certificate authority. https://en.wikipedia.org/wiki/Root_certificate
This might create a vulnerability to man-in-the-middle attacks since the client will trust any certificate. https://en.wikipedia.org/wiki/Man-in-the-middle_attack
How to Fix:
Don't rely on a weak custom certificate validation.
If a legitimate custom certificate validation procedure must be subscribed, you can chose to suppress related issue(s).
Review publicly visible event handlers
Review publicly visible event handlers to check those that are running security critical actions.
An event handler is any method with the standard signature (Object,EventArgs). An event handler can be registered to any event matching this standard signature.
As a consequence, such event handler can be subscribed by malicious code to an event to provoke execution of the security critical action on event firing.
Even if such event handler does a security check, it can be executed from a chain of trusted callers on the call stack, and cannot detect about malicious registration.
How to Fix:
Change matched event handlers to make them non-public. Preferably don't run a security critical action from an event handler.
If after a careful check no security critical action is involved from a matched event-handler, you can suppress the issue.
Pointers should not be publicly visible
Pointers should not be exposed publicly.
This rule detects fields with type System.IntPtr or System.UIntPtr that are public or protected.
Pointers are used to access unmanaged memory from managed code. Exposing a pointer publicly makes it easy for malicious code to read and write unmanaged data used by the application.
The situation is even worse if the field is not read-only since malicious code can change it and force the application to rely on arbitrary data.
How to Fix:
Pointers should have the visibility - private or internal.
The estimated Debt, which means the effort to fix such issue, is 15 minutes and 10 additional minutes per method using the field outside its assembly.
The estimated Severity of such issue is Medium, and High if the field is non read-only.
Seal methods that satisfy non-public interfaces
A match of this rule represents a virtual method, publicly visible, defined in a non-sealed public class, that overrides a method of an internal interface.
The interface not being public indicates a process that should remain private.
Hence this situation represents a security vulnerability because it is now possible to create a malicious class, that derives from the parent class and that overrides the method behavior. This malicious behavior will be then invoked by private implementation.
How to Fix:
You can:
- seal the parent class,
- or change the accessibility of the parent class to non-public,
- or implement the method without using the virtual modifier,
- or change the accessibility of the method to non-public.
If after a careful check such situation doesn't represent a security threat, you can suppress the issue.
Review commands vulnerable to SQL injection
This rule matches methods that create a DB command (like an SqlCommand or an OleDbCommand) that call an Execute command method (like ExecuteScalar()) and that don't use command parameters.
This situation is prone to SQL Injection https://en.wikipedia.org/wiki/SQL_injection since malicious SQL code might be injected in string parameters values.
However there might be false positives. So review carefully matched methods and use suppress issues when needed.
To limit the false positives, this rule also checks whether command parameters are accessed from any sub method call. This is a solid indication of non-vulnerability.
How to Fix:
If after a careful check it appears that the method is indeed using some strings to inject parameters values in the SQL query string, command.Parameters.Add(...) must be used instead.
You can get more information on adding parameters explicitly here: https://stackoverflow.com/questions/4892166/how-does-sqlparameter-prevent-sql-injection
Review data adapters vulnerable to SQL injection
This rule matches methods that create a DB adapter (like an SqlDataAdapter or an OleDbDataAdapter) that call the method Fill() and that don't use DB command parameters.
This situation is prone to SQL Injection https://en.wikipedia.org/wiki/SQL_injection since malicious SQL code might be injected in string parameters values.
However there might be false positives. So review carefully matched methods and use suppress issues when needed.
To limit the false positives, this rule also checks whether command parameters are accessed from any sub method call. This is a solid indication of non-vulnerability.
How to Fix:
If after a careful check it appears that the method is indeed using some strings to inject parameters values in the SQL query string, adapter.SelectCommand.Parameters.Add(...) must be used instead (or adapter.UpdateCommand or adapter.InsertCommand, depending on the context).
You can get more information on adding parameters explicitly here: https://stackoverflow.com/questions/4892166/how-does-sqlparameter-prevent-sql-injection
Methods that could have a lower visibility
This rule warns about methods that can be declared with a lower visibility without provoking any compilation error. For example private is a visibility lower than internal which is lower than public.
Narrowing visibility is a good practice because doing so effectively promotes encapsulation. This limits the scope from which methods can be accessed to a minimum.
By default, this rule doesn't match publicly visible methods that could have a lower visibility because it cannot know if the developer left the method public intentionally or not. Public methods matched are declared in non-public types.
By default this rule doesn't match methods with the visibility public that could be internal, declared in a type that is not public (internal, or nested private for example) because this situation is caught by the rule Avoid public methods not publicly visible.
Notice that methods tagged with one of the attribute NDepend.Attributes.CannotDecreaseVisibilityAttribute or NDepend.Attributes.IsNotDeadCodeAttribute, found in NDepend.API.dll are not matched. If you don't want to link NDepend.API.dll but still wish to rely on this facility, you can declare these attributes in your code.
How to Fix:
Declare each matched method with the specified optimal visibility in the CouldBeDeclared rule result column.
By default, this rule matches public methods. If you are publishing an API many public methods matched should remain public. In such situation, you can opt for the coarse solution to this problem by adding in the rule source code && !m.IsPubliclyVisible or you can prefer the finer solution by tagging each concerned method with CannotDecreaseVisibilityAttribute.
Types that could have a lower visibility
This rule warns about types that can be declared with a lower visibility without provoking any compilation error. For example private is a visibility lower than internal which is lower than public.
Narrowing visibility is a good practice because doing so promotes encapsulation. The scope from which types can be consumed is then reduced to a minimum.
By default, this rule doesn't match publicly visible types that could have a lower visibility because it cannot know if the developer left the type public intentionally or not. Public types matched are nested in non-public types.
Notice that types tagged with one of the attribute NDepend.Attributes.CannotDecreaseVisibilityAttribute or NDepend.Attributes.IsNotDeadCodeAttribute, found in NDepend.API.dll are not matched. If you don't want to link NDepend.API.dll but still wish to rely on this facility, you can declare these attributes in your code.
How to Fix:
Declare each matched type with the specified optimal visibility in the CouldBeDeclared rule result column.
By default, this rule matches public types. If you are publishing an API many public types matched should remain public. In such situation, you can opt for the coarse solution to this problem by adding in the rule source code && !m.IsPubliclyVisible or you can prefer the finer solution by tagging each concerned type with CannotDecreaseVisibilityAttribute.
Fields that could have a lower visibility
This rule warns about fields that can be declared with a lower visibility without provoking any compilation error. For example private is a visibility lower than internal which is lower than public.
Narrowing visibility is a good practice because doing so promotes encapsulation. The scope from which fields can be consumed is then reduced to a minimum.
By default, this rule doesn't match publicly visible fields that could have a lower visibility because it cannot know if the developer left the field public intentionally or not. Public fields matched are declared in non-public types.
Notice that fields tagged with one of the attribute NDepend.Attributes.CannotDecreaseVisibilityAttribute or NDepend.Attributes.IsNotDeadCodeAttribute, found in NDepend.API.dll are not matched. If you don't want to link NDepend.API.dll but still wish to rely on this facility, you can declare these attributes in your code.
How to Fix:
Declare each matched field with the specified optimal visibility in the CouldBeDeclared rule result column.
By default, this rule matches public fields. If you are publishing an API some public fields matched should remain public. In such situation, you can opt for the coarse solution to this problem by adding in the rule source code && !m.IsPubliclyVisible or you can prefer the finer solution by tagging eah concerned field with CannotDecreaseVisibilityAttribute.
Types that could be declared as private, nested in a parent type
This rule matches types that can be potentially nested and declared private into another type.
The conditions for a type to be potentially nested into a parent type are:
• the parent type is the only type consuming it,
• the type and the parent type are declared in the same namespace.
Declaring a type as private into a parent type improves encapsulation. The scope from which the type can be consumed is then reduced to a minimum.
This rule doesn't match classes with extension methods because such class cannot be nested in another type.
How to Fix:
Nest each matched type into the specified parent type and declare it as private.
However nested private types are hardly testable. Hence this rule might not be applied to types consumed directly by tests.
Avoid publicly visible constant fields
This rule warns about constant fields that are visible outside their parent assembly. Such field, when used from outside its parent assembly, has its constant value hard-coded into the client assembly. Hence, when changing the field's value, it is mandatory to recompile all assemblies that consume the field, else the program will run with different constant values in-memory. Certainly in such situation bugs are lurking.
Notice that enumeration value fields suffer from the same potential pitfall. But enumeration values cannot be declared as static readonly hence the rule comes with the condition && !f.IsEnumValue to avoid matching these. Unless you decide to banish public enumerations, just let the rule as is.
How to Fix:
Declare matched fields as static readonly instead of constant. This way, the field value is safely changeable without the need to recompile client assemblies.
Fields should be declared as private or protected
This rule matches mutable fields non-private, non-protected. Mutable means that the field value can be modified. Typically mutable fields are non-constant, non-readonly fields.
Fields should be considered as implementation details and as a consequence they should be declared as private, or protected if it makes sense for derived classes to use it.
If something goes wrong with a non-private field, the culprit can be anywhere, and so in order to track down the bug, you may have to look at quite a lot of code.
A private field, by contrast, can only be assigned from inside the same class, so if something goes wrong with that, there is usually only one source file to look at.
Issues of this rule are fast to get fixed, and they have a debt proportional to the number of methods assigning the field.
How to Fix:
Consider declaring a matched mutable field as private or marking it as readonly. If possible, refactor the code outside its parent type to eliminate its usage.
Alternatively, if external code requires access to the field, consider encapsulating the field accesses within a property. Using a property allows you to set debug breakpoints on the accessors, simplifying the tracking of read-write accesses in case of issues.
Constructors of abstract classes should be declared as protected or private
Constructors of abstract classes can only be called from derived classes.
Because a public constructor is creating instances of its class, and because it is forbidden to create instances of an abstract class, an abstract class with a public constructor is wrong design.
Notice that when the constructor of an abstract class is private, it means that derived classes must be nested in the abstract class.
How to Fix:
To fix a violation of this rule, either declare the constructor as protected, or do not declare the type as abstract.
Avoid public methods not publicly visible
This rule warns about methods declared as public whose parent type is not declared as public.
In such situation public means, can be accessed from anywhere my parent type is visible. Some developers think this is an elegant language construct, some others find it misleading.
This rule can be deactivated if you don't agree with it. Read the whole debate here: http://ericlippert.com/2014/09/15/internal-or-public/
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
How to Fix:
Declare the method as internal if it is used outside of its type, else declare it as private.
Event handler methods should be declared as private or protected
Think of a event handler like for example OnClickButton(). Typically such method must be declared as private and shouldn't be called in other context than event firing.
Such method can also be declared as protected because some designers such as the ASP.NET designer, generates such method as protected to let a chance to sub-classes to call it.
How to Fix:
If you have the need that event handler method should be called from another class, then find a code structure that more closely matches the concept of what you're trying to do. Certainly you don't want the other class to click a button; you want the other class to do something that clicking a button also do.
Wrong usage of CannotDecreaseVisibilityAttribute
The attribute NDepend.Attributes.CannotDecreaseVisibilityAttribute is defined in NDepend.API.dll. If you don't want to reference NDepend.API.dll you can declare it in your code.
Usage of this attribute means that a code element visibility is not optimal (it can be lowered like for example from public to internal) but shouldn’t be modified anyway. Typical reasons to do so include:
• Public code elements consumed through reflection, through a mocking framework, through XML or binary serialization, through designer, COM interfaces…
• Non-private code element invoked by test code, that would be difficult to reach from test if it was declared as private.
In such situation CannotDecreaseVisibilityAttribute is used to avoid that default rules about not-optimal visibility warn. Using this attribute can be seen as an extra burden, but it can also be seen as an opportunity to express in code: Don't change the visibility else something will be broken
In this context, this code rule matches code elements (types, methods, fields) that are tagged with this attribute, but still already have an optimal visibility.
How to Fix:
Just remove CannotDecreaseVisibilityAttribute tagging of types, methods and fields matched by this rule because this tag is not useful anymore.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Exception classes should be declared as public
Custom exception classes offer more specific details and a finer granularity compared to standard exceptions. But to have access to this extra information, code that catches the exception must have access to the exception class.
How to Fix:
Declare your custom exception classes as public to make them catchable in every context.
Methods that should be declared as 'public' in C#, 'Public' in VB.NET
This code query lists methods that should be declared as public. Such method is actually declared as internal and is consumed from outside its parent assembly thanks to the attribute System.Runtime.CompilerServices.InternalsVisibleToAttribute.
This query relies on the property NDepend.CodeModel.IMember.ShouldBePublic https://www.ndepend.com/api/webframe.html#NDepend.API~NDepend.CodeModel.IMember~ShouldBePublic.html
This is just a code query, it is not intended to advise you to declare the method as public, but to inform you that the code actually relies on the peculiar behavior of the attribute InternalsVisibleToAttribute.
Fields should be marked as ReadOnly when possible
This rule warns about instance and static fields that can be declared as readonly.
This source code of this rule is based on the conditon IField.IsImmutable. https://www.ndepend.com/api/webframe.html#NDepend.API~NDepend.CodeModel.IField~IsImmutable.html
A field that matches the condition IsImmutable is a field that is assigned only by constructors of its class.
For an instance field, this means its value will remain constant through the lifetime of the object.
For a static field, this means its value will remain constant through the lifetime of the program.
Using readonly is advantageous for enhancing code robustness and readability. Its true value becomes evident when collaborating with a team or performing maintenance. Declaring a field as readonly defines a contract for that field's usage in the code. It explicitly conveys that the field should not be altered after initialization and enforces this constraint.
How to Fix:
Declare the field with the C# readonly keyword (ReadOnly in VB.NET).
Avoid non-readonly static fields
This rule warns about static fields that are not declared as read-only.
In Object-Oriented-Programming the natural artifact to hold states that can be modified is instance fields. Such mutable static fields create confusion about the expected state at runtime and impairs the code testability since the same mutable state is re-used for each test.
More discussion on the topic can be found here: https://blog.ndepend.com/the-proper-usages-of-the-keyword-static-in-c/
How to Fix:
If the static field is just assigned once in the program lifetime, make sure to declare it as readonly and assign it inline, or from the static constructor.
Else if methods other than the static constructor need to assign the state hold by the static field, refactoring must occur to ensure that this state is hold through an instance field.
Avoid static fields with a mutable field type
This rule warns about static fields whose field type is mutable. In such case the static field is holding a state that can be modified.
In Object-Oriented-Programming the natural artifact to hold states that can be modified is instance fields. Hence such static fields create confusion about the expected state at runtime.
More discussion on the topic can be found here: https://blog.ndepend.com/the-proper-usages-of-the-keyword-static-in-c/
How to Fix:
To fix violations of this rule, make sure to hold mutable states through objects that are passed explicitly everywhere they need to be consumed, in opposition to mutable object hold by a static field that makes it modifiable from a bit everywhere in the program.
Structures should be immutable
An object is immutable if its state doesn’t change once the object has been created. Consequently, a structure or a class is immutable if its instances fields are only assigned inline or from constructor(s).
Structures are value types, which means that when you pass them as method arguments or assign them to new variables, you're working with copies of the original. This behavior is different from classes, where you work with references to the same object. Modifying copies of structures can lead to confusion and errors because developers are not accustomed to this behavior.
For more information, refer to this documentation: https://blog.ndepend.com/class-vs-struct-in-c-making-informed-choices/
How to Fix:
Make sure matched structures are immutable. This way, all automatic copies of an original instance, resulting from being passed by value will hold the same values and there will be no surprises.
Note that since C#7.2 you can prefix a structure declaration with the keyword readonly to enforce that it is an immutable structure.
If your structure is immutable then if you want to change a value, you have to consciously do it by creating a new instance of the structure with the modified data.
Immutable struct should be declared as readonly
Declare immutable structures as readonly struct. This way the C# compiler and the JIT are informed about the intent to create an immutable type. Some low-level optimizations can then be performed on instances of a readonly struct. For example such instance can be passed or returned by-reference instead of being copied on the stack. This is possible because there is no risk that the called or caller method mutates any value.
More can be read on the readonly struct topic in this documentation: https://learn.microsoft.com/en-us/dotnet/csharp/write-safe-efficient-code#declare-immutable-structs-as-readonly
How to Fix:
Just declare matched structures as readonly struct.
Property Getters should be pure
From the caller perspective, it's generally unexpected and counterintuitive for a property's getter to have side-effects. Hence a get method creates should be pure and shouldn't assign any field.
This rule doesn't match property getters that assign a field not assigned by any other methods than the getter itself and the corresponding property setter. Hence this rule avoids matching lazy initialization at first access of a state. In such situation the getter assigns a field at first access and from the client point of view, lazy initialization is an invisible implementation detail.
A field assigned by a property with a name similar to the property name are not count either, also to avoid matching lazy initialization at first access situations.
How to Fix:
Make sure that matched property getters don't assign any field.
The estimated Debt, which means the effort to fix such issue, is equal to 2 minutes plus 5 minutes per field assigned and 5 minutes per other method assigning such field.
A field must not be assigned from outside its parent hierarchy types
This rule is related to the rule Fields should be declared as private. It matches any public or internal, mutable field that is assigned from outside its parent class and subclasses.
Fields should be considered as implementation details and as a consequence they should be declared as private.
If something goes wrong with a non-private field, the culprit can be anywhere, and so in order to track down the bug, you may have to look at quite a lot of code.
A private field, by contrast, can only be assigned from inside the same class, so if something goes wrong with that, there is usually only one source file to look at.
How to Fix:
Matched fields must be declared as protected and even better as private.
However, if the field exclusively references immutable states, it can remain accessible from the outside but must be declared as readonly.
The estimated Debt, which means the effort to fix such issue, is equal to 5 minutes per method outside the parent hierarchy that assigns the matched field.
Don't assign a field from many methods
A field assigned from many methods is a symptom of bug-prone code. Notice that:
• For an instance field, constructor(s) of its class that assign the field are not counted.
• For a static field, the class constructor that assigns the field is not counted.
The default threshold for instance fields is equal to 4 or more than 4 methods assigning the instance field. Such situation makes harder to anticipate the field state at runtime. The code is then complicated to read, hard to debug and hard to maintain. Hard-to-solve bugs due to corrupted state are often the consequence of fields anarchically assigned.
The situation is even more complicated if the field is static. Indeed, such situation potentially involves global random accesses from various parts of the application. This is why this rule provides a lower threshold equals to 3 or more than 3 methods assigning the static field.
If the object containing such field is meant to be used from multiple threads, there are alarming chances that the code is unmaintainable and bugged. When multiple threads are involved, the rule of thumb is to use immutable objects.
If the field type is a reference type (interfaces, classes, strings, delegates) corrupted state might result in a NullReferenceException. If the field type is a value type (number, boolean, structure) corrupted state might result in wrong result not even signaled by an exception thrown.
How to Fix:
There is no straight advice to refactor the number of methods responsible for assigning a field. Sometime the situation is simple enough, like when a field that hold an indentation state is assigned by many writer methods. Such situation only requires to define two methods IndentPlus()/IndentMinus() that assign the field, called from all writers methods.
Sometime the solution involves rethinking and then rewriting a complex algorithm. Such field can sometime become just a variable accessed locally by a method or a closure. Sometime, just rethinking the life-time and the role of the parent object allows the field to become immutable (i.e assigned only by the constructor).
The estimated Debt, which means the effort to fix such issue, is equal to 4 minutes plus 5 minutes per method assigning the instance field or 10 minutes per method assigning the static field.
Do not declare read only fields with mutable reference types
This rule is violated when a public type contains a public read-only field whose field type is a mutable reference type.
This situation can be misleading: the keyword readonly mistakenly suggests that the object remains constant, while in fact, the field reference remains fixed but the referenced object's state can still change.
How to Fix:
To fix a violation of this rule, replace the field type with an immutable type, or declare the field as private.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Public read only array fields can be modified
This rule is violated when a publicly visible field that holds an array, is declared read-only.
This situation represents a security vulnerability. Because the field is read-only it cannot be changed to refer to a different array. However, the elements of the array that are stored in a read-only field can be changed. Code that makes decisions or performs operations that are based on the elements of a read-only array that can be publicly accessed might contain an exploitable security vulnerability.
How to Fix:
To fix the security vulnerability that is identified by this rule do not rely on the contents of a read-only array that can be publicly accessed. It is strongly recommended that you use one of the following procedures:
• Replace the array with a strongly typed collection that cannot be changed. See for example: System.Collections.Generic.IReadOnlyList<T> ; System.Collections.Generic.IReadOnlyCollection<T> ; System.Collections.ReadOnlyCollectionBase
• Or replace the public field with a method that returns a clone of a private array. Because your code does not rely on the clone, there is no danger if the elements are modified.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Types tagged with ImmutableAttribute must be immutable
An object is immutable if its state doesn’t change once the object has been created. Consequently, a structure or a class is immutable if its instances fields are only assigned inline or from constructor(s).
An attribute NDepend.Attributes.ImmutableAttribute can be used to express in code that a type is immutable. In such situation, the present code rule checks continuously that the type remains immutable whatever the modification done.
This rule warns when a type that is tagged with ImmutableAttribute is actually not immutable anymore.
Notice that ImmutableAttribute is defined in NDepend.API.dll and if you don't want to link this assembly, you can create your own ImmutableAttribute and adapt the rule.
How to Fix:
First understand which modification broke the type immutability. The list of culpritFields provided in this rule result can help. Then try to refactor the type to bring it back to immutability.
The estimated Debt, which means the effort to fix such issue, is equal to 5 minutes plus 10 minutes per culprit field.
Types immutable should be tagged with ImmutableAttribute
An object is immutable if its state doesn’t change once the object has been created. Consequently, a structure or a class is immutable if its instances fields are only assigned inline or from constructor(s).
This code query lists immutable type that are not tagged with an attribute named NDepend.Attributes.ImmutableAttribute. You can define such attribute in your code base. By using an ImmutableAttribute, you can express in source code the intention that a class is immutable, and should remain immutable in the future. Benefits of using an ImmutableAttribute are twofold:
• Not only the intention is expressed in source code,
• but it is also continuously checked by the rule Types tagged with ImmutableAttribute must be immutable.
How to Fix:
Just tag types matched by this code query with ImmutableAttribute that can be found in NDepend.API.dll, or by an attribute of yours defined in your own code (in which case this code query must be adapted).
Methods tagged with PureAttribute must be pure
A method is pure if its execution doesn’t change the value of any instance or static field. A pure method is just a function that output a result from inputs. Pure methods naturally simplify code by limiting side-effects.
An attribute PureAttribute can be used to express in code that a method is pure. In such situation, the present code rule checks continuously that the method remains pure whatever the modification done.
This rule warns when a method that is tagged with PureAttribute is actually not pure anymore.
Notice that NDepend.Attributes.PureAttribute is defined in NDepend.API.dll and if you don't want to link this assembly, you can also use System.Diagnostics.Contracts.PureAttribute or create your own PureAttribute and adapt the rule.
Notice that System.Diagnostics.Contracts.PureAttribute is taken account by the compiler only when the VS project has Microsoft Code Contract enabled.
How to Fix:
First understand which modification broke the method purity. Then refactor the method to bring it back to purity.
Pure methods should be tagged with PureAttribute
A method is pure if its execution doesn’t change the value of any instance or static field. Pure methods naturally simplify code by limiting side-effects.
This code query lists pure methods that are not tagged with a PureAttribute. By using such attribute, you can express in source code the intention that a method is pure, and should remain pure in the future. Benefits of using a PureAttribute are twofold:
• Not only the intention is expressed in source code,
• but it is also continuously checked by the rule Methods tagged with PureAttribute must be pure.
This code query is not by default defined as a code rule because certainly many of the methods of the code base are matched. Hence fixing all matches and then maintaining the rule unviolated might require a lot of work. This may counter-balance such rule benefits.
How to Fix:
Just tag methods matched by this code query with NDepend.Attributes.PureAttribute that can be found in NDepend.API.dll, or with System.Diagnostics.Contracts.PureAttribute, or with an attribute of yours defined in your own code (in which case this code query must be adapted).
Notice that System.Diagnostics.Contracts.PureAttribute is taken account by the compiler only when the VS project has Microsoft Code Contract enabled.
Record should be immutable
The language intention for C#9 record is to make it easy to create classes with value-based semantic. Value-based semantic for a class means 1) Value-based equality and 2) Immutability. These are explained in this article: https://blog.ndepend.com/c9-records-immutable-classes/
However it is still possible to create a mutable state in a record with a property setter that is not declared as init.
It is recommended to refrain from including mutable states in a record as it disrupts the value-based semantics. For example changing the state of a record object used as a key in a hash table can corrupt the hash table integrity.
Also changing the state of a record object can lead to unexpected value-based equality results. In both cases such code-smell ends up provoking bugs that are difficult to spot and difficult to fix.
How to Fix:
To fix an issue of this rule you must make sure that the matched record becomes immutable. To do so mutable property setters (culpritSetters in the result) of the setter must be transformed in property initializers with the init C# keyword. Callers of the mutable property setters (methodsCallingCulpritSetters in the result) must be also refactored to avoid changing the record states.
The estimated Debt, which means the effort to fix such issue, is equal to 8 minutes plus 3 minutes per mutable property setter and per method calling such mutable property setter.
Instance fields naming convention
By default the presents rule supports the 3 most used naming conventions for instance fields:
• Instance field name starting with a lower-case letter
• Instance field name starting with "_" followed with a lower-case letter
• Instance field name starting with "m_" followed with an upper-case letter
The rule can be easily adapted to your own company naming convention.
In terms of behavior, a static field is something completely different than an instance field, so it is interesting to differentiate them at a glance through a naming convetion.
This is why it is advised to use a specific naming convention for instance field like name that starts with m_.
Related discussion: https://blog.ndepend.com/on-hungarian-notation-for-fields-in-csharp/
How to Fix:
Once the rule has been adapted to your own naming convention make sure to name all matched instance fields adequately.
Static fields naming convention
By default the presents rule supports the 3 most used naming conventions for static fields:
• Static field name starting with an upper-case letter
• Static field name starting with "_" followed with an upper-case letter
• Static field name starting with "s_" followed with an upper-case letter
The rule can be easily adapted to your own company naming convention.
In terms of behavior, a static field is something completely different than an instance field, so it is interesting to differentiate them at a glance through a naming convetion.
This is why it is advised to use a specific naming convention for static field like name that starts with s_.
Related discussion: https://blog.ndepend.com/on-hungarian-notation-for-fields-in-csharp/
How to Fix:
Once the rule has been adapted to your own naming convention make sure to name all matched static fields adequately.
Interface name should begin with a 'I'
In the .NET world, interfaces names are commonly prefixed with an upper case I. This rule warns about interfaces whose names don't follow this convention. Because this naming convention is widely used and accepted, we recommend abiding by this rule.
Typically COM interfaces names don't follow this rule. Hence this code rule doesn't take care of interfaces tagged with ComVisibleAttribute.
How to Fix:
Make sure that matched interfaces names are prefixed with an upper I.
Abstract base class should be suffixed with 'Base'
This rule warns about abstract classes whose names are not suffixed with Base. It is a common practice in the .NET world to suffix base classes names with Base.
Notice that this rule doesn't match abstract classes that are in a middle of a hierarchy chain. In other words, only base classes that derive directly from System.Object are matched.
How to Fix:
Suffix the names of matched base classes with Base.
Exception class name should be suffixed with 'Exception'
This rule warns about exception classes whose names are not suffixed with Exception. It is a common practice in the .NET world to suffix exception classes names with Exception.
For exception base classes, the suffix ExceptionBase is also accepted.
How to Fix:
Suffix the names of matched exception classes with Exception.
Attribute class name should be suffixed with 'Attribute'
This rule warns about attribute classes whose names are not suffixed with Attribute. It is a common practice in the .NET world to suffix attribute classes names with Attribute.
How to Fix:
Suffix the names of matched attribute classes with Attribute.
Types name should begin with an Upper character
This rule warns about types whose names don't start with an Upper character. It is a common practice in the .NET world to use Pascal Casing Style to name types.
Pascal Casing Style : The first letter in the identifier and the first letter of each subsequent concatenated word are capitalized. For example: BackColor
How to Fix:
Pascal Case the names of matched types.
Methods name should begin with an Upper character
This rule warns about methods whose names don't start with an Upper character. It is a common practice in the .NET world to use Pascal Casing Style to name methods.
Pascal Casing Style : The first letter in the identifier and the first letter of each subsequent concatenated word are capitalized. For example: ComputeSize
How to Fix:
Pascal Case the names of matched methods.
Do not name enum values 'Reserved'
This rule assumes that an enumeration member with a name that contains "Reserved" is not currently used but is a placeholder to be renamed or removed in a future version. Renaming or removing a member is a breaking change. You should not expect users to ignore a member just because its name contains "Reserved" nor can you rely on users to read or abide by documentation. Furthermore, because reserved members appear in object browsers and smart integrated development environments, they can cause confusion as to which members are actually being used.
Instead of using a reserved member, add a new member to the enumeration in the future version.
In most cases, the addition of the new member is not a breaking change, as long as the addition does not cause the values of the original members to change.
How to Fix:
To fix a violation of this rule, remove or rename the member.
Avoid types with name too long
Types with a name too long tend to decrease code readability. This might also be an indication that a type is doing too much.
This rule matches types with names with more than 40 characters.
How to Fix:
To fix a violation of this rule, rename the type with a shortest name or eventually split the type in several more fine-grained types.
Avoid methods with name too long
Methods with a name too long tend to decrease code readability. This might also be an indication that a method is doing too much.
This rule matches methods with names with more than 40 characters.
However it is considered as a good practice to name unit tests in such a way with a very expressive name, hence this rule doens't match methods tagged with FactAttribute, TestAttribute and TestCaseAttribute.
How to Fix:
To fix a violation of this rule, rename the method with a shortest name that equally conveys the behavior of the method. Or eventually split the method into several smaller methods.
Avoid fields with name too long
Fields with a name too long tend to decrease code readability.
This rule matches fields with names with more than 40 characters.
How to Fix:
To fix a violation of this rule, rename the field with a shortest name that equally conveys the same information.
Avoid having different types with same name
This rule warns about multiple types with same name, that are defined in different application or third-party namespaces or assemblies.
Such practice leads confusion and also naming collision in source files that use different types with same name.
How to Fix:
To fix a violation of this rule, rename concerned types.
Avoid prefixing type name with parent namespace name
This rule warns about situations where the parent namespace name is used as the prefix of a contained type.
For example a type named "RuntimeEnvironment" declared in a namespace named "Foo.Runtime" should be named "Environment".
Such situation results in redundant naming without any improvement in readability.
How to Fix:
To fix a violation of this rule, remove the prefix from the type name.
Avoid naming types and namespaces with the same identifier
This rule warns when a type and a namespace have the same name.
For example when a type is named Environment and a namespace is named Foo.Environment.
Such situation provokes tedious compiler resolution collision, and makes the code less readable because concepts are not concisely identified.
How to Fix:
To fix a violation of this rule, renamed the concerned type or namespace.
Don't call your method Dispose
In .NET programming, the identifier Dispose should be kept only for implementations of System.IDisposable.
This rule warns when a method is named Dispose(), but the parent type doesn't implement System.IDisposable.
How to Fix:
To fix a violation of this rule, you can either have the parent type implement System.IDisposable, or rename the Dispose() method using a different identifier, such as Close() Terminate() Finish() Quit() Exit() Unlock() ShutDown()…
Methods prefixed with 'Try' should return a boolean
When a method has a name prefixed with Try, it is expected that it returns a boolean or a Task<bool> if async. This returned flag reflects the method execution status, success or failure.
Such method usually returns a result through an out parameter. For example: System.Int32.TryParse(int,out string):bool
How to Fix:
To fix a violation of this rule, Rename the method, or transform it into an operation that can fail.
Properties and fields that represent a collection of items should be named Items.
A good practice to make the code more readable and more predictable is to name properties and fields typed with a collection of items with the plural form of Items.
Depending on the domain of your application, a proper identifier could be NewDirectories, Words, Values, UpdatedDates.
Also this rule doesn't warn when any word in the identifier ends with an s. This way identifiers like TasksToRun, KeysDisabled, VersionsSupported, ChildrenFilesPath, DatedValuesDescending, ApplicationNodesChanged or ListOfElementsInResult are valid and won't be seen as violations.
Moreover this rule won't warn for a field or property with an identifier that contain the word Empty. This is a common pattern to define an immutable and empty collection instance shared.
Before inspecting properties and fields, this rule gathers application and third-party collection types that might be returned by a property or a field. To do so this rule searches types that implement IEnumerable<T> except:
- Non generic types: Often a non generic type is not seen as a collection. For example System.String implements IEnumerable<char>, but a string is rarely named as a collection of characters. In others words, we have much more strings in our program named like FirstName than named like EndingCharacters.
- Dictionaries types: A dictionary is more than a collection of pairs, it is a mapping from one domain to another. A common practice is to suffix the name of a dictionary with Map Table or Dictionary, although often dictionaries names satify this rule with names like GuidsToPersons or PersonsByNames.
How to Fix:
Just rename the fields and properties accordingly, by making plural the word in the identifier that describes best the items in the collection.
For example:
- ListOfDir can be renamed Directories.
- Children can be renamed ChildrenItems
- QueueForCache can be renamed QueueOfItemsForCache
DDD ubiquitous language check
The language used in identifiers of classes, methods and fields of the core domain, should be based on the Domain Model. This constraint is known as ubiquitous language in Domain Driven Design (DDD) and it reflects the need to be rigorous with naming, since software doesn't cope well with ambiguity.
This rule is disabled per default because its source code needs to be customized to work, both with the core domain namespace name (that contains classes and types to be checked), and with the list of domain language terms.
If a term needs to be used both with singular and plural forms, both forms need to be mentioned, like Seat and Seats for example. Notice that this default rule is related with the other default rule Properties and fields that represent a collection of items should be named Items defined in the Naming Convention group.
This rule implementation relies on the NDepend API ExtensionMethodsString.GetWords(this string identifier) extension method that extracts terms from classes, methods and fields identifiers in a smart way.
How to Fix:
For each violation, this rule provides the list of words not in vocabulary.
To fix a violation of this rule, either rename the concerned code element or update the domain language terms list defined in this rule source code, with the missing term(s).
Avoid fields with same name in class hierarchy
This rule matches a field whose name is already used by another field in the base class hierarchy.
The C# and VB.NET compilers allow this situation even if the base class field is visible to derived classes with a visibility different than private.
However this situation is certainly a sign of an erroneous attempt to redefine a field in a derived class.
How to Fix:
Check if the field in the derived class is indeed a redefinition of the base class field. Check also that both fields types corresponds. If fields are static, double check that only a single instance of the referenced object is needed. If all checks are positive delete the derived class field and make sure that the base class field is visible to derived classes with the protected visibility.
If no, rename the field in the derived class and be very careful in renaming all usages of this field, they might be related with the base class field.
Avoid various capitalizations for method name
This rule matches application methods whose names differ only in capitalization.
With this rule you'll discover various names like ProcessOrderId and ProcessOrderID. It is important to choose a single capitalization used accross the whole application to improve overall readability, maintainability, team collaboration and consistency.
Matched methods are not necessarily declared in the same type. However if various capitalizations of a method name are found within the same type, the issue severity goes from Medium to Critical. Indeed, this situation is not just a matter of convention, it is error-prone. It forces type's clients to investigate which version of the method to call.
How to Fix:
Choose a single capitalization for the method name used accross the whole application.
Or alternatively make the distinction clear by having different method names that don't only differ by capitalization.
The technical-debt for each issue, the estimated cost to fix an issue, is proportional to the number of capitalizations found (2 minimum).
Controller class name should be suffixed with 'Controller'
This rule warns about ASP.NET Controller classes whose names are not suffixed with Controller, this is a recommended practice: https://docs.microsoft.com/en-us/aspnet/core/mvc/controllers/actions
For Controller base classes, the suffix ControllerBase is also accepted.
How to Fix:
Suffix the names of matched Controller classes with Controller.
Nested class members should not mask outer class' static members
The C# compiler let's name the members of a nested class identically to the static members of its outer class, yet this approach is discouraged. The reason is that it can lead to confusion for those maintaining the code, as it might be unclear which member is being referenced in the inner class code.
How to Fix:
To avoid such naming collision, members of the inner class should be assigned unique and descriptive names.
Avoid referencing source file out of the project directory
A source file located outside of the VS project directory can be added through: > Add > Existing Items… > Add As Link
Doing so can be used to share types definitions across several assemblies. This provokes type duplication at binary level. Hence maintainability is degraded and subtle versioning bug can appear.
This rule matches types whose source files are not declared under the directory that contains the related Visual Studio project file, or under any sub-directory of this directory.
This practice can be tolerated for certain types shared across executable assemblies. Such type can be responsible for startup related concerns, such as registering custom assembly resolving handlers or checking the .NET Framework version before loading any custom library.
How to Fix:
To fix a violation of this rule, prefer referencing from a VS project only source files defined in sub-directories of the VS project file location.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Avoid duplicating a type definition across assemblies
A source file located outside of the VS project directory can be added through: > Add > Existing Items… > Add As Link
This rule warns about using this feature to share code across several assemblies. This provokes type duplication at binary level. Hence maintainability is degraded and subtle versioning bug can appear.
Each match represents a type duplicated. Unfolding the types in the column typesDefs will show the multiple definitions across multiple assemblies.
This practice can be tolerated for certain types shared across executable assemblies. Such type can be responsible for startup related concerns, such as registering custom assembly resolving handlers or checking the .NET Framework version before loading any custom library.
How to Fix:
To fix a violation of this rule, prefer sharing types through DLLs or if the types with same full name are different, rename them.
Avoid defining multiple types in a source file
Defining multiple types in a single source file decreases code readability, because developers are used to see all types in a namespace, when expanding a folder in the Visual Studio Solution Explorer. Also doing so, leads to source files with too many lines.
Each match of this rule is a source file that contains several types definitions, indexed by one of those types, preferably the one with the same name than the source file name without file extension, if any.
Notice that types nested in a parent type, enumerations and types with file visibility are exempt from counting. This is because it is considered acceptable to declare these types within the same source file as their principal user type.
How to Fix:
To fix a violation of this rule, create a source file for each type.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Namespace name should correspond to file location
To maintain a robust code structure and organization, it is advisable to synchronize the namespaces hierarchy with the directory hierarchy that contains the source files.
Following this practice is a widely accepted convention, and failing to adhere to it can result in source code that is less maintainable and harder to navigate.
This rule applies to all namespaces declared in source files where the file location does not align with the namespace name.
Please note that comparisons between namespaces and directory names are case-sensitive. Additionally, there is a boolean flag, justACaseSensitiveIssue, which indicates whether this misalignment is solely due to a case sensitivity problem. In such cases, the technical debt associated with this issue is a bit lower.
How to Fix:
To fix a violation of this rule, make sure that the namespace and the directory sub-paths that contains the source filed, are aligned.
Types with source files stored in the same directory, should be declared in the same namespace
To maintain a robust code structure and organization, it is advisable to synchronize the namespaces hierarchy with the directory hierarchy that contains the source files.
Following this practice is a widely accepted convention, and failing to adhere to it can result in source code that is less maintainable and harder to navigate.
Respecting this convention means that types with source files stored in the same directory, should be declared in the same namespace.
For each directory that contains several source files, where most types are declared in a namespace (what we call the main namespace) and a few types are declared out of the main namespace, this code rule matches:
• The main namespace
• typesOutOfMainNamespace: Types declared in source files in the main namespace's directory but that are not in the main namespace.
• typesInMainNamespace: And for informational purposes, types declared in source files in the main namespace's directory, and that are in the main namespace.
How to Fix:
Violations of this rule are types in the typesOutOfMainNamespace column. Typically such type …
• … is contained in the wrong namespace but its source file is stored in the right directory. In such situation the type should be contained in main namespace.
• … is contained in the right namespace but its source file is stored in the wrong directory In such situation the source file of the type must be moved to the proper parent namespace directory.
• … is declared in multiple source files, stored in different directories. In such situation it is preferable that all source files are stored in a single directory.
The estimated Debt, which means the effort to fix such issue, is equal to 2 minutes plus 5 minutes per type in typesOutOfMainNamespace.
Types declared in the same namespace, should have their source files stored in the same directory
To maintain a robust code structure and organization, it is advisable to synchronize the namespaces hierarchy with the directory hierarchy that contains the source files.
Following this practice is a widely accepted convention, and failing to adhere to it can result in source code that is less maintainable and harder to navigate.
Respecting this convention means that types declared in the same namespace, should have their source files stored in the same directory.
For each namespace that contains types whose source files are declared in several directories, infer the main directory, the directory that naturally hosts source files of types, preferably the directory whose name corresponds with the namespace name. In this context, this code rule matches:
• The namespace
• typesDeclaredOutOfMainDir: types in the namespace whose source files are stored out of the main directory.
• The main directory
• typesDeclaredInMainDir: for informational purposes, types declared in the namespace, whose source files are stored in the main directory.
How to Fix:
Violations of this rule are types in the typesDeclaredOutOfMainDir column. Typically such type…
• … is contained in the wrong namespace but its source file is stored in the right directory. In such situation the type should be contained in the namespace corresponding to the parent directory.
• … is contained in the right namespace but its source file is stored in the wrong directory. In such situation the source file of the type must be moved to the main directory.
• … is declared in multiple source files, stored in different directories. In such situation it is preferable that all source files are stored in a single directory.
The estimated Debt, which means the effort to fix such issue, is equal to 2 minutes plus 5 minutes per type in typesDeclaredOutOfMainDir.
Mark ISerializable types with SerializableAttribute
To be recognized by the CLR as serializable, types must be marked with the SerializableAttribute attribute even if the type uses a custom serialization routine through implementation of the ISerializable interface.
This rule matches types that implement ISerializable and that are not tagged with SerializableAttribute.
How to Fix:
To fix a violation of this rule, tag the matched type with SerializableAttribute .
Mark assemblies with CLSCompliant (deprecated)
This rule has been deprecated and, as a consequence, it is disabled by default. Feel free to re-enable it if it makes sense in your dev environment.
The Common Language Specification (CLS) defines naming restrictions, data types, and rules to which assemblies must conform if they are to be used across programming languages. Good design dictates that all assemblies explicitly indicate CLS compliance with CLSCompliantAttribute. If the attribute is not present on an assembly, the assembly is not compliant.
Notice that it is possible for a CLS-compliant assembly to contain types or type members that are not compliant.
This rule matches assemblies that are not tagged with System.CLSCompliantAttribute.
How to Fix:
To fix a violation of this rule, tag the assembly with CLSCompliantAttribute.
Instead of marking the whole assembly as non-compliant, you should determine which type or type members are not compliant and mark these elements as such. If possible, you should provide a CLS-compliant alternative for non-compliant members so that the widest possible audience can access all the functionality of your assembly.
Mark assemblies with ComVisible (deprecated)
This rule has been deprecated and, as a consequence, it is disabled by default. Feel free to re-enable it if it makes sense in your dev environment.
The ComVisibleAttribute attribute determines how COM clients access managed code. Good design dictates that assemblies explicitly indicate COM visibility. COM visibility can be set for a whole assembly and then overridden for individual types and type members. If the attribute is not present, the contents of the assembly are visible to COM clients.
This rule matches assemblies that are not tagged with System.Runtime.InteropServices.ComVisibleAttribute.
How to Fix:
To fix a violation of this rule, tag the assembly with ComVisibleAttribute.
If you do not want the assembly to be visible to COM clients, set the attribute value to false.
Mark attributes with AttributeUsageAttribute
When you define a custom attribute, mark it by using AttributeUsageAttribute to indicate where in the source code the custom attribute can be applied. The meaning and intended usage of an attribute will determine its valid locations in code. For example, you might define an attribute that identifies the person who is responsible for maintaining and enhancing each type in a library, and that responsibility is always assigned at the type level. In this case, compilers should enable the attribute on classes, enumerations, and interfaces, but should not enable it on methods, events, or properties. Organizational policies and procedures would dictate whether the attribute should be enabled on assemblies.
The System.AttributeTargets enumeration defines the targets that you can specify for a custom attribute. If you omit AttributeUsageAttribute, your custom attribute will be valid for all targets, as defined by the All value of AttributeTargets enumeration.
This rule matches attribute classes that are not tagged with System.AttributeUsageAttribute.
Abstract attribute classes are not matched since AttributeUsageAttribute can be deferred to derived classes.
Attribute classes that have a base class tagged with AttributeUsageAttribute are not matched since in this case attribute usage is inherited.
How to Fix:
To fix a violation of this rule, specify targets for the attribute by using AttributeUsageAttribute with the proper AttributeTargets values.
Remove calls to GC.Collect()
It's better not to use GC.Collect() directly because doing so can lead to performance issues.
More in information on this here: http://blogs.msdn.com/ricom/archive/2004/11/29/271829.aspx
This rule matches application methods that call an overload of the method GC.Collect().
How to Fix:
Remove matched calls to GC.Collect().
Don't call GC.Collect() without calling GC.WaitForPendingFinalizers()
It's better not to use GC.Collect() directly because doing so can lead to performance issues. This situation is checked through the default rules: Remove calls to GC.Collect()
But if you wish to call GC.Collect() anyway, you must do it this way:
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
To make sure that finalizer got executed, and object with finalizer got cleaned properly.
This rule matches application methods that call an overload of the method GC.Collect(), without calling GC.WaitForPendingFinalizers().
How to Fix:
To fix a violation of this rule, if you really need to call GC.Collect(), make sure to call GC.WaitForPendingFinalizers() properly.
Enum Storage should be Int32
An enumeration is a value type that defines a set of related named constants. By default, the System.Int32 data type is used to store the constant value.
Even though you can change this underlying type, it is not necessary or recommended for most scenarios. Note that using a data type smaller than Int32 doesn't result in a significant performance improvement. If you cannot use the default data type, you should use one of the Common Language System (CLS)-compliant integral types, Byte, Int16, Int32, or Int64 to make sure that all values of the enumeration can be represented in CLS-compliant programming languages.
This rule matches enumerations whose underlying type used to store values is not System.Int32.
How to Fix:
To fix a violation of this rule, unless size or compatibility issues exist, use Int32. For situations where Int32 is not large enough to hold the values, use Int64. If backward compatibility requires a smaller data type, use Byte or Int16.
Do not raise too general exception types
The following exception types are too general to provide sufficient information to the user:
• System.Exception
• System.ApplicationException
• System.SystemException
If you throw such a general exception type in a library or framework, it compels client code to catch all exceptions, including unknown exceptions that they do not know how to handle.
This rule matches methods that create an instance of such general exception class.
How to Fix:
To fix a violation of this rule, change the type of the thrown exception to either a more derived type that already exists in the framework, or create your own type that derives from System.Exception.
The estimated Debt, which means the effort to fix such issue, is equal to 15 minutes per method matched, plus 5 minutes per too general exception types instantiated by the method.
Do not raise reserved exception types
The following exception types are reserved and should be thrown only by the runtime:
• System.ExecutionEngineException
• System.IndexOutOfRangeException
• System.OutOfMemoryException
• System.StackOverflowException
• System.InvalidProgramException
• System.AccessViolationException
• System.CannotUnloadAppDomainException
• System.BadImageFormatException
• System.DataMisalignedException
Do not throw an exception of such reserved type.
This rule matches methods that create an instance of such reserved exception class.
How to Fix:
To fix a violation of this rule, change the type of the thrown exception to a specific type that is not one of the reserved types.
Concerning the particular case of a method throwing System.NullReferenceException, often the fix will be either to throw instead System.ArgumentNullException, either to use a contract (through MS Code Contracts API or Debug.Assert()) to signify that a null reference at that point can only be the consequence of a bug.
More generally the idea of using a contract instead of throwing an exception in case of corrupted state / bug consequence detected is a powerful idea. It replaces a behavior (throwing exception) with a declarative assertion that basically means: at that point a bug somehow provoqued the detected corrupted state and continuing any processing from now is potentially harmful. The process should be shutdown and the circonstances of the failure should be reported as a bug to the product team.
Uri fields or properties should be of type System.Uri
A field or a property with the name ending with 'Uri' or 'Url' is deemed to represent a Uniform Resource Identifier or Locator. Such field or property should be of type System.Uri.
This rule matches fields and properties with the name ending with 'Uri' or 'Url' that are not typed with System.Uri.
How to Fix:
Rename the field or property, or change the field or property type to System.Uri.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Types should not derive from System.ApplicationException
At .NET Framework version 1 time, it was recommended to derive new exceptions from ApplicationException.
The recommendation has changed and new exceptions should derive from System.Exception or one of its subclasses in the System namespace.
This rule matches application exception classes that derive from ApplicationException.
How to Fix:
Make sure that matched exception types, derive from System.Exception or one of its subclasses in the System namespace.
Don't Implement ICloneable
The interface System.ICloneable is proposed since the first version of .NET. It is considered as a bad API for several reasons.
First, this interface existed even before .NET 2.0 that introduced generics. Hence this interface is not generic and the Clone() method returns an object reference that needs to be downcasted to be useful.
Second, this interface doesn't make explicit whether the cloning should be deep or shallow. The difference between the two behaviors is fundamental (explanation here https://stackoverflow.com/a/184745/27194). Not being able to make the intention explicit leads to confusion.
Third, classes that derive from a class that implements ICloneable must also implement the Clone() method, and it is easy to forget this constraint.
This rule doesn't warn for classes that derive from a class that implements ICloneable. In this case the issue must be fixed in the base class, or is maybe not fixable if the base class is declared in a third-party assembly.
How to Fix:
Don't implement anymore this interface.
You can rename the remaining Clone() methods to DeepClone() or ShallowClone() with a typed result.
Or you can propose two custom generic interfaces IDeepCloneable<T> with the single method DeepClone():T and IShallowCloneable<T> with the single method ShallowClone():T.
Finally you can write custom NDepend rules to make sure that all classes that derive from a class with a virtual clone method, override this method.
Collection properties should be read only
A writable collection property allows a user to replace the collection with a completely different collection. A read-only property stops the collection from being replaced but still allows the individual members to be set. If replacing the collection is a goal, the preferred design pattern is to include a method to remove all the elements from the collection and a method to re-populate the collection. See the Clear() and AddRange() methods of the System.Collections.Generic.List<T> class for an example of this pattern.
Both binary and XML serialization support read-only properties that are collections. The System.Xml.Serialization.XmlSerializer class has specific requirements for types that implement ICollection and System.Collections.IEnumerable in order to be serializable.
This rule matches property setter methods that assign a collection object.
How to Fix:
To fix a violation of this rule, make the property read-only and, if the design requires it, add methods to clear and re-populate the collection.
Don't use .NET 1.x HashTable and ArrayList
This rule has been deprecated and, as a consequence, it is disabled by default. Feel free to re-enable it if it makes sense in your dev environment.
This rule warns about application methods that use a non-generic collection class, including ArrayList, HashTable, Queue, Stack or SortedList.
How to Fix:
List<T> should be preferred over ArrayList. It is generic hence you get strongly typed elements. Also, it is faster with T as a value types since it avoids boxing.
For the same reasons:
• Dictionary<K,V> should be prevered over HashTable.
• Queue<T> should be prevered over Queue.
• Stack<T> should be prevered over Stack.
• SortedDictionary<K,V> or SortedList<K,V> should be prevered over SortedList.
You can be forced to use non generic collections because you are using third party code that requires working with these classes or because you are coding with .NET 1.x, but nowadays this situation should question about using newer updates of .NET. .NET 1.x is an immature platform conpared to newer .NET updates.
Caution with List.Contains()
This code query matches calls to List<T>.Contains() method.
The cost of checking if a list contains an object is proportional to the size of the list. In other words it is a O(N) operation. For large lists and/or frequent calls to Contains(), prefer using the System.Collections.Generic.HashSet<T> class where calls to Contains() take a constant time (O(0) operation).
This code query is not a code rule, because more often than not, calling O(N) Contains() is not a mistake. This code query aims at pointing out this potential performance pitfall.
Prefer return collection abstraction instead of implementation
This code query matches methods that return a collection implementation, such as List<T> HashSet<T> or Dictionary<TKey,TValue>.
Most often than not, clients of a method don't need to know the exact implementation of the collection returned. It is preferable to return a collection interface such as IList<T>, ICollection<T>, IEnumerable<T> or IDictionary<TKey,TValue>.
Using the collection interface instead of the implementation shouldn't applies to all cases, hence this code query is not code rule.
P/Invokes should be static and not be publicly visible
Methods that are marked with the DllImportAttribute attribute (or methods that are defined by using the Declare keyword in Visual Basic) use Platform Invocation Services to access unmanaged code.
Such methods should not be exposed. By keeping these methods private or internal, you make sure that your library cannot be used to breach security by allowing callers access to unmanaged APIs that they could not call otherwise.
This rule matches methods tagged with DllImportAttribute attribute that are declared as public or declared as non-static.
How to Fix:
To fix a violation of this rule, change the access level of the method and/or declare it as static.
Move P/Invokes to NativeMethods class
Platform Invocation methods, such as those that are marked by using the System.Runtime.InteropServices.DllImportAttribute attribute, or methods that are defined by using the Declare keyword in Visual Basic, access unmanaged code. These methods should be in one of the following classes:
• NativeMethods - This class does not suppress stack walks for unmanaged code permission. (System.Security.SuppressUnmanagedCodeSecurityAttribute must not be applied to this class.) This class is for methods that can be used anywhere because a stack walk will be performed.
• SafeNativeMethods - This class suppresses stack walks for unmanaged code permission. (System.Security.SuppressUnmanagedCodeSecurityAttribute is applied to this class.) This class is for methods that are safe for anyone to call. Callers of these methods are not required to perform a full security review to make sure that the usage is secure because the methods are harmless for any caller.
• UnsafeNativeMethods - This class suppresses stack walks for unmanaged code permission. (System.Security.SuppressUnmanagedCodeSecurityAttribute is applied to this class.) This class is for methods that are potentially dangerous. Any caller of these methods must perform a full security review to make sure that the usage is secure because no stack walk will be performed.
These classes are declared as static internal. The methods in these classes are static and internal.
This rule matches P/Invoke methods not declared in such NativeMethods class.
How to Fix:
To fix a violation of this rule, move the method to the appropriate NativeMethods class. For most applications, moving P/Invokes to a new class that is named NativeMethods is enough.
NativeMethods class should be static and internal
In the description of the default rule Move P/Invokes to NativeMethods class it is explained that NativeMethods classes that host P/Invoke methods, should be declared as static and internal.
This code rule warns about NativeMethods classes that are not declared static and internal.
How to Fix:
Matched NativeMethods classes must be declared as static and internal.
Don't create threads explicitly
This code rule warns about methods that create threads explicitly by creating an instance of the class System.Threading.Thread.
Prefer using the thread pool instead of creating manually your own threads. Threads are costly objects. They take approximately 200,000 cycles to create and about 100,000 cycles to destroy. By default they reserve 1 Mega Bytes of virtual memory for its stack and use 2,000-8,000 cycles for each context switch.
As a consequence, it is preferable to let the thread pool recycle threads.
How to Fix:
Instead of creating explicitly threads, use the Task Parallel Library (TPL) that relies on the CLR thread pool.
Introduction to TPL: https://msdn.microsoft.com/en-us/library/dd460717(v=vs.110).aspx
TPL and the CLR v4 thread pool: http://www.danielmoth.com/Blog/New-And-Improved-CLR-4-Thread-Pool-Engine.aspx
By default issues of this rule have a Critical severity because creating threads can have severe consequences.
Don't use dangerous threading methods
This rule warns about using the methods Abort(), Sleep(), Suspend() or Resume() declared by the Thread class.
• Usage of Thread.Abort() is dangerous. More information on this here: http://www.interact-sw.co.uk/iangblog/2004/11/12/cancellation
• Usage of Thread.Sleep() is a sign of flawed design. More information on this here: http://msmvps.com/blogs/peterritchie/archive/2007/04/26/thread-sleep-is-a-sign-of-a-poorly-designed-program.aspx
• Suspend() and Resume() are dangerous threading methods, marked as obsolete. More information on workaround here: http://stackoverflow.com/questions/382173/what-are-alternative-ways-to-suspend-and-resume-a-thread
How to Fix:
Suppress calls to Thread methods exposed in the suppressCallsTo column in the rule result.
Use instead facilities offered by the Task Parallel Library (TPL) : https://msdn.microsoft.com/en-us/library/dd460717(v=vs.110).aspx
Monitor TryEnter/Exit must be both called within the same method
This rule warns when System.Threading.Monitor Enter() (or TryEnter()) and *Exit() methods are not called within the same method.
Doing so makes the code less readable, because it gets harder to locate when critical sections begin and end.
Also, you expose yourself to complex and error-prone scenarios.
How to Fix:
Refactor matched methods to make sure that Monitor critical sections begin and end within the same method. Basics scenarios can be handled through the C# lock keyword. Using explicitly the class Monitor should be left for advanced situations, that require calls to methods like Wait() and Pulse().
More information on using the Monitor class can be found here: http://www.codeproject.com/Articles/13453/Practical-NET-and-C-Chapter
ReaderWriterLock AcquireLock/ReleaseLock must be both called within the same method
This rule warns when System.Threading.ReaderWriterLock acquire and release, reader or writer locks methods are not called within the same method.
Doing so makes the code less readable, because it gets harder to locate when critical sections begin and end.
Also, you expose yourself to complex and error-prone scenarios.
How to Fix:
Refactor matched methods to make sure that ReaderWriterLock read or write critical sections begin and end within the same method.
Don't tag instance fields with ThreadStaticAttribute
This rule warns when the attribute System.ThreadStaticAttribute is tagging instance fields. As explained in documentation, this attribute is intended to be used exclusively with fields that are declared as static. https://msdn.microsoft.com/en-us/library/system.threadstaticattribute
How to Fix:
Refactor the code to make sure that all fields tagged with ThreadStaticAttribute are static.
Method non-synchronized that read mutable states
Mutable object states are instance fields that can be modified through the lifetime of the object.
Mutable type states are static fields that can be modified through the lifetime of the program.
This query lists methods that read mutable state without synchronizing access. In the case of multi-threaded program, doing so can lead to state corruption.
This code query is not a code rule because more often than not, a match of this query is not an issue.
Method should not return concrete XmlNode
This rule warns about method whose return type is System.Xml.XmlNode or any type derived from XmlNode.
XmlNode implements the interface System.Xml.Xpath.IXPathNavigable. In most situation, returning this interface instead of the concrete type is a better design choice that will abstract client code from implementation details.
How to Fix:
To fix a violation of this rule, change the concrete returned type to the suggested interface IXPathNavigable and refactor clients code if possible.
Types should not derive from System.Xml.XmlDocument
This rule warns aboud subclasses of System.Xml.XmlDocument.
Do not create a subclass of XmlDocument if you want to create an XML view of an underlying object model or data source.
How to Fix:
Instead of subclassing XmlDocument, you can use the interface System.Xml.XPath.IXPathNavigable implemented by the class XmlDocument.
An alternative of using XmlDocument, is to use System.Xml.Linq.XDocument, aka LINQ2XML. More information on this can be found here: http://stackoverflow.com/questions/1542073/xdocument-or-xmldocument
Float and Date Parsing must be culture aware
Globalization is the design and development of applications that support localized user interfaces and regional data for users in multiple cultures.
This rule warns about the usage of non-globalized overloads of the methods Parse(), TryParse() and ToString(), of the types DateTime, float, double and decimal. This is the symptom that your application is at least partially not globalized.
Non-globalized overloads of these methods are the overloads that don't take a parameter of type IFormatProvider.
How to Fix:
Globalize your applicaton and make sure to use the globalized overloads of these methods. In the column MethodsCallingMe of this rule result are listed the methods of your application that call the non-globalized overloads.
More information on Creating Globally Aware Applications here: https://msdn.microsoft.com/en-us/library/cc853414(VS.95).aspx
The estimated Debt, which means the effort to fix such issue, is equal to 5 minutes per application method calling at least one non-culture aware method called, plus 3 minutes per non-culture aware method called.
Mark assemblies with assembly version
The identity of an assembly is composed of the following information:
• Assembly name
• Version number
• Culture
• Public key (for strong-named assemblies).
The .NET Framework uses the version number to uniquely identify an assembly, and to bind to types in strong-named assemblies. The version number is used together with version and publisher policy. By default, applications run only with the assembly version with which they were built.
This rule matches assemblies that are not tagged with System.Reflection.AssemblyVersionAttribute.
How to Fix:
To fix a violation of this rule, add a version number to the assembly by using the System.Reflection.AssemblyVersionAttribute attribute.
Assemblies should have the same version
This rule reports application assemblies that have a version different than the version shared by most of application assemblies.
Before fixing these issues, double check if there is a valid reason for dealing with more than one assembly version number. Typically this happens when the analyzed code base is made of assemblies that are not compiled, developed or deployed together.
How to Fix:
If all assemblies of your application should have the same version number, just use the attribute System.Reflection.AssemblyVersion in a source file shared by the assemblies.
Typically this source file is generated by a dedicated MSBuild task like this one http://www.msbuildextensionpack.com/help/4.0.5.0/html/d6c3b5e8-00d4-c826-1a73-3cfe637f3827.htm.
Here you can find interesting assemblies versioning advices. http://stackoverflow.com/a/3905443/27194
By default issues of this rule have a severity set to major since unproper assemblies versioning can lead to complicated deployment problem.
Assemblies Referenced in Multiple Versions
This rule detects third-party assemblies that are referenced in multiple versions.
Such situations may result in unexpected behavior and unexpected bugs.
The issue explanation provides a list of assemblies referencing different versions of the target assembly.
This list includes both application assemblies and third-party assemblies.
The assembly scan is transitive since references of third-party assemblies are considered.
How to Fix:
Make sure that all packages consummed by the application are referenced in a single version.
To do so rely on Transitive pinning in Central Package Management. Set the MSBuild property CentralPackageTransitivePinningEnabled to true in a Directory.Packages.props or Directory.Build.props import file. More on this here: https://blog.ndepend.com/understand-nuget-central-package-management-and-transitive-pinning-with-examples/
Public methods returning a reference needs a contract to ensure that a non-null reference is returned
Code Contracts are useful to decrease ambiguity between callers and callees. Not ensuring that a reference returned by a method is non-null leaves ambiguity for the caller. This rule matches methods returning an instance of a reference type (class or interface) that doesn't use a Contract.Ensure() method.
Contract.Ensure() is defined in the Microsoft Code Contracts for .NET library, and is typically used to write a code contract on returned reference: Contract.Ensures(Contract.Result<ReturnType>() != null, "returned reference is not null"); https://visualstudiogallery.msdn.microsoft.com/1ec7db13-3363-46c9-851f-1ce455f66970
How to Fix:
Use Microsoft Code Contracts for .NET on the public surface of your API, to remove most ambiguity presented to your client. Most of such ambiguities are about null or not null references.
Don't use null reference if you need to define a method that might not return a result. Use instead the TryXXX() pattern exposed for example in the System.Int32.TryParse() method.
The estimated Debt, which means the effort to fix such issue, is equal to 5 minutes per public application method that might return a null reference plus 3 minutes per method calling such method.
Classes tagged with InitializeOnLoad should have a static constructor
The attribute InitializeOnLoadAttribute is used to initialize an Editor class when Unity loads and when your scripts are recompiled.
The static constructors of the class tagged with this attribute is responsible for the initialization.
How to Fix:
Create a static constructor for the matched classes.
Avoid using non-generic GetComponent
Prefer using the generic version of Component.GetComponent() for type safety.
How to Fix:
Refactor GetComponent(typeof(MyType)) calls in GetComponent<MyType>().
Avoid empty Unity message
Unity messages are called by the runtime even if they don't contain any code.
How to Fix:
Remove matched methods to avoid unnecessary processing.
Avoid using Time.fixedDeltaTime with Update
Update() and FixedUpdate() are dependent on the frame rate. For reading the delta time it is recommended to use Time.deltaTime instead of Time.fixedDeltaTime because it automatically returns the right delta time if you are inside these functions.
How to Fix:
Refactor calls to Time.fixedDeltaTime with Time.deltaTime within Update() and FixedUpdate() functions
Use CreateInstance to create a scriptable object
If Foo is a type that derives from UnityEngine.ScriptableObject the method ScriptableObject.CreateInstance<T>() must be used to create an instance of Foo.
This is because the Unity egine needs to create the scriptable object itself to handle Unity message methods.
How to Fix:
Replace new Foo() expressions with ScriptableObject.CreateInstance<Foo>() expressions.
The SerializeField attribute is redundant on public fields
The SerializeField attribute makes a field display in the Inspector and causes it to be saved.
Declaring a field as public makes a field display in the Inspector and causes it to be saved, as well as letting the field be publicly accessed by other scripts.
Hence the SerializeField attribute is redundant for public fields.
How to Fix:
Remove the SerializeField attribute on matched public fields.
InitializeOnLoadMethod should tag only static and parameterless methods
The attribute InitializeOnLoadMethodAttribute allows an editor static method to be initialized when Unity loads without action from the user.
The attribute RuntimeInitializeOnLoadMethodAttribute has same behavior except that the methods are invoked after the game has been loaded.
Both attributes can only tag static and parameterless methods.
How to Fix:
Make the matched methods static and parameterless.
Prefer using SetPixels32() over SetPixels()
The structure Color uses floating point values within the range [0.0,1.0] to represent each color component.
The structure Color32 uses a byte value within the range [0,255] to represent each color component.
Hence Color32 consumes 4 times less memory and is much faster to work with.
How to Fix:
If 32bit-RGBA is compatible with your scenario, use SetPixels32() instead.
Don't use System.Reflection in performance critical messages
System.Reflection is a slow API.
Don't use it in performance critical messages like Update, FixedUpdate, LateUpdate, or OnGUI.
How to Fix:
Don't use reflection in matched methods.
Discard generated Assemblies from JustMyCode
This code query is prefixed with notmycode. This means that all application assemblies matched by this code query are removed from the code base view JustMyCode.Assemblies. It also means that all namespaces, types, methods and fields contained in a matched assembly are removed from the code base view JustMyCode. The code base view JustMyCode is used by most default code queries and rules.
So far this query only matches application assemblies tagged with System.CodeDom.Compiler.GeneratedCodeAttribute, ASP.NET Core Razor assemblies suffixed with .Views.dll and assemblies with no C#, VB or F# code. Make sure to make this query richer to discard your generated assemblies from the NDepend rules results.
notmycode queries are executed before running others queries and rules. Also modifying a notmycode query provokes re-run of queries and rules that rely on the JustMyCode code base view.
Several notmycode queries can be written to match assemblies, in which case this results in cumulative effect.
Online documentation: https://www.ndepend.com/docs/cqlinq-syntax#NotMyCode
Discard generated Namespaces from JustMyCode
This code query is prefixed with notmycode. This means that all application namespaces matched by this code query are removed from the code base view JustMyCode.Namespaces. It also means that all types, methods and fields contained in a matched namespace are removed from the code base view JustMyCode. The code base view JustMyCode is used by most default code queries and rules.
So far this query matches the My namespaces generated by the VB.NET compiler. This query also matches namespaces named mshtml or Microsoft.Office.* that are generated by tools.
notmycode queries are executed before running others queries and rules. Also modifying a notmycode query provokes re-run of queries and rules that rely on the JustMyCode code base view.
Several notmycode queries can be written to match namespaces, in which case this results in cumulative effect.
Online documentation: https://www.ndepend.com/docs/cqlinq-syntax#NotMyCode
Discard generated Types from JustMyCode
This code query is prefixed with notmycode. This means that all application types matched by this code query are removed from the code base view JustMyCode.Types. It also means that all methods and fields contained in a matched type are removed from the code base view JustMyCode. The code base view JustMyCode is used by most default code queries and rules.
So far this query matches several well-identified generated types, like the ones tagged with System.CodeDom.Compiler.GeneratedCodeAttribute. Make sure to make this query richer to discard your generated types from the NDepend rules results.
notmycode queries are executed before running others queries and rules. Also modifying a notmycode query provokes re-run of queries and rules that rely on the JustMyCode code base view.
Several notmycode queries can be written to match types, in which case this results in cumulative effect.
Online documentation: https://www.ndepend.com/docs/cqlinq-syntax#NotMyCode
Discard generated and designer Methods from JustMyCode
This code query is prefixed with notmycode. This means that all application methods matched by this code query are removed from the code base view JustMyCode.Methods. The code base view JustMyCode is used by most default code queries and rules.
So far this query matches several well-identified generated methods, like the ones tagged with System.CodeDom.Compiler.GeneratedCodeAttribute, or the ones declared in a source file suffixed with .designer.cs. Make sure to make this query richer to discard your generated methods from the NDepend rules results.
notmycode queries are executed before running others queries and rules. Also modifying a notmycode query provokes re-run of queries and rules that rely on the JustMyCode code base view.
Several notmycode queries can be written to match methods, in which case this results in cumulative effect.
Online documentation: https://www.ndepend.com/docs/cqlinq-syntax#NotMyCode
Discard generated Fields from JustMyCode
This code query is prefixed with notmycode. This means that all application fields matched by this code query are removed from the code base view JustMyCode.Fields. The code base view JustMyCode is used by most default code queries and rules.
This query matches application fields tagged with System.CodeDom.Compiler.GeneratedCodeAttribute, and Windows Form, WPF and UWP fields generated by the designer. Make sure to make this query richer to discard your generated fields from the NDepend rules results.
notmycode queries are executed before running others queries and rules. Also modifying a notmycode query provokes re-run of queries and rules that rely on the JustMyCode code base view.
Several notmycode queries can be written to match fields, in which case this results in cumulative effect.
Online documentation: https://www.ndepend.com/docs/cqlinq-syntax#NotMyCode
JustMyCode code elements
This code query enumerates all assemblies, namespaces, types, methods and fields in your application, that are considered as being your code.
This means concretely that the ICodeBaseView JustMyCode only shows these code elements. This code base view is used by many default code rule to avoid being warned on code elements that you don't consider as your code - typically the code elements generated by a tool.
These code elements are the ones that are not matched by any quere prefixed with notmycode.
NotMyCode code elements
This code query enumerates all assemblies, namespaces, types, methods and fields in your application, that are considered as not being your code.
This means concretely that the ICodeBaseView JustMyCode hide these code elements. This code base view is used by many default code rules to avoid being warned on code elements that you don't consider as your code - typically the code elements generated by a tool.
These code elements are the ones matched by queries prefixed with notmycode.
# Issues Worsened since Baseline
An issue is considered worsened if its debt increased since the baseline.
Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
# Issues with severity Blocker
An issue with the severity Blocker cannot move to production, it must be fixed.
The severity of an issue is inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > Issue and Debt.
# Issues with severity Critical
An issue with a severity level Critical shouldn't move to production. It still can for business imperative needs purposes, but at worth it must be fixed during the next iterations.
The severity of an issue is inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > Issue and Debt.
# Issues with severity High
An issue with a severity level High should be fixed quickly, but can wait until the next scheduled interval.
The severity of an issue is inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > issue and Debt.
# Issues with severity Medium
An issue with a severity level Medium is a warning that if not fixed, won't have a significant impact on development.
The severity of an issue is inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > issue and Debt.
# Issues with severity Low
The severity level Low is used by issues that have a zero, or close to zero, value for Annual Interest.
Issues with a Low or Medium severity level represents small improvements, ways to make the code looks more elegant.
The Broken Window Theory https://en.wikipedia.org/wiki/Broken_windows_theory states that:
"Consider a building with a few broken windows. If the windows are not repaired, the tendency is for vandals to break a few more windows. Eventually, they may even break into the building, and if it's unoccupied, perhaps become squatters or light fires inside."
Issues with a Low or Medium severity level represents the broken windows of a code base. If they are not fixed, the tendency is for developers to not care for living in an elegant code, which will result in extra-maintenance-cost in the long term.
The severity of an issue is inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > issue and Debt.
# Blocker/Critical/High Issues
The number of issues with a severity Blocker, Critical or High.
An issue with the severity Blocker cannot move to production, it must be fixed.
An issue with a severity level Critical shouldn't move to production. It still can for business imperative needs purposes, but at worth it must be fixed during the next iterations.
An issue with a severity level High should be fixed quickly, but can wait until the next scheduled interval.
# Issues
The number of issues no matter the issue severity.
# Suppressed Issues
The number of issues suppressed with the usage of SuppressMessage. See the suppressed issues documentation here: https://www.ndepend.com/docs/suppress-issues
# Rules
This trend metric counts the number of active rules. This count includes violated and not violated rules. This count includes critical and non critical rules.
When no baseline is available, rules that rely on diff are not counted. If you observe that this count slightly decreases with no apparent reason, the reason is certainly that rules that rely on diff are not counted because the baseline is not defined.
# Rules Violated
This trend metric counts the number of active rules that are violated. This count includes critical and non critical rules.
When no baseline is available, rules that rely on diff are not counted. If you observe that this count slightly decreases with no apparent reason, the reason is certainly that rules that rely on diff are not counted because the baseline is not defined.
# Critical Rules Violated
This trend metric counts the number of critical active rules that are violated.
The concept of critical rule is useful to pinpoint certain rules that should not be violated.
When no baseline is available, rules that rely on diff are not counted. If you observe that this count slightly decreases with no apparent reason, the reason is certainly that rules that rely on diff are not counted because the baseline is not defined.
# Quality Gates
This trend metric counts the number of active quality gates, no matter the gate status (Pass, Warn, Fail).
When no baseline is available, quality gates that rely on diff are not counted. If you observe that this count slightly decreases with no apparent reason, the reason is certainly that quality gates that rely on diff are not counted because the baseline is not defined.
# Quality Gates Warn
This trend metric counts the number of active quality gates that warns.
When no baseline is available, quality gates that rely on diff are not counted. If you observe that this count slightly decreases with no apparent reason, the reason is certainly that quality gates that rely on diff are not counted because the baseline is not defined.
# Quality Gates Fail
This trend metric counts the number of active quality gates that fails.
When no baseline is available, quality gates that rely on diff are not counted. If you observe that this count slightly decreases with no apparent reason, the reason is certainly that quality gates that rely on diff are not counted because the baseline is not defined.
Percentage Debt (Metric)
This Trend Metric name is suffixed with (Metric) to avoid query name collision with the Quality Gate with same name.
Infer a percentage from:
• the estimated total time to develop the code base
• and the the estimated total time to fix all issues (the Debt).
Estimated total time to develop the code base is inferred from # lines of code of the code base and from the Estimated number of man-day to develop 1000 logical lines of code setting found in NDepend Project Properties > Issue and Debt.
Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
Debt (Metric)
This Trend Metric name is suffixed with (Metric) to avoid query name collision with the Quality Gate with same name.
Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
New Debt since Baseline (Metric)
This Trend Metric name is suffixed with (Metric) to avoid query name collision with the Quality Gate with same name.
Debt added (or fixed if negative) since baseline.
Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
Annual Interest (Metric)
This Trend Metric name is suffixed with (Metric) to avoid query name collision with the Quality Gate with same name.
Annual Interest documentation: https://www.ndepend.com/docs/technical-debt#AnnualInterest
New Annual Interest since Baseline (Metric)
This Trend Metric name is suffixed with (Metric) to avoid query name collision with the Quality Gate with same name.
Annual Interest added (or fixed if negative) since baseline.
Annual Interest documentation: https://www.ndepend.com/docs/technical-debt#AnnualInterest
Breaking Point
The breaking point of a set of issues is the debt divided by the annual interest.
The debt is the estimated cost-to-fix the issues.
The annual interest is the estimated cost-to-not-fix the issues, per year.
Hence the breaking point is the point in time from now, when not fixing the issues cost as much as fixing the issue.
Breaking Point documentation: https://www.ndepend.com/docs/technical-debt#BreakingPoint
Breaking Point of Blocker / Critical / High Issues
The breaking point of a set of issues is the debt divided by the annual interest.
The debt is the estimated cost-to-fix the issues.
The annual interest is the estimated cost-to-not-fix the issues, per year.
Hence the breaking point is the point in time from now, when not fixing the issues cost as much as fixing the issue.
Breaking Point documentation: https://www.ndepend.com/docs/technical-debt#BreakingPoint
# Source Files
This trend metric counts the number of source files.
If a value 0 is obtained, it means that at analysis time, assemblies PDB files were not available. https://www.ndepend.com/docs/ndepend-analysis-inputs-explanation
So far source files cannot be matched by a code query. However editing the query "Application Types" and then Group by source file declarations will list source files with types source declarations.
# Line Feed
This trend metric counts the number of line feed in all source files analyzed.
In other words this is the number of physical lines of code while the trend metric # Lines of Code counts the number of logical lines of code (see https://www.ndepend.com/docs/code-metrics#NbLinesOfCode).
# Lines of Comments
This trend metric returns the number of lines of comment counted in application source files.
So far commenting information is only extracted from C# source code and VB.NET support is planned.
Percentage of Comments
This trend metric returns the percentage of comment compared to the number of logicallines of code.
So far commenting information is only extracted from C# source code and VB.NET support is planned.
# Assemblies
This trend metric query counts all application assemblies. For each assembly it shows the estimated all technical-debt and all issues. All means debt and issues of the assembly and of its child namespaces, types and members.
# Namespaces
This trend metric query counts all application namespaces. For each namespace it shows the estimated all technical-debt and all issues. All means debt and issues of the namespace and of its child types and members.
# Types
This trend metric query counts all application types non-generated by compiler. For each type it shows the estimated all technical-debt and all issues. All means debt and issues of the type and of its child members.
# Methods
This trend metric query counts all application methods non-generated by compiler. For each method it shows the estimated technical-debt and the issues.
# Fields
This trend metric query counts all application fields non-generated by compiler that are not enumeration values nor constant values. For each field it shows the estimated technical-debt and the issues.
# Lines of Code Uncoverable
This code query returns the number of lines of code Uncoverable. This represents the sum of lines of code in both methods whose coverage data is not available in code coverage file imported and methods explicitly excluded from code coverage.
A method, type or assembly can be excluded from coverage either by using a .runsettings file, or by using an Uncoverable attribute.
A .runsettings file can be specified through: NDepend Project Properties > Analysis > Code Coverage > Settings > Exclusion Coverage File
Typically the attribute System.Diagnostics.CodeAnalysis.ExcludeFromCodeCoverageAttribute is used as the Uncoverable attribute.
An additional custom Uncoverable attribute can be defined in the: NDepend Project Properties > Analysis > Code Coverage > Settings > Un-Coverable attributes.
If coverage is imported from VS coverage technologies those attributes are also considered as Uncoverable attribute: System.Diagnostics.DebuggerNonUserCodeAttribute System.Diagnostics.DebuggerHiddenAttribute.
If coverage data imported at analysis time is not in-sync with the analyzed code base, this query will also list methods not defined in the coverage data imported.
# Lines of Code in Types 100% Covered
A line of code covered by tests is even more valuable if it is in a type 100% covered by test.
Covering 90% of a class is not enough.
• It means that this 10% uncovered code is hard-to-test,
• which means that this code is not well-designed,
• which means that it is error-prone.
Better test error-prone code, isn't it?
# Lines of Code in Methods 100% Covered
The same remark than in the Trend Metric # Lines of Code in Types 100% Covered applies for method 100% covered.
A line of code covered by tests is even more valuable if it is in a method 100% covered by test.
Max C.R.A.P Score
Change Risk Analyzer and Predictor (i.e. CRAP) is a code metric that helps in pinpointing overly complex and untested code. Is has been first defined here: http://www.artima.com/weblogs/viewpost.jsp?thread=215899
The Formula is: CRAP(m) = CC(m)^2 * (1 – cov(m)/100)^3 + CC(m)
• where CC(m) is the cyclomatic complexity of the method m
• and cov(m) is the percentage coverage by tests of the method m
Matched methods cumulates two highly error prone code smells:
• A complex method, difficult to develop and maintain.
• Non 100% covered code, difficult to refactor without any regression bug.
The higher the CRAP score, the more painful to maintain and error prone is the method.
An arbitrary threshold of 30 is fixed for this code rule as suggested by inventors.
Notice that no amount of testing will keep methods with a Cyclomatic Complexity higher than 30, out of CRAP territory.
Notice that CRAP score is not computed for too short methods with less than 10 lines of code.
To list methods with higher C.R.A.P scores, please refer to the default rule: Test and Code Coverage > C.R.A.P method code metric
Average C.R.A.P Score
Change Risk Analyzer and Predictor (i.e. CRAP) is a code metric that helps in pinpointing overly complex and untested code. Is has been first defined here: http://www.artima.com/weblogs/viewpost.jsp?thread=215899
The Formula is: CRAP(m) = CC(m)^2 * (1 – cov(m)/100)^3 + CC(m)
• where CC(m) is the cyclomatic complexity of the method m
• and cov(m) is the percentage coverage by tests of the method m
Matched methods cumulates two highly error prone code smells:
• A complex method, difficult to develop and maintain.
• Non 100% covered code, difficult to refactor without any regression bug.
The higher the CRAP score, the more painful to maintain and error prone is the method.
An arbitrary threshold of 30 is fixed for this code rule as suggested by inventors.
Notice that no amount of testing will keep methods with a Cyclomatic Complexity higher than 30, out of CRAP territory.
Notice that CRAP score is not computed for too short methods with less than 10 lines of code.
To list methods with higher C.R.A.P scores, please refer to the default rule: Test and Code Coverage > C.R.A.P method code metric
New assemblies
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists assemblies that have been added since the baseline.
Assemblies removed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists assemblies that have been removed since the baseline.
Assemblies where code was changed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists assemblies in which, code has been changed since the baseline.
New namespaces
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists namespaces that have been added since the baseline.
Namespaces removed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists namespaces that have been removed since the baseline.
Namespaces where code was changed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists namespaces in which, code has been changed since the baseline.
New types
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists types that have been added since the baseline.
Types removed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists types that have been removed since the baseline.
Types where code was changed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists types in which, code has been changed since the baseline.
To visualize changes in code, right-click a matched type and select:
• Compare older and newer versions of source file
• Compare older and newer versions decompiled with Reflector
Heuristic to find types moved from one namespace or assembly to another
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists types moved from one namespace or assembly to another. The heuristic implemented consists in making a join LINQ query on type name (without namespace prefix), applied to the two sets of types added and types removed.
Types directly using one or several types changed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists types unchanged since the baseline but that use directly some types where code has been changed since the baseline.
For such matched type, the code hasen't been changed, but still the overall behavior might have been changed.
The query result includes types changed directly used,
Types indirectly using one or several types changed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists types unchanged since the baseline but that use directly or indirectly some types where code has been changed since the baseline.
For such matched type, the code hasen't been changed, but still the overall behavior might have been changed.
The query result includes types changed directly used, and the depth of usage of types indirectly used, depth of usage as defined in the documentation of DepthOfIsUsingAny() NDepend API method: https://www.ndepend.com/api/webframe.html#NDepend.API~NDepend.CodeModel.ExtensionMethodsSequenceUsage~DepthOfIsUsingAny.html
New methods
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists methods that have been added since the baseline.
Methods removed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists methods that have been removed since the baseline.
Methods where code was changed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists methods in which, code has been changed since the baseline.
To visualize changes in code, right-click a matched method and select:
• Compare older and newer versions of source file
• Compare older and newer versions decompiled with Reflector
Methods directly calling one or several methods changed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists methods unchanged since the baseline but that call directly some methods where code has been changed since the baseline.
For such matched method, the code hasen't been changed, but still the overall behavior might have been changed.
The query result includes methods changed directly used,
Methods indirectly calling one or several methods changed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists methods unchanged since the baseline but that use directly or indirectly some methods where code has been changed since the baseline.
For such matched method, the code hasen't been changed, but still the overall behavior might have been changed.
The query result includes methods changed directly used, and the depth of usage of methods indirectly used, depth of usage as defined in the documentation of DepthOfIsUsingAny() NDepend API method: https://www.ndepend.com/api/webframe.html#NDepend.API~NDepend.CodeModel.ExtensionMethodsSequenceUsage~DepthOfIsUsingAny.html
New fields
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists fields that have been added since the baseline.
Fields removed
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists fields that have been removed since the baseline.
Third party types that were not used and that are now used
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists types defined in third-party assemblies, that were not used at baseline time, and that are now used.
Third party types that were used and that are not used anymore
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists types defined in third-party assemblies, that were used at baseline time, and that are not used anymore.
Third party methods that were not used and that are now used
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists methods defined in third-party assemblies, that were not used at baseline time, and that are now used.
Third party methods that were used and that are not used anymore
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists methods defined in third-party assemblies, that were used at baseline time, and that are not used anymore.
Third party fields that were not used and that are now used
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists fields defined in third-party assemblies, that were not used at baseline time, and that are now used.
Third party fields that were used and that are not used anymore
This query is executed only if a baseline for comparison is defined (diff mode).
This code query lists fields defined in third-party assemblies, that were used at baseline time, and that are not used anymore.
Most used types (Rank)
TypeRank values are computed by applying the Google PageRank algorithm on the graph of types' dependencies. Types with high Rank are the most used ones. Not necessarily the ones with the most users types, but the ones used by many types, themselves having a lot of types users.
See the definition of the TypeRank metric here: https://www.ndepend.com/docs/code-metrics#TypeRank
This code query lists the 100 application types with the higher rank.
The main consequence of being used a lot for a type is that each change (both syntax change and behavior change) will result in potentially a lot of pain since most types clients will be impacted.
Hence it is preferable that types with higher TypeRank, are interfaces, that are typically less subject changes.
Also interfaces avoid clients relying on implementations details. Hence, when the behavior of classes implementing an interface changes, this shouldn't impact clients of the interface. This is in essence the Liskov Substitution Principle. http://en.wikipedia.org/wiki/Liskov_substitution_principle
Most used methods (Rank)
MethodRank values are computed by applying the Google PageRank algorithm on the graph of methods' dependencies. Methods with high Rank are the most used ones. Not necessarily the ones with the most callers methods, but the ones called by many methods, themselves having a lot of callers.
See the definition of the MethodRank metric here: https://www.ndepend.com/docs/code-metrics#MethodRank
This code query lists the 100 application methods with the higher rank.
The main consequence of being used a lot for a method is that each change (both signature change and behavior change) will result in potentially a lot of pain since most methods callers will be impacted.
Hence it is preferable that methods with highest MethodRank, are abstract methods, that are typically less subject to signature changes.
Also abstract methods avoid callers relying on implementations details. Hence, when the code of a method implementing an abstract method changes, this shouldn't impact callers of the abstract method. This is in essence the Liskov Substitution Principle. http://en.wikipedia.org/wiki/Liskov_substitution_principle
Most used assemblies (#AssembliesUsingMe)
This code query lists the 100 application and third-party assemblies, with the higher number of assemblies users.
Most used namespaces (#NamespacesUsingMe )
This code query lists the 100 application and third-party namespaces, with the higher number of namespaces users.
Most used types (#TypesUsingMe )
This code query lists the 100 application and third-party types, with the higher number of types users.
Most used methods (#MethodsCallingMe )
This code query lists the 100 application and third-party methods, with the higher number of methods callers.
Namespaces that use many other namespaces (#NamespacesUsed )
This code query lists the 100 application namespaces with the higher number of namespaces used.
Types that use many other types (#TypesUsed )
This code query lists the 100 application types with the higher number of types used.
Methods that use many other methods (#MethodsCalled )
This code query lists the 100 application methods with the higher number of methods called.
High-level to low-level assemblies (Level)
This code query lists assemblies ordered by Level values. See the definition of the AssemblyLevel metric here: https://www.ndepend.com/docs/code-metrics#Level
High-level to low-level namespaces (Level)
This code query lists namespaces ordered by Level values. See the definition of the NamespaceLevel metric here: https://www.ndepend.com/docs/code-metrics#Level
High-level to low-level types (Level)
This code query lists types ordered by Level values. See the definition of the TypeLevel metric here: https://www.ndepend.com/docs/code-metrics#Level
High-level to low-level methods (Level)
This code query lists methods ordered by Level values. See the definition of the MethodLevel metric here: https://www.ndepend.com/docs/code-metrics#Level
Check that the assembly Asm1 is not using the assembly Asm2
This rule is a sample rule that can be adapted to your need.
It shows how to be warned if a particular assembly is using another particular assembly.
Such rule can be generated for assemblies A and B:
• by right clicking the cell in the Dependency Matrix with B in row and A in column,
• or by right-clicking the concerned arrow in the Dependency Graph from A to B,
and in both cases, click the menu Generate a code rule that warns if this dependency exists
The generated rule will look like this one. It is now up to you to adapt this rule to check exactly your needs.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the namespace N1.N2 is not using the namespace N3.N4.N5
This rule is a sample rule that can be adapted to your need.
It shows how to be warned if a particular namespace is using another particular namespace.
Such rule can be generated for namespaces A and B:
• by right clicking the cell in the Dependency Matrix with B in row and A in column,
• or by right-clicking the concerned arrow in the Dependency Graph from A to B,
and in both cases, click the menu Generate a code rule that warns if this dependency exists
The generated rule will look like this one. It is now up to you to adapt this rule to check exactly your needs.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the assembly Asm1 is only using the assemblies Asm2, Asm3 or System.Runtime
This rule is a sample rule that can be adapted to your need.
It shows how to enforce that a particular assembly is only using a particular set of assemblies.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the namespace N1.N2 is only using the namespaces N3.N4, N5 or System
This rule is a sample rule that can be adapted to your need.
It shows how to enforce that a particular namespace is only using a particular set of namespaces.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that AsmABC is the only assembly that is using System.Collections.Concurrent
This rule is a sample rule that can be adapted to your need.
It shows how to enforce that a particular assembly is only used by another particular assembly.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that only 3 assemblies are using System.Collections.Concurrent
This rule is a sample rule that can be adapted to your need.
It shows how to enforce that a particular assembly is only used by 3 any others assemblies.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that all methods that call Foo.Fct1() also call Foo.Fct2(Int32)
This rule is a sample rule that can be adapted to your need.
It shows how to enforce that if a method calls a particular method, it must call another particular method.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that all types that derive from Foo, also implement IFoo
This rule is a sample rule that can be adapted to your need.
It shows how to enforce that all classes that derive from a particular base class, also implement a particular interface.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that all types that has the attribute FooAttribute are declared in the namespace N1.N2*
This rule is a sample rule that can be adapted to your need.
It shows how to enforce that all types that are tagged with a particular attribute, are declared in a particular namespace.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that all synchronization objects are only used from the namespaces under MyNamespace.Sync
This rule is a sample rule that can be adapted to your need.
It shows how to enforce that all synchronization objects are used from a particular namespace.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the namespace N1.N2 is 100% covered by tests
This is a sample rule that shows how to check if a particular namespace is 100% covered by tests. Both the string @"N1.N2" and the threshold 100 can be adapted to your own needs.
To execute this sample rule, coverage data must be imported. More info here: https://www.ndepend.com/docs/code-coverage
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the assembly Asm is 100% covered by tests
This is a sample rule that shows how to check if a particular assembly is 100% covered by tests. Both the string @"Asm" and the threshold 100 can be adapted to your own needs.
To execute this sample rule, coverage data must be imported. More info here: https://www.ndepend.com/docs/code-coverage
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the class Namespace.Foo is 100% covered by tests
This is a sample rule that shows how to check if a particular class is 100% covered by tests. Both the string @"Namespace.Foo" and the threshold 100 can be adapted to your own needs.
To execute this sample rule, coverage data must be imported. More info here: https://www.ndepend.com/docs/code-coverage
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the method Namespace.Foo.Method(Int32) is 100% covered by tests
This is a sample rule that shows how to check if a particular method is 100% covered by tests. Both the string @"Namespace.Foo.Method(Int32)" and the threshold 100 can be adapted to your own needs.
To execute this sample rule, coverage data must be imported. More info here: https://www.ndepend.com/docs/code-coverage
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that all types that derive from Foo, has a name that ends up with Foo
This rule is a sample rule that can be adapted to your need.
It shows how to enforce that all classes that derive from a particular class, are named with a particular suffix.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that all namespaces begins with CompanyName.ProductName
A practice widely adopted is that, in a product source code, all namespaces start with "CompanyName.ProductName".
This rule must be adapted with your own "CompanyName.ProductName".
How to Fix:
Update all namespaces definitions in source code to satisfy this rule.

./rules/assets/img/QualityGateStatusPass32x32.png
Quality Gates Evolution - Quality Gates
When a quality gate relies on diff between now and baseline (like New Debt since Baseline) it is not executed against the baseline and as a consequence its evolution is not available.
Double-click a quality gate for editing.
Percentage Coverage - Quality Gates
Code coverage is certainly the most important quality code metric. But coverage is not enough the team needs to ensure that results are checked at test-time. These checks can be done both in test code, and in application code through assertions. The important part is that a test must fail explicitly when a check gets unvalidated during the test execution.
This quality gate defines a warn threshold (80%) and a fail threshold (70%). These are indicative thresholds and in practice the more the better. To achieve high coverage and low risk, make sure that new and refactored classes gets 100% covered by tests and that the application and test code contains as many checks/assertions as possible.
Percentage Coverage on New Code - Quality Gates
To achieve high code coverage it is essential that new code gets properly tested and covered by tests. It is advised that all non-UI new classes gets 100% covered.
Typically 90% of a class is easy to cover by tests and 10% is hard to reach through tests. It means that this 10% remaining is not easily testable, which means it is not well designed, which often means that this code is especially error-prone. This is the reason why it is important to reach 100% coverage for a class, to make sure that potentially error-prone code gets tested.
Percentage Coverage on Refactored Code - Quality Gates
Comment changes and formatting changes are not considered as refactoring.
To achieve high code coverage it is essential that refactored code gets properly tested and covered by tests. It is advised that when refactoring a class or a method, it is important to also write tests to make sure it gets 100% covered.
Typically 90% of a class is easy to cover by tests and 10% is hard to reach through tests. It means that this 10% remaining is not easily testable, which means it is not well designed, which often means that this code is especially error-prone. This is the reason why it is important to reach 100% coverage for a class, to make sure that potentially error-prone code gets tested.
Blocker Issues - Quality Gates
The severity of an issue is either defined explicitly in the rule source code, either inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > Issue and Debt.
Critical Issues - Quality Gates
The severity of an issue is either defined explicitly in the rule source code, either inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > Issue and Debt.
New Blocker / Critical / High Issues - Quality Gates
An issue with a severity level Critical shouldn't move to production. It still can for business imperative needs purposes, but at worth it must be fixed during the next iterations.
An issue with a severity level High should be fixed quickly, but can wait until the next scheduled interval.
The severity of an issue is either defined explicitly in the rule source code, either inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > Issue and Debt.
Critical Rules Violated - Quality Gates
A rule can be made critical just by checking the Critical button in the rule edition control and then saving the rule.
This quality gate fails if any critical rule gets any violations.
When no baseline is available, rules that rely on diff are not counted. If you observe that this quality gate count slightly decreases with no apparent reason, the reason is certainly that rules that rely on diff are not counted because the baseline is not defined.
Treat Compiler Warnings as Error - Quality Gates
Also, this approach encourages developers to follow best coding practices and to use language features correctly. It helps in maintaining a high standard of coding within a team, especially in projects with multiple contributors.
This Quality Gate requires Roslyn or R# Analyzers issues to be imported: https://www.ndepend.com/docs/roslyn-analyzer-issue-import https://www.ndepend.com/docs/resharper-code-inspection-issue-import
C# and VB.NET compiler warnings are Roslyn Analyzers issues whose rule id starts with "CS" or "VB".
This Quality Gate warns if there are any such warning. It fails if there are 10 or more such warnings.
See list of C# compiler warnings here: https://learn.microsoft.com/en-us/dotnet/csharp/misc/cs0183
Percentage Debt - Quality Gates
• the estimated total effort to develop the code base
• and the the estimated total time to fix all issues (the Debt)
Estimated total effort to develop the code base is inferred from # lines of code of the code base and from the Estimated number of man-day to develop 1000 logical lines of code setting found in NDepend Project Properties > Issue and Debt.
Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
This quality gates fails if the estimated debt is more than 30% of the estimated effort to develop the code base, and warns if the estimated debt is more than 20% of the estimated effort to develop the code base
Debt - Quality Gates
However you can refer to the default Quality Gate Percentage Debt.
The Debt is defined as the sum of estimated effort to fix all issues. Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
New Debt since Baseline - Quality Gates
This Quality Gate warns if this estimated effort is positive.
Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
Debt Rating per Namespace - Quality Gates
The Debt Rating for a code element is estimated by the value of the Debt Ratio and from the various rating thresholds defined in this project Debt Settings.
The Debt Ratio of a code element is a percentage of Debt Amount (in floating man-days) compared to the estimated effort to develop the code element (also in floating man-days).
The estimated effort to develop the code element is inferred from the code elements number of lines of code, and from the project Debt Settings parameters estimated number of man-days to develop 1000 logical lines of code.
The logical lines of code corresponds to the number of debug breakpoints in a method and doesn't depend on code formatting nor comments.
The Quality Gate can be modified to match assemblies, types or methods with a poor Debt Rating, instead of matching namespaces.
Annual Interest - Quality Gates
However you can refer to the default Quality Gate New Annual Interest since Baseline.
The Annual-Interest is defined as the sum of estimated annual cost in man-days, to leave all issues unfixed.
Each rule can either provide a formula to compute the Annual-Interest per issue, or assign a Severity level for each issue. Some thresholds defined in Project Properties > Issue and Debt > Annual Interest are used to infer an Annual-Interest value from a Severity level. Annual Interest documentation: https://www.ndepend.com/docs/technical-debt#AnnualInterest
New Annual Interest since Baseline - Quality Gates
This Quality Gate warns if this estimated annual cost is positive.
This estimated annual cost is named the Annual-Interest.
Each rule can either provide a formula to compute the Annual-Interest per issue, or assign a Severity level for each issue. Some thresholds defined in Project Properties > Issue and Debt > Annual Interest are used to infer an Annual-Interest value from a Severity level. Annual Interest documentation: https://www.ndepend.com/docs/technical-debt#AnnualInterest
Unnecessary NDepend SuppressMessageAttribute Usage - Quality Gates
Note: This quality gate is disabled by default, as it is intended for advanced NDepend usage only.
Doc: https://www.ndepend.com/docs/suppress-issues
Types Hot Spots - Hot Spots
Both issues on the type and its members are taken account.
Since untested code often generates a lot of Debt, the type size and percentage coverage is shown (just uncomment t.PercentageCoverage in the query source code once you've imported the coverage data).
The Debt Rating and Debt Ratio are also shown for informational purpose.
--
The amount of Debt is not a measure to prioritize the effort to fix issues, it is an estimation of how far the team is from clean code that abides by the rules set.
For each issue the Annual Interest estimates the annual cost to leave the issues unfixed. The Severity of an issue is estimated through thresholds from the Annual Interest.
The Debt Breaking Point represents the duration from now when the estimated cost to leave the issue unfixed costs as much as the estimated effort to fix it.
Hence the shorter the Debt Breaking Point the largest the Return on Investment for fixing the issue. The Breaking Point is the right metric to prioritize issues fix.
Types to Fix Priority - Hot Spots
For each issue the Debt estimates the effort to fix the issue, and the Annual Interest estimates the annual cost to leave the issue unfixed. The Severity of an issue is estimated through thresholds from the Annual Interest of the issue.
The Debt Breaking Point represents the duration from now when the estimated cost to leave the issue unfixed costs as much as the estimated effort to fix it.
Hence the shorter the Debt Breaking Point the largest the Return on Investment for fixing the issues.
Often new and refactored types since baseline will be listed first, because issues on these types get a higher Annual Interest because it is important to focus first on new issues.
--
Both issues on the type and its members are taken account.
Only types with at least 30 minutes of Debt are listed to avoid polluting the list with the numerous types with small Debt, on which the Breaking Point value makes less sense.
The Annual Interest estimates the cost per year in man-days to leave these issues unfixed.
Since untested code often generates a lot of Debt, the type size and percentage coverage is shown (just uncomment t.PercentageCoverage in the query source code once you've imported the coverage data).
The Debt Rating and Debt Ratio are also shown for informational purpose.
Issues to Fix Priority - Hot Spots
Double-click an issue to edit its rule and select the issue in the rule result. This way you can view all information concerning the issue.
For each issue the Debt estimates the effort to fix the issue, and the Annual Interest estimates the annual cost to leave the issue unfixed. The Severity of an issue is estimated through thresholds from the Annual Interest of the issue.
The Debt Breaking Point represents the duration from now when the estimated cost to leave the issue unfixed costs as much as the estimated effort to fix it.
Hence the shorter the Debt Breaking Point the largest the Return on Investment for fixing the issue.
Often issues on new and refactored code elements since baseline will be listed first, because such issues get a higher Annual Interest because it is important to focus first on new issues on recent code.
More documentation: https://www.ndepend.com/docs/technical-debt
Debt and Issues per Rule - Hot Spots
A rule violated has issues. For each issue the Debt estimates the effort to fix the issue.
--
The amount of Debt is not a measure to prioritize the effort to fix issues, it is an estimation of how far the team is from clean code that abides by the rules set.
For each issue the Annual Interest estimates the annual cost to leave the issues unfixed. The Severity of an issue is estimated through thresholds from the Annual Interest.
The Debt Breaking Point represents the duration from now when the estimated cost to leave the issue unfixed costs as much as the estimated effort to fix it.
Hence the shorter the Debt Breaking Point the largest the Return on Investment for fixing the issue. The Breaking Point is the right metric to prioritize issues fix.
--
Notice that rules can be grouped in Rule Category. This way you'll see categories that generate most Debt.
Typically the rules that generate most Debt are the ones related to Code Coverage by Tests, Architecture and Code Smells.
More documentation: https://www.ndepend.com/docs/technical-debt
New Debt and Issues per Rule - Hot Spots
A rule violated has issues. For each issue the Debt estimates the effort to fix the issue.
--
New issues since the baseline are consequence of recent code refactoring sessions. They represent good opportunities of fix because the code recently refactored is fresh in the developers mind, which means fixing now costs less than fixing later.
Fixing issues on recently touched code is also a good way to foster practices that will lead to higher code quality and maintainability, including writing unit-tests and avoiding unnecessary complex code.
--
Notice that rules can be grouped in Rule Category. This way you'll see categories that generate most Debt.
Typically the rules that generate most Debt are the ones related to Code Coverage by Tests, Architecture and Code Smells.
More documentation: https://www.ndepend.com/docs/technical-debt
Debt and Issues per Code Element - Hot Spots
For each code element the Debt estimates the effort to fix the element issues.
The amount of Debt is not a measure to prioritize the effort to fix issues, it is an estimation of how far the team is from clean code that abides by the rules set.
For each element the Annual Interest estimates the annual cost to leave the elements issues unfixed. The Severity of an issue is estimated through thresholds from the Annual Interest of the issue.
The Debt Breaking Point represents the duration from now when the estimated cost to leave the issues unfixed costs as much as the estimated effort to fix it.
Hence the shorter the Debt Breaking Point the largest the Return on Investment for fixing the issue. The Breaking Point is the right metric to prioritize issues fix.
New Debt and Issues per Code Element - Hot Spots
For each code element the Debt estimates the effort to fix the element issues.
New issues since the baseline are consequence of recent code refactoring sessions. They represent good opportunities of fix because the code recently refactored is fresh in the developers mind, which means fixing now costs less than fixing later.
Fixing issues on recently touched code is also a good way to foster practices that will lead to higher code quality and maintainability, including writing unit-tests and avoiding unnecessary complex code.
Avoid types too big - Code Smells
Types where NbLinesOfCode > 200 are extremely complex to develop and maintain. See the definition of the NbLinesOfCode metric here https://www.ndepend.com/docs/code-metrics#NbLinesOfCode
Maybe you are facing the God Class phenomenon: A God Class is a class that controls way too many other classes in the system and has grown beyond all logic to become The Class That Does Everything.
How to Fix:
Types with many lines of code should be split in a group of smaller types.
To refactor a God Class you'll need patience, and you might even need to recreate everything from scratch. Here are a few refactoring advices:
• The logic in the God Class must be split in smaller classes. These smaller classes can eventually become private classes nested in the original God Class, whose instances objects become composed of instances of smaller nested classes.
• Smaller classes partitioning should be driven by the multiple responsibilities handled by the God Class. To identify these responsibilities it often helps to look for subsets of methods strongly coupled with subsets of fields.
• If the God Class contains way more logic than states, a good option can be to define one or several static classes that contains no static field but only pure static methods. A pure static method is a function that computes a result only from inputs parameters, it doesn't read nor assign any static or instance field. The main advantage of pure static methods is that they are easily testable.
• Try to maintain the interface of the God Class at first and delegate calls to the new extracted classes. In the end the God Class should be a pure facade without its own logic. Then you can keep it for convenience or throw it away and start to use the new classes only.
• Unit Tests can help: write tests for each method before extracting it to ensure you don't break functionality.
The estimated Debt, which means the effort to fix such issue, varies linearly from 1 hour for a 200 lines of code type, up to 10 hours for a type with 2.000 or more lines of code.
In Debt and Interest computation, this rule takes account of the fact that static types with no mutable fields are just a collection of static methods that can be easily split and moved from one type to another.
Avoid types with too many methods - Code Smells
This rule doesn't match type with at least a non-constant field because it is ok to have a class with many stateless methods
Notice that methods like constructors or property and event accessors are not taken account.
Having many methods for a type might be a symptom of too many responsibilities implemented.
Maybe you are facing the God Class phenomenon: A God Class is a class that controls way too many other classes in the system and has grown beyond all logic to become The Class That Does Everything.
How to Fix:
To refactor properly a God Class please read HowToFix advices from the default rule Types too Big.
The estimated Debt, which means the effort to fix such issue, varies linearly from 1 hour for a type with 20 methods, up to 10 hours for a type with 200 or more methods.
In Debt and Interest computation, this rule takes account of the fact that static types with no mutable fields are just a collection of static methods that can be easily split and moved from one type to another.
Avoid types with too many fields - Code Smells
Notice that constant fields and static-readonly fields are not counted. Enumerations types are not counted also.
Having many fields for a type might be a symptom of too many responsibilities implemented.
How to Fix:
To refactor such type and increase code quality and maintainability, certainly you'll have to group subsets of fields into smaller types and dispatch the logic implemented into the methods into these smaller types.
More refactoring advices can be found in the default rule Types to Big, HowToFix section.
The estimated Debt, which means the effort to fix such issue, varies linearly from 1 hour for a type with 15 fields, to up to 10 hours for a type with 200 or more fields.
Avoid methods too big, too complex - Code Smells
Maybe you are facing the God Method phenomenon. A "God Method" is a method that does way too many processes in the system and has grown beyond all logic to become The Method That Does Everything. When the need for new processes increases suddenly some programmers realize: why should I create a new method for each process if I can only add an if.
See the definition of the CyclomaticComplexity metric here: https://www.ndepend.com/docs/code-metrics#CC
See the definition of the ILNestingDepth metric here: https://www.ndepend.com/docs/code-metrics#ILNestingDepth
How to Fix:
A large and complex method should be split in smaller methods, or even one or several classes can be created for that.
During this process it is important to question the scope of each variable local to the method. This can be an indication if such local variable will become an instance field of the newly created class(es).
Large switch…case structures might be refactored through the help of a set of types that implement a common interface, the interface polymorphism playing the role of the switch cases tests.
Unit Tests can help: write tests for each method before extracting it to ensure you don't break functionality.
The estimated Debt, which means the effort to fix such issue, varies from 20 minutes to 3 hours, linearly from a weighted complexity score.
Avoid methods with too many parameters - Code Smells
This rule doesn't match a method that overrides a third-party method with 10 or more parameters because such situation is the consequence of a lower-level problem.
For the same reason, this rule doesn't match a constructor that calls a base constructor with 8 or more parameters.
How to Fix:
More properties/fields can be added to the declaring type to handle numerous states. An alternative is to provide a class or a structure dedicated to handle arguments passing. For example see the class System.Diagnostics.ProcessStartInfo and the method System.Diagnostics.Process.Start(ProcessStartInfo).
The estimated Debt, which means the effort to fix such issue, varies linearly from 1 hour for a method with 8 parameters, up to 6 hours for a methods with 40 or more parameters.
Avoid methods with too many overloads - Code Smells
This rule matches sets of methods with 7 overloads or more.
The "too many overloads" phenomenon typically arises when an algorithm accepts a diverse range of input parameters. Each overload is introduced as a means to accommodate a different combination of input parameters.
Such method set might be a problem to maintain and provokes ambiguity and make the code less readable.
The too many overloads phenomenon can also be a consequence of the usage of the visitor design pattern http://en.wikipedia.org/wiki/Visitor_pattern since a method named Visit() must be provided for each sub type. For this reason, the default version of this rule doesn't match overloads whose name start with "visit" or "dispatch" (case-insensitive) to avoid match overload visitors, and you can adapt this rule to your own naming convention.
Sometime too many overloads phenomenon is not the symptom of a problem, for example when a numeric to something conversion method applies to all numeric and nullable numeric types.
See the definition of the NbOverloads metric here https://www.ndepend.com/docs/code-metrics#NbOverloads
Notice that this rule doesn't include in the overloads list methods that override a third-party method nor constructors that call a base constructor. Such situations are consequences of lower-level problems.
How to Fix:
In such situation, the C# language feature optional parameters, named arguments or parameter array (with the params keyword) can be used instead.
The estimated Debt, which means the effort to fix such issue, is of 3 minutes per method overload.
Avoid methods potentially poorly commented - Code Smells
See the definitions of the Comments metric here: https://www.ndepend.com/docs/code-metrics#PercentageComment https://www.ndepend.com/docs/code-metrics#NbLinesOfComment
Notice that only comments about the method implementation (comments in method body) are taken account.
How to Fix:
Typically add more comment. But code commenting is subject to controversy. While poorly written and designed code would needs a lot of comment to be understood, clean code doesn't need that much comment, especially if variables and methods are properly named and convey enough information. Unit-Test code can also play the role of code commenting.
However, even when writing clean and well-tested code, one will have to write hacks at a point, usually to circumvent some API limitations or bugs. A hack is a non-trivial piece of code, that doesn't make sense at first glance, and that took time and web research to be found. In such situation comments must absolutely be used to express the intention, the need for the hacks and the source where the solution has been found.
The estimated Debt, which means the effort to comment such method, varies linearly from 2 minutes for 10 lines of code not commented, up to 20 minutes for 200 or more, lines of code not commented.
Avoid types with poor cohesion - Code Smells
The LCOM metric measures the fact that most methods are using most fields. A class is considered utterly cohesive (which is good) if all its methods use all its instance fields.
Only types with enough methods and fields are taken account to avoid bias. The LCOM takes its values in the range [0-1].
This rule matches types with LCOM higher than 0.84. Such value generally pinpoints a poorly cohesive class.
How to Fix:
To refactor a poorly cohesive type and increase code quality and maintainability, certainly you'll have to split the type into several smaller and more cohesive types that together, implement the same logic.
For each matched type, you can right-click it then click the menu "Show on the Dependency Graph". This way you can visualize how the fields are used by methods and plan the refactoring based on this information.
The estimated Debt, which means the effort to fix such issue, varies linearly from 5 minutes for a type with a low poorCohesionScore, up to 4 hours for a type with high poorCohesionScore.
Avoid methods with too many local variables - Code Smells
Methods where NbVariables > 8 are hard to understand and maintain. Methods where NbVariables > 15 are extremely complex and must be refactored.
The number of variables is inferred from the compiled IL code of the method. The C# and VB.NET compiler might introduce some hidden variables for language constructs like lambdas, so the default threshold of this rule is set to 15 to avoid matching false positives.
How to Fix:
To refactor such method and increase code quality and maintainability, certainly you'll have to split the method into several smaller methods or even create one or several classes to implement the logic.
During this process it is important to question the scope of each variable local to the method. This can be an indication if such local variable will become an instance field of the newly created class(es).
The estimated Debt, which means the effort to fix such issue, varies linearly from 10 minutes for a method with 15 variables, up to 2 hours for a methods with 80 or more variables.
Avoid unmaintainable code - Code Smells
See the maintainability index, cyclomatic complexity and Halstead volume definitions here:
https://www.ndepend.com/docs/code-metrics#MaintainabilityIndex
https://www.ndepend.com/docs/code-metrics#CC
https://www.ndepend.com/docs/code-metrics#HalsteadVolume
How to Fix:
To resolve this issue, refactor the method by splitting it into smaller, more focused components
From now, all types added should respect basic quality principles - Code Smells Regression
This rule can be easily modified to also match types refactored since baseline, that don't satisfy all quality criteria.
Types matched by this rule not only have been recently added or refactored, but also somehow violate one or several basic quality principles, whether it has too many methods, it has too many fields, or is using too many types. Any of these criteria are often a symptom of a type with too many responsibilities.
Notice that to count methods and fields, methods like constructors or property and event accessors are not taken account. Notice that constants fields and static-readonly fields are not counted. Enumerations types are not counted also.
How to Fix:
To refactor such type and increase code quality and maintainability, certainly you'll have to split the type into several smaller types that together, implement the same logic.
Issues of this rule have a constant 10 minutes Debt, because the Debt, which means the effort to fix such issue, is already estimated for issues of rules in the category Code Smells.
However issues of this rule have a High severity, with even more interests for issues on new types since baseline, because the proper time to increase the quality of these types is now, before they get committed in the next production release.
From now, all types added should be 100% covered by tests - Code Smells Regression
This rule can be easily modified to also match types refactored since baseline, that are not 100% covered by tests.
This rule is executed only if some code coverage data is imported from some code coverage files.
Often covering 10% of remaining uncovered code of a class, requires as much work as covering the first 90%. For this reason, typically teams estimate that 90% coverage is enough. However untestable code usually means poorly written code which usually leads to error prone code. So it might be worth refactoring and making sure to cover the 10% remaining code because most tricky bugs might come from this small portion of hard-to-test code.
Not all classes should be 100% covered by tests (like UI code can be hard to test) but you should make sure that most of the logic of your application is defined in some easy-to-test classes, 100% covered by tests.
In this context, this rule warns when a type added or refactored since the baseline, is not fully covered by tests.
How to Fix:
Write more unit-tests dedicated to cover code not covered yet. If you find some hard-to-test code, it is certainly a sign that this code is not well designed and hence, needs refactoring.
You'll find code impossible to cover by unit-tests, like calls to MessageBox.Show(). An infrastructure must be defined to be able to mock such code at test-time.
Issues of this rule have a constant 10 minutes Debt, because the Debt, which means the effort to write tests for the culprit type, is already estimated for issues in the category Code Coverage.
However issues of this rule have a High severity, with even more interests for issues on new types since baseline, because the proper time to write tests for these types is now, before they get committed in the next production release.
From now, all methods added should respect basic quality principles - Code Smells Regression
This rule can be easily modified to also match methods refactored since baseline, that don't satisfy all quality criteria.
Methods matched by this rule not only have been recently added or refactored, but also somehow violate one or several basic quality principles, whether it is too large (too many lines of code), too complex (too many if, switch case, loops…) has too many variables, too many parameters or has too many overloads.
How to Fix:
To refactor such method and increase code quality and maintainability, certainly you'll have to split the method into several smaller methods or even create one or several classes to implement the logic.
During this process it is important to question the scope of each variable local to the method. This can be an indication if such local variable will become an instance field of the newly created class(es).
Large switch…case structures might be refactored through the help of a set of types that implement a common interface, the interface polymorphism playing the role of the switch cases tests.
Unit Tests can help: write tests for each method before extracting it to ensure you don't break functionality.
Issues of this rule have a constant 5 minutes Debt, because the Debt, which means the effort to fix such issue, is already estimated for issues of rules in the category Code Smells.
However issues of this rule have a High severity, with even more interests for issues on new methods since baseline, because the proper time to increase the quality of these methods is now, before they get committed in the next production release.
Avoid decreasing code coverage by tests of types - Code Smells Regression
This rule is executed only if some code coverage data is imported from some code coverage files.
This rule warns when the number of lines of a type covered by tests decreased since the baseline. In case the type faced some refactoring since the baseline, this loss in coverage is estimated only for types with more lines of code, where # lines of code covered now is lower than # lines of code covered in baseline + the extra number of lines of code.
Such situation can mean that some tests have been removed but more often, this means that the type has been modified, and that changes haven't been covered properly by tests.
To visualize changes in code, right-click a matched type and select:
• Compare older and newer versions of source file
• or Compare older and newer versions decompiled with Reflector
How to Fix:
Write more unit-tests dedicated to cover changes in matched types not covered yet. If you find some hard-to-test code, it is certainly a sign that this code is not well designed and hence, needs refactoring.
The estimated Debt, which means the effort to cover by test code that used to be covered, varies linearly 15 minutes to 3 hours, depending on the number of lines of code that are not covered by tests anymore.
Severity of issues of this rule varies from High to Critical depending on the number of lines of code that are not covered by tests anymore. Because the loss in code coverage happened since the baseline, the severity is high because it is important to focus on these issues now, before such code gets released in production.
Avoid making complex methods even more complex - Code Smells Regression
The method complexity is measured through the code metric Cyclomatic Complexity defined here: https://www.ndepend.com/docs/code-metrics#CC
This rule warns when a method already complex (i.e with Cyclomatic Complexity higher than 6) become even more complex since the baseline.
This rule needs assemblies PDB files and source code to be available at analysis time, because the Cyclomatic Complexity is inferred from the source code and source code location is inferred from PDB files. See: https://www.ndepend.com/docs/ndepend-analysis-inputs-explanation
To visualize changes in code, right-click a matched method and select:
• Compare older and newer versions of source file
• or Compare older and newer versions decompiled with Reflector
How to Fix:
A large and complex method should be split in smaller methods, or even one or several classes can be created for that.
During this process it is important to question the scope of each variable local to the method. This can be an indication if such local variable will become an instance field of the newly created class(es).
Large switch…case structures might be refactored through the help of a set of types that implement a common interface, the interface polymorphism playing the role of the switch cases tests.
Unit Tests can help: write tests for each method before extracting it to ensure you don't break functionality.
The estimated Debt, which means the effort to fix such issue, varies linearly from 15 to 60 minutes depending on the extra complexity added.
Issues of this rule have a High severity, because it is important to focus on these issues now, before such code gets released in production.
Avoid making large methods even larger - Code Smells Regression
This rule warns when a method already large (i.e with more than 15 lines of code) become even larger since the baseline.
The method size is measured through the code metric # Lines of Code defined here: https://www.ndepend.com/docs/code-metrics#NbLinesOfCode
This rule needs assemblies PDB files to be available at analysis time, because the # Lines of Code is inferred from PDB files. See: https://www.ndepend.com/docs/ndepend-analysis-inputs-explanation
To visualize changes in code, right-click a matched method and select:
• Compare older and newer versions of source file
• or Compare older and newer versions decompiled with Reflector
How to Fix:
Usually too big methods should be split in smaller methods.
But long methods with no branch conditions, that typically initialize some data, are not necessarily a problem to maintain, and might not need refactoring.
The estimated Debt, which means the effort to fix such issue, varies linearly from 5 to 20 minutes depending on the number of lines of code added.
The estimated Debt, which means the effort to fix such issue, varies linearly from 10 to 60 minutes depending on the extra complexity added.
Issues of this rule have a High severity, because it is important to focus on these issues now, before such code gets released in production.
Avoid adding methods to a type that already had many methods - Code Smells Regression
Types where number of methods is greater than 40 might be hard to understand and maintain.
This rule lists types that already had more than 40 methods at the baseline time, and for which new methods have been added.
Having many methods for a type might be a symptom of too many responsibilities implemented.
Notice that constructors and methods generated by the compiler are not taken account.
How to Fix:
To refactor such type and increase code quality and maintainability, certainly you'll have to split the type into several smaller types that together, implement the same logic.
The estimated Debt, which means the effort to fix such issue, is equal to 10 minutes per method added.
Issues of this rule have a High severity, because it is important to focus on these issues now, before such code gets released in production.
Avoid adding instance fields to a type that already had many instance fields - Code Smells Regression
Types where number of fields is greater than 15 might be hard to understand and maintain.
This rule lists types that already had more than 15 fields at the baseline time, and for which new fields have been added.
Having many fields for a type might be a symptom of too many responsibilities implemented.
Notice that constants fields and static-readonly fields are not taken account. Enumerations types are not taken account also.
How to Fix:
To refactor such type and increase code quality and maintainability, certainly you'll have to group subsets of fields into smaller types and dispatch the logic implemented into the methods into these smaller types.
The estimated Debt, which means the effort to fix such issue, is equal to 10 minutes per field added.
Issues of this rule have a High severity, because it is important to focus on these issues now, before such code gets released in production.
Avoid transforming an immutable type into a mutable one - Code Smells Regression
A type is considered as immutable if its instance fields cannot be modified once an instance has been built by a constructor.
Being immutable has several fortunate consequences for a type. For example its instance objects can be used concurrently from several threads without the need to synchronize accesses.
Hence users of such type often rely on the fact that the type is immutable. If an immutable type becomes mutable, there are chances that this will break users code.
This is why this rule warns about such immutable type that become mutable.
The estimated Debt, which means the effort to fix such issue, is equal to 2 minutes per instance field that became mutable.
How to Fix:
If being immutable is an important property for a matched type, then the code must be refactored to preserve immutability.
The estimated Debt, which means the effort to fix such issue, is equal to 10 minutes plus 10 minutes per instance fields of the matched type that is now mutable.
Issues of this rule have a High severity, because it is important to focus on these issues now, before such code gets released in production.
Avoid interfaces too big - Object Oriented Design
The Interface Segregation Principle (ISP) advises us that when a large interface is used by various consumers, each of which only requires specific methods, unnecessarily coupling those consumers through the same interface can occur.
Furthermore, when dealing with large interfaces, we often end up with larger classes that attempt to handle too many unrelated tasks.
A property with a getter or setter or both count as one member. An event count as one member.
How to Fix:
Typically to fix such issue, the interface must be refactored in a grape of smaller single-responsibility interfaces.
For example if an interface IFoo handles both read and write operations, it can be split into two interfaces: IFooReader and IFooWriter.
A usual problem for a large public interface is that it has many clients that consume it. As a consequence splitting it in smaller interfaces has an important impact and it is not always feasible.
The estimated Debt, which means the effort to fix such issue, varies linearly from 20 minutes for an interface with 10 methods, up to 7 hours for an interface with 100 or more methods. The Debt is divided by two if the interface is not publicly visible, because in such situation only the current project is impacted by the refactoring.
Base class should not use derivatives - Object Oriented Design
Hence a base class should be designed properly to make it easy to derive from, this is extension. But creating a new derived class, or modifying an existing one, shouldn't provoke any modification in the base class. And if a base class is using some derivative classes somehow, there are good chances that such modification will be needed.
Extending the base class is not anymore a simple operation, this is not good design.
Note that this rule doesn't warn when a base class is using a derived class that is nested in the base class and declared as private. In such situation we consider that the derived class is an encapsulated implementation detail of the base class.
How to Fix:
Understand the need for using derivatives, then imagine a new design, and then refactor.
Typically an algorithm in the base class needs to access something from derived classes. You can try to encapsulate this access behind an abstract or a virtual method.
If you see in the base class some conditions on typeof(DerivedClass) not only urgent refactoring is needed. Such condition can easily be replaced through an abstract or a virtual method.
Sometime you'll see a base class that creates instance of some derived classes. In such situation, certainly using the factory method pattern http://en.wikipedia.org/wiki/Factory_method_pattern or the abstract factory pattern http://en.wikipedia.org/wiki/Abstract_factory_pattern will improve the design.
The estimated Debt, which means the effort to fix such issue, is equal to 3 minutes per derived class used by the base class + 3 minutes per member of a derived class used by the base class.
Class shouldn't be too deep in inheritance tree - Object Oriented Design
In theory, there is nothing wrong having a long inheritance chain, if the modeling has been well thought out, if each base class is a well-designed refinement of the domain.
In practice, modeling properly a domain demands a lot of effort and experience and more often than not, a long inheritance chain is a sign of confused design, that is hard to work with and maintain.
How to Fix:
In Object-Oriented Programming, a well-known motto is Favor Composition over Inheritance.
This is because inheritance comes with pitfalls. In general, the implementation of a derived class is very bound up with the base class implementation. Also a base class exposes implementation details to its derived classes, that's why it's often said that inheritance breaks encapsulation.
On the other hands, Composition favors binding with interfaces over binding with implementations. Hence, not only the encapsulation is preserved, but the design is clearer, because interfaces make it explicit and less coupled.
Hence, to break a long inheritance chain, Composition is often a powerful way to enhance the design of the refactored underlying logic.
You can also read: http://en.wikipedia.org/wiki/Composition_over_inheritance and http://stackoverflow.com/questions/49002/prefer-composition-over-inheritance
The estimated Debt, which means the effort to fix such issue, depends linearly upon the depth of inheritance.
Class with no descendant should be sealed if possible - Object Oriented Design
Making a class a base class requires significant design effort. Subclassing a non-sealed class, not initially designed to be subclassed, will lead to unanticipated design issue.
Most classes are non-sealed because developers don't care about the keyword sealed, not because the primary intention was to write a class that can be subclassed.
There are performance gain in declaring a class as sealed. See a benchmark here: https://www.meziantou.net/performance-benefits-of-sealed-class.htm
But the real benefit of doing so, is actually to express the intention: this class has not be designed to be a base class, hence it is not allowed to subclass it.
Notice that by default this rule doesn't match public class to avoid matching classes that are intended to be sub-classed by third-party code using your library. If you are developing an application and not a library, just uncomment the clause !t.IsPubliclyVisible.
How to Fix:
For each matched class, take the time to assess if it is really meant to be subclassed. Certainly most matched class will end up being declared as sealed.
Overrides of Method() should call base.Method() - Object Oriented Design
Violations of this rule are a sign of design flaw, especially if the actual design provides valid reasons that advocates that the base behavior must be replaced and not refined.
How to Fix:
You should investigate if inheritance is the right choice to bind the base class implementation with the derived classes implementations. Does presenting the method with polymorphic behavior through an interface, would be a better design choice?
In such situation, often using the design pattern template method http://en.wikipedia.org/wiki/Template_method_pattern might help improving the design.
Do not hide base class methods - Object Oriented Design
Notice that this is not polymorphic behavior. With polymorphic behavior, calling both base.M() and derived.M() on an instance object of derived, invoke the same implementation.
This situation should be avoided because it obviously leads to confusion. This rule warns about all method hiding cases in the code base.
How to Fix:
To fix a violation of this rule, remove or rename the method, or change the parameter signature so that the method does not hide the base method.
However method hiding is for those times when you need to have two things to have the same name but different behavior. This is a very rare situations, described here: https://learn.microsoft.com/en-us/archive/blogs/ericlippert/method-hiding-apologia
A stateless class or structure might be turned into a static type - Object Oriented Design
Such class or structure is a stateless collection of pure functions, that doesn't act on any this object data. Such collection of pure functions is better hosted in a static class. Doing so simplifies the client code that doesn't have to create an object anymore to invoke the pure functions.
How to Fix:
Declare all methods as static and transform the class or structure into a static class.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Non-static classes should be instantiated or turned to static - Object Oriented Design
However this rule doesn't match instantiation through reflection. As a consequence, plug-in root classes, instantiated through reflection via IoC frameworks, can be false positives for this rule.
This rule doesn't match also classes instantiated by the ASP.NET infrastructure, ASP.NET view model classes and Entity Framework ModelSnapshot, DbContext and Migration classes.
Notice that by default this rule matches also public class. If you are developing a framework with classes that are intended to be instantiated by your clients, just uncomment the line !t.IsPublic.
How to Fix:
First it is important to investigate why the class is never instantiated. If the reason is the class hosts only static methods then the class can be safely declared as static.
Others reasons like, the class is meant to be instantiated via reflection, or is meant to be instantiated only by client code should lead to adapt this rule code to avoid these matches.
Methods should be declared static if possible - Object Oriented Design
Whenever you write a method, you fulfill a contract in a given scope. The narrower the scope is, the smaller the chance is that you write a bug.
When a method is static, you can't access non-static members; hence, your scope is narrower. So, if you don't need and will never need (even in subclasses) instance fields to fulfill your contract, why give access to these fields to your method? Declaring the method static in this case will let the compiler check that you don't use members that you do not intend to use.
Declaring a method as static if possible is also good practice because clients can tell from the method signature that calling the method can't alter the object's state.
Doing so, is also a micro performance optimization, since a static method is a bit cheaper to invoke than an instance method, because the this reference* doesn't need anymore to be passed.
Notice that if a matched method is a handler, bound to an event through code generated by a designer, declaring it as static might break the designer generated code, if the generated code use the this invocation syntax, (like this.Method()).
How to Fix:
Declare matched methods as static.
Since such method doesn't use any instance fields and methods of its type and base-types, you should consider if it makes sense, to move such a method to a static utility class.
Constructor should not call a virtual method - Object Oriented Design
During the construction of a .NET object at runtime, constructors execute sequentially, starting from the base class and progressing to the most derived class.
Objects maintain their type throughout construction; they begin as the most derived type with the method table corresponding to that type. Consequently, virtual method calls always execute on the most derived type, even when called from within the constructor.
Combining these two observations leads to the issue that when you invoke a virtual method within a constructor and the current class is not the most derived type in its inheritance hierarchy, the method will execute on a class whose constructor hasn't been executed yet. This may result in an unsuitable state for the method to be called.
Therefore, this situation renders the class error-prone when deriving from it.
How to Fix:
Issues reported can be solved by re-designing object initialisation or by declaring the parent class as sealed, if possible.
A constructor should primarily focus on initializing the state of its own class. Additional setup can be handled in constructors of derived classes or in dedicated methods called after object construction.
Avoid the Singleton pattern - Object Oriented Design
We advise against using singleton classes because they tend to produce code that is less testable and harder to maintain. Singleton, by design, is not conducive to testing, as it enforces the use of the same instance object across multiple unit tests, limiting the flexibility required for effective testing and maintenance.
Additionally, the static Instance getter method of the singleton pattern provides convenient but uncontrolled access to the single object and its state, leading to code that can become disorganized and messy over time, often requiring refactoring efforts.
This rule applies specifically to singleton types with mutable instance fields because the pitfalls of singletons arise from unregulated access and modification of instance data.
More details available in these discussions: https://blog.ndepend.com/the-proper-usages-of-the-keyword-static-in-c/
How to Fix:
This rule pertains to the usual syntax of singletons, where a single static field holds the instance of the parent class. We emphasize that the issue lies in this specific syntax, which hinders testability. The concern is not having a single instance of the class during runtime.
To address matches for this rule, create the single instance at the program's startup and pass it explicitly to all classes and methods requiring access.
When dealing with multiple singletons, consider consolidating them into a single program execution context. This unified context simplifies propagation across various program units.
The estimated Debt, which means the effort to fix such issue, is equal to 3 minutes per method relying on the singleton. It is not rare that hundreds of methods rely on the singleton and that it takes hours to get rid of a singleton, refactoring the way just explained above.
The severity of each singleton issue is Critical because as explained, using a the singleton pattern can really prevent the whole program to be testable and maintained.
Don't assign static fields from instance methods - Object Oriented Design
More discussion on the topic can be found here: https://blog.ndepend.com/the-proper-usages-of-the-keyword-static-in-c/
How to Fix:
If the static field is just assigned once in the program lifetime, make sure to declare it as readonly and assign it inline, or from the static constructor.
In Object-Oriented-Programming the natural artifact to hold states that can be modified is instance fields.
Hence to fix violations of this rule, make sure to hold assignable states through instance fields, not through static fields.
Avoid empty interfaces - Object Oriented Design
If your design includes empty interfaces that types are expected to implement, you are probably using an interface as a marker or a way to identify a group of types. If this identification will occur at run time, the correct way to accomplish this is to use a custom attribute. Use the presence or absence of the attribute, or the properties of the attribute, to identify the target types. If the identification must occur at compile time, then it is acceptable to use an empty interface.
Note that if an interface is empty but implements at least one other interface, it won't be matched by this rule. Such interface can be considered as not empty, since implementing it means that sub-interfaces members must be implemented.
How to Fix:
Remove the interface or add members to it. If the empty interface is being used to mark a set of types, replace the interface with a custom attribute.
The estimated Debt, which means the effort to fix such issue, is equal to 10 minutes to discard an empty interface plus 3 minutes per type implementing an empty interface.
Avoid types initialization cycles - Object Oriented Design
If the cctor of a type t1 is using the type t2 and if the cctor of t2 is using t1, some type initialization unexpected and hard-to-diagnose buggy behavior can occur. Such a cyclic chain of initialization is not necessarily limited to two types and can embrace N types in the general case. More information on types initialization cycles can be found here: http://codeblog.jonskeet.uk/2012/04/07/type-initializer-circular-dependencies/
The present code rule enumerates types initialization cycles. Some false positives can appear if some lambda expressions are defined in cctors or in methods called by cctors. In such situation, this rule considers these lambda expressions as executed at type initialization time, while it is not necessarily the case.
How to Fix:
Types initialization cycles create confusion and unexpected behaviors. If several states hold by several classes must be initialized during the first access of any of those classes, a better design option is to create a dedicated class whose responsibility is to initialize and hold all these states.
The estimated Debt, which means the effort to fix such issue, is equal to 20 minutes per cycle plus 10 minutes per type class constructor involved in the cycle.
Avoid custom delegates - Design
• Action<…> to represent any method with void return type.
• Func<…> to represent any method with a return type. The last generic argument is the return type of the prototyped methods.
• Predicate<T> to represent any method that takes an instance of T and that returns a boolean.
• Expression<…> that represents function definitions that can be compiled and subsequently invoked at runtime but can also be serialized and passed to remote processes.
Generic delegates not only enhance the clarity of code that uses them but also alleviate the burden of maintaining these delegate types.
Notice that delegates that are consumed by DllImport extern methods must not be converted, else this could provoke marshalling issues.
How to Fix:
Remove custom delegates and replace them with generic delegates shown in the replaceWith column.
The estimated Debt, which means the effort to fix such issue, is 5 minutes per custom delegates plus 3 minutes per method using such custom delegate.
Types with disposable instance fields must be disposable - Design
A class implements the IDisposable interface to dispose of unmanaged resources that it owns. An instance field that is an IDisposable type indicates that the field owns an unmanaged resource. A class that declares an IDisposable field indirectly owns an unmanaged resource and should implement the IDisposable interface. If the class does not directly own any unmanaged resources, it should not implement a finalizer.
This rules might report false positive in case the lifetime of the disposable objects referenced, is longer than the lifetime of the object that hold the disposable references.
How to Fix:
To fix a violation of this rule, implement IDisposable and from the IDisposable.Dispose() method call the Dispose() method of the field(s).
Then for each method calling a constructor of the type, make sure that the Dispose() method is called on all objects created.
The estimated Debt, which means the effort to fix such issue, is 5 minutes per type matched plus 2 minutes per disposable instance field plus 4 minutes per method calling a constructor of the type.
Disposable types with unmanaged resources should declare finalizer - Design
• System.IntPtr
• System.UIntPtr
• System.Runtime.InteropServices.HandleRef
Notice that this default rule is disabled by default, because it typically reports false positive for classes that just hold some references to managed resources, without the responsibility to dispose them.
To enable this rule just uncomment warnif count > 0.
How to Fix:
To fix a violation of this rule, implement a finalizer that calls your Dispose() method.
Methods that create disposable object(s) and that don't call Dispose() - Design
This code query is not a code rule because it is acceptable to do so, as long as disposable objects are disposed somewhere else.
This code query is designed to be be easily refactored to look after only specific disposable types, or specific caller methods.
You can then refactor this code query to adapt it to your needs and transform it into a code rule.
Disposable Types Must Unsubscribe Events - Design
How to Fix:
1) Ensure each constructor event subscription has a matching unsubscription in Dispose() (or in a method always called by Dispose()). 2) Centralize subscriptions/unsubscriptions in dedicated methods to make symmetry explicit and easier to review. 3) If using inheritance, follow the full dispose pattern so derived types can safely release additional event subscriptions. 4) Prefer weak-event patterns or explicit lifetime ownership when publisher lifetime exceeds subscriber lifetime.
Classes that are candidate to be turned into structures - Design
This is a matter of performance. It is expected that a program works with plenty of short lived lightweight values. In such situation, the advantage of using struct instead of class, (in other words, the advantage of using values instead of objects), is that values are not managed by the garbage collector. This means that values are cheaper to deal with.
This rule matches classes that looks like being lightweight values. The characterization of such class is:
• It has instance fields.
• All instance fields are typed with value-types (primitive, structure or enumeration)
• It is immutable (the value of its instance fields cannot be modified once the constructor ended).
• It implements no interfaces.
• It has no parameterless constructor.
• It is not generic.
• It has no derived classes.
• It derives directly from System.Object.
• ASP.NETCore ViewModel (its name ends with Model) and Repository
This rule doesn't take account if instances of matched classes are numerous short-lived objects. These criteria are just indications. Only you can decide if it is performance wise to transform a class into a structure.
How to Fix:
Just use the keyword struct instead of the keyword class.
CAUTION: Before applying this rule, make sure to understand the deep implications of transforming a class into a structure explained in this article: https://blog.ndepend.com/class-vs-struct-in-c-making-informed-choices/
The estimated Debt, which means the effort to fix such issue, is 5 minutes per class matched plus one minute per method using such class transformed into a structure.
Avoid namespaces with few types - Design
Make sure that each of your namespaces has a logical organization and that a valid reason exists to put types in a sparsely populated namespace. Because creating numerous detailed namespaces leads to the need for many using clauses in client code.
Namespaces should contain types that are used together in most scenarios. When their applications are mutually exclusive, types should be located in separate namespaces.
Careful namespace organization can also be helpful because it increases the discoverability of a feature. By examining the namespace hierarchy, library consumers should be able to locate the types that implement a feature.
Notice that this rule source code contains a list of common infrastructure namespace names that you can complete. Namespaces with ending name component in this list are not matched.
How to Fix:
To fix a violation of this rule, try to combine namespaces that contain just a few types into a single namespace.
Nested types should not be visible - Design
A nested type is a type declared within the scope of another type. Nested types are useful for encapsulating private implementation details of the containing type. Used for this purpose, nested types should not be externally visible.
Do not use externally visible nested types for logical grouping or to avoid name collisions; instead use namespaces.
Nested types include the notion of member accessibility, which some programmers do not understand clearly.
Nested types declared as protected can be used in subclasses.
How to Fix:
If you do not intend the nested type to be externally visible, change the type's accessibility.
Otherwise, remove the nested type from its parent and make it non-nested.
If the purpose of the nesting is to group some nested types, use a namespace to create the hierarchy instead.
The estimated Debt, which means the effort to fix such issue, is 2 minutes per nested type plus 4 minutes per outer type using such nesting type.
Declare types in namespaces - Design
Types outside any named namespace are in a global namespace that cannot be referenced in code. Such practice results in naming collisions and ambiguity since types in the global namespace are accessible from anywhere in the code.
Also, placing types within namespaces allows to encapsulate related code and data, providing a level of abstraction and modularity. Global types lack this encapsulation, making it harder to understand the organization and structure of your code.
The global namespace has no name, hence it is qualified as being the anonymous namespace. This rule warns about anonymous namespaces.
How to Fix:
To fix a violation of this rule, declare all types of all anonymous namespaces in some named namespaces.
Empty static constructor can be discarded - Design
This rule warns about the declarations of static constructors that don't contain any lines of code. Such cctors are useless and can be safely removed.
How to Fix:
Remove matched empty static constructors.
Instances size shouldn't be too big - Design
Notice that a class with a large SizeOfInst value doesn't necessarily have a lot of instance fields. It might derive from a class with a large SizeOfInst value.
This query doesn't match types that represent WPF and WindowsForm forms and controls nor Entity Framework special classes.
Some other namespaces like System.ComponentModel or System.Xml have base classes that typically imply large instances size so this rule doesn't match these situations.
This rule doesn't match custom DevExpress component and it is easy to modify this rule ro append other component vendors to avoid false positives.
See the definition of the SizeOfInst metric here https://www.ndepend.com/docs/code-metrics#SizeOfInst
How to Fix:
A type with a large SizeOfInst value hold directly a lot of data. Typically, you can group this data into smaller types that can then be composed.
The estimated Debt, which means the effort to fix such issue, varies linearly from severity Medium for 128 bytes per instance to twice interests for severity High for 2048 bytes per instance.
The estimated annual interest of issues of this rule is 10 times higher for structures, because large structures have a significant performance cost. Indeed, each time such structure value is passed as a method parameter it gets copied to a new local variable (note that the word value is more appropriate than the word instance for structures). For this reason, such structure should be declared as class.
Attribute classes should be sealed - Design
Sealing the attribute removes the need to search through the inheritance hierarchy, which can result in performance improvements.
How to Fix:
To fix a violation of this rule, seal the attribute type or make it abstract.
Don't use obsolete types, methods or fields - Design
This rule warns about methods that use a type, a method or a field, tagged with System.ObsoleteAttribute.
How to Fix:
Typically when a code element is tagged with System.ObsoleteAttribute, a workaround message is provided to clients.
This workaround message will tell you what to do to avoid using the obsolete code element.
The estimated Debt, which means the effort to fix such issue, is 5 minutes per type, method or field used.
Issues of this rule have a severity High because it is important to not rely anymore on obsolete code.
Do implement methods that throw NotImplementedException - Design
The exception NotImplementedException is used to declare a method stub that can be invoked, and defer the development of the method implementation.
This exception is especially useful when doing TDD (Test Driven Development) when tests are written first. This way tests fail until the implementation is written.
Hence using NotImplementedException is a temporary facility, and before releasing, will come a time when this exception shouldn't be used anywhere in code.
NotImplementedException should not be used permanently to mean something like this method should be overriden or this implementation doesn't support this facility. Artefact like abstract method or abstract class should be used instead, to favor a compile time error over a run-time error.
How to Fix:
Investigate why NotImplementedException is still thrown.
Such issue has a High severity if the method code consists only in throwing NotImplementedException. Such situation means either that the method should be implemented, either that what should be a compile time error is a run-time error by-design, and this is not good design. Sometime this situation also pinpoints a method stub that can be safely removed.
If NotImplementedException is thrown from a method with significant logic, the severity is considered as Medium, because often the fix consists in throwing another exception type, like InvalidOperationException.
Override equals and operator equals on value types - Design
If you expect users to compare or sort instances, or use them as hash table keys, your value type should implement Equals(). In C# and VB.NET, you should also provide an implementation of GetHashCode() and of the equality and inequality operators.
How to Fix:
To fix a violation of this rule, provide an implementation of Equals() and GetHashCode() and implement the equality and inequality operators. Alternatively transform it into a record struct.
The estimated Debt, which means the effort to fix such issue, is equal to 15 minutes plus 2 minutes per instance field.
Boxing/unboxing should be avoided - Design
Unboxing extracts the value type from the object. Boxing is implicit; unboxing is explicit.
The concept of boxing and unboxing underlies the C# unified view of the type system in which a value of any type can be treated as an object. More about boxing and unboxing here: https://msdn.microsoft.com/en-us/library/yz2be5wk.aspx
This rule has been disabled by default to avoid noise in issues found by the NDepend default rule set. If boxing/unboxing is important to your team, just re-activate this rule.
How to Fix:
Thanks to .NET generic, and especially thanks to generic collections, boxing and unboxing should be rarely used. Hence in most situations the code can be refactored to avoid relying on boxing and unboxing. See for example: http://stackoverflow.com/questions/4403055/boxing-unboxing-and-generics
With a performance profiler, indentify methods that consume a lot of CPU time. If such method uses boxing or unboxing, especially in a loop, make sure to refactor it.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Avoid namespaces mutually dependent - Architecture
The pair of low and high level namespaces is made of two namespaces that use each other.
For each pair of namespaces, to infer which one is low-level and which one is high-level, the rule computes the two coupling [from A to B] and [from B to A] in terms of number of types, methods and fields involved in the coupling. Typically the coupling from low-level to high-level namespace is significantly lower than the other legitimate coupling.
Following this rule is useful to avoid namespaces dependency cycles. This will get the code architecture close to a layered architecture, where low-level code is not allowed to use high-level code.
In other words, abiding by this rule will help significantly getting rid of what is often called spaghetti code: Entangled code that is not properly layered and structured.
More on this in our white books relative to partitioning code. https://www.ndepend.com/docs/white-books
How to Fix:
Refactor the code to make sure that the low-level namespace doesn't use the high-level namespace.
The rule lists in detail which low-level types and methods shouldn't use which high-level types and methods. The refactoring patterns that help getting rid of each listed dependency include:
• Moving one or several types from the low-level namespaces to the high-level one, or do the opposite.
• Use Dependency Inversion Principle (DIP): https://blog.ndepend.com/solid-design-the-dependency-inversion-principle-dip This consists in creating new interfaces in the low-level namespace, implemented by classes in the high-level namespace. This way low-level code can consume high-level code through interfaces, without using directly high-level implementations. Interfaces can be passed to low-level code through the high-level namespace code, or through even higher-level code. In related documentations you can see these interfaces named as callbacks, and the overall pattern is also known as Dependency Injection (DI): http://en.wikipedia.org/wiki/Dependency_injection
That rule might not be applicable for libraries that present public namespaces mutually dependent. In such situation the cost to break the API can be higher than the cost to let the code entangled.
-
The estimated Debt, which means the effort to fix such issue to make sure that the first namespace doesn't rely anymore on the second one, depends on the number of types and methods used.
Because both namespace are now forming a super-component that cannot be partitioned in smaller components, the cost to unfix each issue is proportional to the size of this super-component. As a consequence, the estimated Annual Interest, which means the annual cost to let both namespaces mutually dependend, is equal to an hour plus a number of minutes proportional to the size (in lines of code) of both namespaces. The obtained Annual Interest value is then divided by the number of detailled issues listed.
Often the estimated Annual Interest for each listed issue is higher than the Debt, which means that leaving such issue unfixed for a year costs more than taking the time to fix issue once.
--
To explore the coupling between the two namespaces mutually dependent:
1) from the becauseNamespace right-click menu choose Copy to Matrix Columns to export this low-level namespace to the horizontal header of the dependency matrix.
2) from the shouldntUseNamespace right-click menu choose Copy to Matrix Rows to export this high-level namespace to the vertical header of the dependency matrix.
3) double-click the black matrix cell (it is black because of the mutual dependency).
4) in the matrix command bar, click the button: Remove empty Row(s) and Column(s).
At this point, the dependency matrix shows types involved into the coupling.
• Blue cells represent types from low-level namespace using types from high-level namespace
• Green cells represent types from high-level namespace using types from low-level namespace
• Black cells represent types from low-level and high-level namespaces that use each other.
There are more green cells than blue and black cells because green cell represents correct coupling from high-level to low-level. The goal is to eliminate incorrect dependencies represented by blue and black cells.
Avoid namespaces dependency cycles - Architecture
Read our white books relative to partitioning code, to know more about namespaces dependency cycles, and why avoiding them is a simple yet efficient solution to clean the architecture of a code base. https://www.ndepend.com/docs/white-books
How to Fix:
Removing first pairs of mutually dependent namespaces will eliminate most namespaces dependency cycles. This is why it is recommended to focus first on matches of the default rule Avoid namespaces mutually dependent before attempting to fix issues of the present rule.
Once all mutually dependent namespaces occurrences are solved, remaining cycles matched by the present rule necessarily involve 3 or more namespaces like in: A is using B is using C is using A.
To browse a cycle on the dependency graph or the dependency matrix, right click a cycle cell in the result of the present rule and export the matched namespaces to the dependency graph or matrix. This is illustrated here: https://www.ndepend.com/docs/visual-studio-dependency-graph#Entangled
With such a cycle graph visualized, you can determine which dependencies should be discarded to break the cycle. To do so, you need to identify which namespace should be at low-level and which one should be at high-level.
In the A is using B is using C is using A cycle example, if A should be at low level then C should be at a higher-level than A. As a consequence C shouldn't use A and this dependency should be removed. To remove a dependency you can refer to patterns described in the HowToFix section of the rule Avoid namespaces mutually dependent.
Notice that the dependency matrix can also help visualizing and breaking cycles. In the matrix cycles are represented with red squares and black cells. To easily browse dependency cycles, the dependency matrix comes with an option: Display Direct and Indirect Dependencies. See related documentation here: https://www.ndepend.com/docs/dependency-structure-matrix-dsm#Cycle https://www.ndepend.com/docs/dependency-structure-matrix-dsm#Mutual
The estimated Debt, which means the effort to fix such issue, doesn't depend on the cycle length. First because fixing the rule Avoid namespaces mutually dependent will fix most cycle reported here, second because even a long cycle can be broken by removing a single or a few dependencies.
Avoid partitioning the code base through many small library Assemblies - Architecture
Each compiled assembly represents a DLL file and a project to maintain. Having too many library assemblies is a symptom of considering physical projects as logical components.
We advise having less, and bigger, projects and using the concept of namespaces to define logical components. Benefits are:
• Faster compilation time.
• Faster startup time for your program.
• Clearer Solution Explorer at development time.
• Easier deployment thanks to less files to manage.
• If you are developing a library, less assemblies to reference and manage for your clients.
How to Fix:
Consider using the physical concept of assemblies for physical needs only.
Our white book about Partitioning code base through .NET assemblies and Visual Studio projects explains in details valid and invalid reasons to use assemblies. Download it here: https://www.ndepend.com/Res/NDependWhiteBook_Assembly.pdf
Enforcing Clean Architecture - Architecture
How to Fix:
1) Move business rules used by multiple layers into Domain or Application. 2) Replace direct references to outer layers with abstractions (interfaces) defined in an inner layer. 3) Implement those abstractions in Infrastructure/Presentation and inject them from the composition root. 4) Move DTOs/view models to the boundary layer that owns them, and map at layer boundaries instead of sharing concrete outer-layer types.
UI layer shouldn't use directly DB types - Architecture
This rule first defines the UI layer and the DB framework layer. Second it checks if any UI layer type is using directly any DB framework layer type.
• The DB framework layer is defined as the set of third-party types in the framework ADO.NET, EntityFramework, NHibernate types, that the application is consuming. It is easy to append and suppress any DB framework.
• The UI layer (User Interface Layer) is defined as the set of types that use WPF, Windows Form, ASP.NET.
UI using directly DB frameworks is generally considered as poor design because DB frameworks accesses should be a concept hidden to UI, encapsulated into a dedicated Data Access Layer (DAL).
Notice that per defaut this rule estimates a technical debt proportional to the coupling between the UI and DB types.
How to Fix:
This rule lists precisely which UI type uses which DB framework type. Instead of fixing matches one by one, first imagine how DB framework accesses could be encapsulated into a dedicated layer.
UI layer shouldn't use directly DAL layer - Architecture
This rule first defines the UI layer and the DAL layer. Second it checks if any UI layer type is using directly any DAL layer type.
• The DB layer (the DAL, Data Access Layer) is defined as the set of types of the application that use ADO.NET, EntityFramework, NHibernate types. It is easy to append and suppress any DB framework.
• The UI layer (User Interface Layer) is defined as the set of types that use WPF, Windows Form, ASP.NET.
UI using directly DAL is generally considered as poor design because DAL accesses should be a concept hidden to UI, encapsulated into an intermediary domain logic.
Notice that per defaut this rule estimates a technical debt proportional to the coupling between the UI with the DAL layer.
How to Fix:
This rule lists precisely which UI type uses which DAL type.
More about this particular design topic here: http://www.kenneth-truyers.net/2013/05/12/the-n-layer-myth-and-basic-dependency-injection/
Assemblies with poor cohesion (RelationalCohesion) - Architecture
The Relational Cohesion for an assembly, is the total number of relationship between types of the assemblies, divided by the number of types. In other words it is the average number of types in the assembly used by a type in the assembly.
As classes inside an assembly should be strongly related, the cohesion should be high.
Notice that assemblies with less than 20 types are ignored.
How to Fix:
Matches of this present rule might reveal either assemblies with specific coding constraints (like code generated that have particular structure) either issues in design.
In the second case, large refactoring can be planned not to respect this rule in particular, but to increase the overall design and code maintainability.
The severity of issues of this rule is Low because the code metric Relational Cohesion is an information about the code structure state but is not actionable, it doesn't tell precisely what to do obtain a better score.
Fixing actionable issues of others Architecture and Code Smells default rules will necessarily increase the Relational Cohesion scores.
Namespaces with poor cohesion (RelationalCohesion) - Architecture
The Relational Cohesion for a namespace, is the total number of relationship between types of the namespaces, divided by the number of types. In other words it is the average number of types in the namespace used by a type in the namespace.
As classes inside an assembly should be strongly related, the cohesion should be high.
Notice that namespaces with less than 20 types are ignored.
How to Fix:
Matches of this present rule might reveal either namespaces with specific coding constraints (like code generated that have particular structure) either issues in design.
In the second case, refactoring sessions can be planned to increase the overall design and code maintainability.
You can get an overview of class coupling for a matched namespace by exporting the ChildTypes to the graph. (Right click the ChildTypes cells)
The severity of issues of this rule is Low because the code metric Relational Cohesion is an information about the code structure state but is not actionable, it doesn't tell precisely what to do obtain a better score.
Fixing actionable issues of others Architecture and Code Smells default rules will necessarily increase the Relational Cohesion scores.
Assemblies that don't satisfy the Abstractness/Instability principle - Architecture
• Abstractness: If an assembly contains many abstract types (i.e interfaces and abstract classes) and few concrete types, it is considered as abstract.
• Stability: An assembly is considered stable if its types are used by a lot of types from other assemblies. In this context stable means painful to modify.
From these metrics, we define the perpendicular normalized distance of an assembly from the idealized line A + I = 1 (called main sequence). This metric is an indicator of the assembly's balance between abstractness and stability. We precise that the word normalized means that the range of values is [0.0 … 1.0].
This rule warns about assemblies with a normalized distance greater than than 0.7.
This rules use the default code metric on assembly Normalized Distance from the Main Sequence explained here: https://www.ndepend.com/docs/code-metrics#DitFromMainSeq
These concepts have been originally introduced by Robert C. Martin in 1994 in this paper: http://www.objectmentor.com/resources/articles/oodmetrc.pdf
How to Fix:
Violations of this rule indicate assemblies with an improper abstractness / stability balance.
• Either the assembly is potentially painful to maintain (i.e is massively used and contains mostly concrete types). This can be fixed by creating abstractions to avoid too high coupling with concrete implementations.
• Either the assembly is potentially useless (i.e contains mostly abstractions and is not used enough). In such situation, the design must be reviewed to see if it can be enhanced.
The severity of issues of this rule is Low because the Abstractness/Instability principle is an information about the code structure state but is not actionable, it doesn't tell precisely what to do obtain a better score.
Fixing actionable issues of others Architecture and Code Smells default rules will necessarily push the Abstractness/Instability principle scores in the right direction.
Avoid excessive class coupling - Architecture
High class coupling suggests that the type or the method may be handling too many responsibilities and thus, violates The Single Responsibility Principle explained here:
https://blog.ndepend.com/solid-design-the-single-responsibility-principle-srp/
How to Fix:
To address this issue, refactor the type or method by breaking it into smaller, more focused components that each follow a single responsibility.
Higher cohesion - lower coupling - Architecture
Typically, the more concrete namespaces rely on abstract namespaces only, the more Decoupled is the architecture, and the more Cohesive are classes inside concrete namespaces.
The present code query defines sets of abstract and concrete namespaces and show for each concrete namespaces, which concrete and abstract namespaces are used.
How to Fix:
This query can be transformed into a code rule, depending if you wish to constraint your code structure coupling / cohesion ratio.
Avoid mutually-dependent types - Architecture
In this situation both types are not isolated: each type cannot be reviewed, refactored or tested without the other one.
This rule is disabled by default because there are some common situations, like when implementing recursive data structures, complex serialization or using the visitor pattern, where having mutually dependent types is legitimate. Just enable this rule if you wish to fix most of its issues.
How to Fix:
Fixing mutually-dependent types means identifying the unwanted dependency (t1 using t2, or t2 using t1) and then removing this dependency.
Often you'll have to use the dependency inversion principle by creating one or several interfaces dedicated to abstract one implementation from the other one: https://blog.ndepend.com/solid-design-the-dependency-inversion-principle-dip
Example of custom rule to check for dependency - Architecture
Such rule can be generated:
• by right clicking the cell in the Dependency Matrix with B in row and A in column,
• or by right-clicking the concerned arrow in the Dependency Graph from A to B,
and in both cases, click the menu Generate a code rule that warns if this dependency exists
The generated rule will look like this one. It is now up to you to adapt this rule to check exactly your needs.
How to Fix:
This is a sample rule there is nothing to fix as is.
API Breaking Changes: Types - API Breaking Changes
This rule warns if a type publicly visible in the baseline, is not publicly visible anymore or if it has been removed. Clients code using such type will be broken.
How to Fix:
Make sure that public types that used to be presented to clients, still remain public now, and in the future.
If a public type must really be removed, you can tag it with System.ObsoleteAttribute with a workaround message during a few public releases, until it gets removed definitely. Notice that this rule doesn't match types removed that were tagged as obsolete.
Issues of this rule have a severity equal to High because an API Breaking change can provoque significant friction with consumers of the API.
API Breaking Changes: Methods - API Breaking Changes
This rule warns if a method publicly visible in the baseline, is not publicly visible anymore or if it has been removed. Clients code using such method will be broken.
How to Fix:
Make sure that public methods that used to be presented to clients, still remain public now, and in the future.
If a public method must really be removed, you can tag it with System.ObsoleteAttribute with a workaround message during a few public releases, until it gets removed definitely. Notice that this rule doesn't match methods removed that were tagged as obsolete.
Issues of this rule have a severity equal to High because an API Breaking change can provoque significant friction with consumers of the API.
API Breaking Changes: Fields - API Breaking Changes
This rule warns if a field publicly visible in the baseline, is not publicly visible anymore or if it has been removed. Clients code using such field will be broken.
How to Fix:
Make sure that public fields that used to be presented to clients, still remain public now, and in the future.
If a public field must really be removed, you can tag it with System.ObsoleteAttribute with a workaround message during a few public releases, until it gets removed definitely. Notice that this rule doesn't match fields removed that were tagged as obsolete.
Issues of this rule have a severity equal to High because an API Breaking change can provoque significant friction with consumers of the API.
API Breaking Changes: Interfaces and Abstract Classes - API Breaking Changes
This rule warns if a publicly visible interface or abstract class has been changed and contains new abstract methods or if some abstract methods have been removed.
Clients code that implement such interface or derive from such abstract class will be broken.
How to Fix:
Make sure that the public contracts of interfaces and abstract classes that used to be presented to clients, remain stable now, and in the future.
If a public contract must really be changed, you can tag abstract methods that will be removed with System.ObsoleteAttribute with a workaround message during a few public releases, until it gets removed definitely.
Issues of this rule have a severity equal to High because an API Breaking change can provoque significant friction with consummers of the API. The severity is not set to Critical because an interface is not necessarily meant to be implemented by the consummer of the API.
Broken serializable types - API Breaking Changes
This rule warns about breaking changes in types tagged with SerializableAttribute.
To do so, this rule searches for serializable type with serializable instance fields added or removed. Notice that it doesn't take account of fields tagged with NonSerializedAttribute.
From http://msdn.microsoft.com/library/system.serializableattribute.aspx : "All the public and private fields in a type that are marked by the SerializableAttribute are serialized by default, unless the type implements the ISerializable interface to override the serialization process. The default serialization process excludes fields that are marked with the NonSerializedAttribute attribute."
How to Fix:
Make sure that the serialization process of serializable types remains stable now, and in the future.
Else you'll have to deal with Version Tolerant Serialization that is explained here: https://msdn.microsoft.com/en-us/library/ms229752(v=vs.110).aspx
Issues of this rule have a severity equal to High because an API Breaking change can provoque significant friction with consummers of the API.
Avoid changing enumerations Flags status - API Breaking Changes
This rule matches enumeration types that used to be tagged with FlagsAttribute in the baseline, and not anymore. It also matches the opposite, enumeration types that are now tagged with FlagsAttribute, and were not tagged in the baseline.
Being tagged with FlagsAttribute is a strong property for an enumeration. Not so much in terms of behavior (only the enum.ToString() method behavior changes when an enumeration is tagged with FlagsAttribute) but in terms of meaning: is the enumeration a range of values or a range of flags?
As a consequence, changing the FlagsAttributes status of an enumeration can have significant impact for its clients.
How to Fix:
Make sure the FlagsAttribute status of each enumeration remains stable now, and in the future.
API: New publicly visible types - API Breaking Changes
This code query lists types that are new in the public surface of the analyzed assemblies.
API: New publicly visible methods - API Breaking Changes
This code query lists methods that are new in the public surface of the analyzed assemblies.
API: New publicly visible fields - API Breaking Changes
This code query lists fields that are new in the public surface of the analyzed assemblies.
Code should be tested - Code Coverage
For each match, the rules estimates the technical debt, i.e the effort to write unit and integration tests for the method. The estimation is based on the effort to develop the code element multiplied by factors in the range ]0,1.3] based on
• the method code size and complexity
• the actual percentage coverage
• the abstractness of types used, because relying on classes instead of interfaces makes the code more difficult to test
• the method visibility because testing private or protected methods is more difficult than testing public and internal ones
• the fields used by the method, because is is more complicated to write tests for methods that read mutable static fields whose changing state is shared across tests executions.
• whether the method is considered JustMyCode or not because NotMyCode is often generated easier to get tested since tests can be generated as well.
This rule is necessarily a large source of technical debt, since the code left untested is by definition part of the technical debt.
This rule also estimates the annual interest, i.e the annual cost to let the code uncovered, based on the effort to develop the code element, multiplied by factors based on usage of the code element.
When methods are aggregated within their parent type, the estimated debt and annual interest is aggregated as well.
How to Fix:
Write unit tests to test and cover the methods and their parent types matched by this rule.
New Types and Methods should be tested - Code Coverage
This rule is executed only if some code coverage data is imported from some code coverage files.
It is important to write code mostly covered by tests to achieve maintainable and non-error-prone code.
In real-world, many code bases are poorly covered by tests. However it is not practicable to stop the development for months to refactor and write tests to achieve high code coverage ratio.
Hence it is recommended that each time a method (or a type) gets added, the developer takes the time to write associated unit-tests to cover it.
Doing so will help to increase significantly the maintainability of the code base. You'll notice that quickly, refactoring will also be driven by testability, and as a consequence, the overall code structure and design will increase as well.
Issues of this rule have a High severity because they reflect an actual trend to not care about writing tests on refactored code.
How to Fix:
Write unit-tests to cover the code of most methods and types added since the baseline.
Methods refactored should be tested - Code Coverage
This rule is executed only if some code coverage data is imported from some code coverage files.
It is important to write code mostly covered by tests to achieve maintainable and non-error-prone code.
In real-world, many code bases are poorly covered by tests. However it is not practicable to stop the development for months to refactor and write tests to achieve high code coverage ratio.
Hence it is recommended that each time a method (or a type) gets refactored, the developer takes the time to write associated unit-tests to cover it.
Doing so will help to increase significantly the maintainability of the code base. You'll notice that quickly, refactoring will also be driven by testability, and as a consequence, the overall code structure and design will increase as well.
Issues of this rule have a High severity because they reflect an actual trend to not care about writing tests on refactored code.
How to Fix:
Write unit-tests to cover the code of most methods and classes refactored.
Assemblies and Namespaces should be tested - Code Coverage
If an assembly is matched its children namespaces are not matched.
This rule goal is not to collide with the Code should be tested rule that lists uncovered code for each method and infer the effort to write unit tests (the Debt) and the annual cost to let the code untested (the Annual Interest).
This rule goal is to inform of large code elements left untested. As a consequence the Debt per issue is only 4 minutes and the severity of the issues is Low.
How to Fix:
Write unit and integration tests to cover, even partially, code elements matched by this rule.
Then use issues of the rules Code should be tested, New Types and Methods should be tested and Methods refactored should be tested to write more tests where it matters most, and eventually refactor some code to make it more testable.
Types almost 100% tested should be 100% tested - Code Coverage
Often covering the few percents of remaining uncovered code of a class, requires as much work as covering the first 90%. For this reason, often teams estimate that 90% coverage is enough. However untestable code usually means poorly written code which usually leads to error prone code. So it might be worth refactoring and making sure to cover the few uncovered lines of code because most tricky bugs might come from this small portion of hard-to-test code.
Not all classes should be 100% covered by tests (like UI code can be hard to test) but you should make sure that most of the logic of your application is defined in some easy-to-test classes, 100% covered by tests.
Issues of this rule have a High severity because as explained, such situation is bug-prone.
How to Fix:
Write more unit-tests dedicated to cover code not covered yet. If you find some hard-to-test code, it is certainly a sign that this code is not well designed and hence, needs refactoring.
Namespaces almost 100% tested should be 100% tested - Code Coverage
Often covering the few percents of remaining uncovered code of one or several classes in a namespace requires as much work as covering the first 90%. For this reason, often teams estimate that 90% coverage is enough. However untestable code usually means poorly written code which usually leads to error prone code. So it might be worth refactoring and making sure to cover the few uncovered lines of code because most tricky bugs might come from this small portion of hard-to-test code.
Not all classes should be 100% covered by tests (like UI code can be hard to test) but you should make sure that most of the logic of your application is defined in some easy-to-test classes, 100% covered by tests.
Issues of this rule have a High severity because as explained, such situation is bug-prone.
How to Fix:
Write more unit-tests dedicated to cover code not covered yet in the namespace. If you find some hard-to-test code, it is certainly a sign that this code is not well designed and hence, needs refactoring.
Types that used to be 100% covered by tests should still be 100% covered - Code Coverage
This rule is executed only if some code coverage data is imported from some code coverage files.
Often covering 10% of remaining uncovered code of a class, requires as much work as covering the first 90%. For this reason, typically teams estimate that 90% coverage is enough. However untestable code usually means poorly written code which usually leads to error prone code. So it might be worth refactoring and making sure to cover the 10% remaining code because most tricky bugs might come from this small portion of hard-to-test code.
Not all classes should be 100% covered by tests (like UI code can be hard to test) but you should make sure that most of the logic of your application is defined in some easy-to-test classes, 100% covered by tests.
In this context, this rule warns when a type fully covered by tests is now only partially covered.
Issues of this rule have a High severity because often, a type that used to be 100% and is not covered anymore is a bug-prone situation that should be carefully handled.
How to Fix:
Write more unit-tests dedicated to cover code not covered anymore. If you find some hard-to-test code, it is certainly a sign that this code is not well designed and hence, needs refactoring.
You'll find code impossible to cover by unit-tests, like calls to MessageBox.Show(). An infrastructure must be defined to be able to mock such code at test-time.
Types tagged with FullCoveredAttribute should be 100% covered - Code Coverage
This rule is executed only if some code coverage data is imported from some code coverage files.
By using a FullCoveredAttribute, you can express in source code the intention that a class is 100% covered by tests, and should remain 100% covered in the future. If you don't want to link NDepend.API.dll, you can use your own attribute and adapt the source code of this rule.
Benefits of using a FullCoveredAttribute are twofold: Not only the intention is expressed in source code, but it is also continuously checked by the present rule.
Often covering 10% of remaining uncovered code of a class, requires as much work as covering the first 90%. For this reason, often teams estimate that 90% coverage is enough. However untestable code usually means poorly written code which usually means error prone code. So it might be worth refactoring and making sure to cover the 10% remaining code because most tricky bugs might come from this small portion of hard-to-test code.
Not all classes should be 100% covered by tests (like UI code can be hard to test) but you should make sure that most of the logic of your application is defined in some easy-to-test classes, 100% covered by tests.
Issues of this rule have a High severity because often, a type that used to be 100% and is not covered anymore is a bug-prone situation that should be carefully handled.
How to Fix:
Write more unit-tests dedicated to cover code of matched classes not covered yet. If you find some hard-to-test code, it is certainly a sign that this code is not well designed and hence, needs refactoring.
Types 100% covered should be tagged with FullCoveredAttribute - Code Coverage
By using an attribute class named FullCoveredAttribute, you can express in source code the intention that a class is 100% covered by tests, and should remain 100% covered in the future.
Benefits of using a FullCoveredAttribute are twofold: Not only the intention is expressed in source code, but it is also continuously checked by the rule Types tagged with FullCoveredAttribute should be 100% covered.
Issues of this rule have an Low severity because they don't reflect a problem, but provide an advice for potential improvement.
How to Fix:
Just tag types 100% covered by tests with the FullCoveredAttribute class that can be found in NDepend.API.dll, or by an attribute of yours with this name defined in any namespace in your own code.
Methods should have a low C.R.A.P score - Code Coverage
So far this rule is disabled because other code coverage rules assess properly code coverage issues.
Change Risk Analyzer and Predictor (i.e. CRAP) is a code metric that helps in pinpointing overly both complex and untested code. Is has been first defined here: http://www.artima.com/weblogs/viewpost.jsp?thread=215899
The Formula is: CRAP(m) = CC(m)^2 * (1 – cov(m)/100)^3 + CC(m)
• where CC(m) is the cyclomatic complexity of the method m
• and cov(m) is the percentage coverage by tests of the method m
Matched methods cumulates two highly error prone code smells:
• A complex method, difficult to develop and maintain.
• Non 100% covered code, difficult to refactor without introducing any regression bug.
The higher the CRAP score, the more painful to maintain and error prone is the method.
An arbitrary threshold of 30 is fixed for this code rule as suggested by inventors.
Notice that no amount of testing will keep methods with a Cyclomatic Complexity higher than 30, out of CRAP territory.
Notice that this rule doesn't match too short method with less than 10 lines of code.
How to Fix:
In such situation, it is recommended to both refactor the complex method logic into several smaller and less complex methods (that might belong to some new types especially created), and also write unit-tests to full cover the refactored logic.
You'll find code impossible to cover by unit-tests, like calls to MessageBox.Show(). An infrastructure must be defined to be able to mock such code at test-time.
Complex Methods should be 100% tested - Code Coverage
See the maintainability index definition here: https://www.ndepend.com/docs/code-metrics#MaintainabilityIndex
How to Fix:
1. Simplify the code by breaking down large or complex methods into smaller, focused units.
2. Improve readability with clear naming, consistent formatting, and reduced nesting.
3. Increase test coverage by writing unit tests that validate both common and edge cases.
4. Ensure all refactored code is fully covered by tests before merging.
Test Methods - Code Coverage
• The coverage ratio,
• And the amount of logic results asserted: This includes both assertions in test code, and assertions in code covered by tests, like Code Contract assertions and Debug.Assert(…) assertions.
But if you wish to enforce the quality of test code, you'll need to consider test assemblies in your list of application assemblies analyzed by NDepend.
In such situation, this code query lists tests methods and you can reuse this code in custom rules.
Methods directly called by test Methods - Code Coverage
We advise to not include test assemblies in code analyzed by NDepend. We estimate that it is acceptable and practical to lower the quality gate of test code, because the important measures for tests are:
• The coverage ratio,
• And the amount of logic results asserted: This includes both assertions in test code, and assertions in code covered by tests, like Code Contract assertions and Debug.Assert(…) assertions.
But if you wish to run this code query, you'll need to consider test assemblies in your list of application assemblies analyzed by NDepend.
Methods directly and indirectly called by test Methods - Code Coverage
Overrides of virtual and abstract methods, called through polymorphism, are not listed. Methods solely invoked through a delegate are not listed. Methods solely invoked through reflection are not listed.
We advise to not include test assemblies in code analyzed by NDepend. We estimate that it is acceptable and practical to lower the quality gate of test code, because the important measures for tests are:
• The coverage ratio,
• And the amount of logic results asserted: This includes both assertions in test code, and assertions in code covered by tests, like Code Contract assertions and Debug.Assert(…) assertions.
But if you wish to run this code query, you'll need to consider test assemblies in your list of application assemblies analyzed by NDepend.
Potentially Dead Types - Dead Code
This rule lists not only types not used anywhere in code, but also types used only by types not used anywhere in code. This is why this rule comes with a column TypesusingMe and this is why there is a code metric named depth:
• A depth value of 0 means the type is not used.
• A depth value of 1 means the type is used only by types not used.
• etc…
By reading the source code of this rule, you'll see that by default, public types are not matched, because such type might not be used by the analyzed code, but still be used by client code, not analyzed by NDepend. This default behavior can be easily changed.
Note that this rule doesn't match Entity Framework ModelSnapshot classes that are used ony by the EF infrastructure.
How to Fix:
Static analysis cannot provide an exact list of dead types, because there are several ways to use a type dynamically (like through reflection).
For each type matched by this query, first investigate if the type is used somehow (like through reflection). If the type is really never used, it is important to remove it to avoid maintaining useless code. If you estimate the code of the type might be used in the future, at least comment it, and provide an explanatory comment about the future intentions.
If a type is used somehow, but still is matched by this rule, you can tag it with the attribute IsNotDeadCodeAttribute found in NDepend.API.dll to avoid matching the type again. You can also provide your own attribute for this need, but then you'll need to adapt this code rule.
Issues of this rule have a Debt equal to 15 minutes because it only takes a short while to investigate if a type can be safely discarded. The Annual Interest of issues of this rule, the annual cost to not fix such issue, is proportional to the type #lines of code, because the bigger the type is, the more it slows down maintenance.
Potentially Dead Methods - Dead Code
This rule lists not only methods not called anywhere in code, but also methods called only by methods not called anywhere in code. This is why this rule comes with a column MethodsCallingMe and this is why there is a code metric named depth:
• A depth value of 0 means the method is not called.
• A depth value of 1 means the method is called only by methods not called.
• etc…
By reading the source code of this rule, you'll see that by default, public methods are not matched, because such method might not be called by the analyzed code, but still be called by client code, not analyzed by NDepend. This default behavior can be easily changed.
How to Fix:
Static analysis cannot provide an exact list of dead methods, because there are several ways to invoke a method dynamically (like through reflection).
For each method matched by this query, first investigate if the method is invoked somehow (like through reflection). If the method is really never invoked, it is important to remove it to avoid maintaining useless code. If you estimate the code of the method might be used in the future, at least comment it, and provide an explanatory comment about the future intentions.
If a method is invoked somehow, but still is matched by this rule, you can tag it with the attribute IsNotDeadCodeAttribute found in NDepend.API.dll to avoid matching the method again. You can also provide your own attribute for this need, but then you'll need to adapt this code rule.
Issues of this rule have a Debt equal to 10 minutes because it only takes a short while to investigate if a method can be safely discarded. On top of these 10 minutes, the depth of usage of such method adds up 3 minutes per unity because dead method only called by dead code takes a bit more time to be investigated.
The Annual Interest of issues of this rule, the annual cost to not fix such issue, is proportional to the type #lines of code, because the bigger the method is, the more it slows down maintenance.
Potentially Dead Fields - Dead Code
By reading the source code of this rule, you'll see that by default, public fields are not matched, because such field might not be used by the analyzed code, but still be used by client code, not analyzed by NDepend. This default behavior can be easily changed. Some others default rules in the Visibility group, warn about public fields.
More restrictions are applied by this rule because of some by-design limitations. NDepend mostly analyzes compiled IL code, and the information that an enumeration value or a literal constant (which are fields) is used is lost in IL code. Hence by default this rule won't match such field.
How to Fix:
Static analysis cannot provide an exact list of dead fields, because there are several ways to assign or read a field dynamically (like through reflection).
For each field matched by this query, first investigate if the field is used somehow (like through reflection). If the field is really never used, it is important to remove it to avoid maintaining a useless code element.
If a field is used somehow, but still is matched by this rule, you can tag it with the attribute IsNotDeadCodeAttribute found in NDepend.API.dll to avoid matching the field again. You can also provide your own attribute for this need, but then you'll need to adapt this code rule.
Issues of this rule have a Debt equal to 10 minutes because it only takes a short while to investigate if a method can be safely discarded. The Annual Interest of issues of this rule, the annual cost to not fix such issue, is set by default to 8 minutes per unused field matched.
Wrong usage of IsNotDeadCodeAttribute - Dead Code
This attribute is used in the dead code rules, Potentially dead Types, Potentially dead Methods and Potentially dead Fields. If you don't want to link NDepend.API.dll, you can use your own IsNotDeadCodeAttribute and adapt the source code of this rule, and the source code of the dead code rules.
In this context, this code rule matches code elements (types, methods, fields) that are tagged with this attribute, but still used directly somewhere in the code.
How to Fix:
Just remove IsNotDeadCodeAttribute tagging of types, methods and fields matched by this rule because this tag is not useful anymore.
Software Composition Analysis (SCA) - Security
An issue is raised for each NuGet package consumed that is associated with at least one security advisory. The issue is reported on the first type (alphabetically) that uses a third-party assembly from the affected NuGet package.
How to Fix:
Update the affected NuGet package to a version that is at or above the patched version recommended in the advisory. The patched version resolves all matching security advisories known for the package. The patched version is not always the latest available version. For example, if an issue exists in version 4.0.2, it might be resolved in version 4.1.0, even though the highest available version could be 7.0.8.
Transitive Software Composition Analysis (SCA) - Security
An issue is raised for each package that is associated with at least one security advisory. An issue is reported on the first application type (alphabetically) that uses a third-party assembly that uses the affected package.
Unlike the rule Software Composition Analysis (SCA) that matches security advisories on Packages used the application, the present rule focuses on Packages used by the Packages used by the application, hence the qualifier transitive.
How to Fix:
Update the package that contains DirectAsm to a version that doesn't use a package that has known security advisories.
Don't use CoSetProxyBlanket and CoInitializeSecurity - Security
How to Fix:
Don't call CoSetProxyBlanket() or CoInitializeSecurity() from managed code.
Instead write an unmanaged "shim" in C++ that will call one or both methods before loading the CLR within the process.
More information about writing such unmanaged "shim" can be found in this StackOverflow answer: https://stackoverflow.com/a/48545055/27194
Don't use System.Random for security purposes - Security
Using predictable random values in a security critical context can lead to vulnerabilities.
How to Fix:
If the matched method is meant to be executed in a security critical context use System.Security.Cryptography.RandomNumberGenerator or System.Security.Cryptography.RNGCryptoServiceProvider instead. These random implementations are slower to execute but the random numbers generated cannot be predicted.
Find more on using RNGCryptoServiceProvider to generate random values here: https://stackoverflow.com/questions/32932679/using-rngcryptoserviceprovider-to-generate-random-string
Otherwise you can use the faster System.Random implementation and suppress corresponding issues.
More information about the weakness of System.Random implementation can be found here: https://stackoverflow.com/a/6842191/27194
Don't use DES/3DES weak cipher algorithms - Security
How to Fix:
Use the AES (Advanced Encryption Standard) algorithms instead through the implementation: System.Security.Cryptography.AesCryptoServiceProvider.
You can still suppress issues of this rule when using DES/3DES algorithms for compatibility reasons with legacy applications and data.
Don't disable certificate validation - Security
Doing so is often used to disable certificate validation to connect easily to a host that is not signed by a root certificate authority. https://en.wikipedia.org/wiki/Root_certificate
This might create a vulnerability to man-in-the-middle attacks since the client will trust any certificate. https://en.wikipedia.org/wiki/Man-in-the-middle_attack
How to Fix:
Don't rely on a weak custom certificate validation.
If a legitimate custom certificate validation procedure must be subscribed, you can chose to suppress related issue(s).
Review publicly visible event handlers - Security
An event handler is any method with the standard signature (Object,EventArgs). An event handler can be registered to any event matching this standard signature.
As a consequence, such event handler can be subscribed by malicious code to an event to provoke execution of the security critical action on event firing.
Even if such event handler does a security check, it can be executed from a chain of trusted callers on the call stack, and cannot detect about malicious registration.
How to Fix:
Change matched event handlers to make them non-public. Preferably don't run a security critical action from an event handler.
If after a careful check no security critical action is involved from a matched event-handler, you can suppress the issue.
Pointers should not be publicly visible - Security
This rule detects fields with type System.IntPtr or System.UIntPtr that are public or protected.
Pointers are used to access unmanaged memory from managed code. Exposing a pointer publicly makes it easy for malicious code to read and write unmanaged data used by the application.
The situation is even worse if the field is not read-only since malicious code can change it and force the application to rely on arbitrary data.
How to Fix:
Pointers should have the visibility - private or internal.
The estimated Debt, which means the effort to fix such issue, is 15 minutes and 10 additional minutes per method using the field outside its assembly.
The estimated Severity of such issue is Medium, and High if the field is non read-only.
Seal methods that satisfy non-public interfaces - Security
The interface not being public indicates a process that should remain private.
Hence this situation represents a security vulnerability because it is now possible to create a malicious class, that derives from the parent class and that overrides the method behavior. This malicious behavior will be then invoked by private implementation.
How to Fix:
You can:
- seal the parent class,
- or change the accessibility of the parent class to non-public,
- or implement the method without using the virtual modifier,
- or change the accessibility of the method to non-public.
If after a careful check such situation doesn't represent a security threat, you can suppress the issue.
Review commands vulnerable to SQL injection - Security
This situation is prone to SQL Injection https://en.wikipedia.org/wiki/SQL_injection since malicious SQL code might be injected in string parameters values.
However there might be false positives. So review carefully matched methods and use suppress issues when needed.
To limit the false positives, this rule also checks whether command parameters are accessed from any sub method call. This is a solid indication of non-vulnerability.
How to Fix:
If after a careful check it appears that the method is indeed using some strings to inject parameters values in the SQL query string, command.Parameters.Add(...) must be used instead.
You can get more information on adding parameters explicitly here: https://stackoverflow.com/questions/4892166/how-does-sqlparameter-prevent-sql-injection
Review data adapters vulnerable to SQL injection - Security
This situation is prone to SQL Injection https://en.wikipedia.org/wiki/SQL_injection since malicious SQL code might be injected in string parameters values.
However there might be false positives. So review carefully matched methods and use suppress issues when needed.
To limit the false positives, this rule also checks whether command parameters are accessed from any sub method call. This is a solid indication of non-vulnerability.
How to Fix:
If after a careful check it appears that the method is indeed using some strings to inject parameters values in the SQL query string, adapter.SelectCommand.Parameters.Add(...) must be used instead (or adapter.UpdateCommand or adapter.InsertCommand, depending on the context).
You can get more information on adding parameters explicitly here: https://stackoverflow.com/questions/4892166/how-does-sqlparameter-prevent-sql-injection
Methods that could have a lower visibility - Visibility
Narrowing visibility is a good practice because doing so effectively promotes encapsulation. This limits the scope from which methods can be accessed to a minimum.
By default, this rule doesn't match publicly visible methods that could have a lower visibility because it cannot know if the developer left the method public intentionally or not. Public methods matched are declared in non-public types.
By default this rule doesn't match methods with the visibility public that could be internal, declared in a type that is not public (internal, or nested private for example) because this situation is caught by the rule Avoid public methods not publicly visible.
Notice that methods tagged with one of the attribute NDepend.Attributes.CannotDecreaseVisibilityAttribute or NDepend.Attributes.IsNotDeadCodeAttribute, found in NDepend.API.dll are not matched. If you don't want to link NDepend.API.dll but still wish to rely on this facility, you can declare these attributes in your code.
How to Fix:
Declare each matched method with the specified optimal visibility in the CouldBeDeclared rule result column.
By default, this rule matches public methods. If you are publishing an API many public methods matched should remain public. In such situation, you can opt for the coarse solution to this problem by adding in the rule source code && !m.IsPubliclyVisible or you can prefer the finer solution by tagging each concerned method with CannotDecreaseVisibilityAttribute.
Types that could have a lower visibility - Visibility
Narrowing visibility is a good practice because doing so promotes encapsulation. The scope from which types can be consumed is then reduced to a minimum.
By default, this rule doesn't match publicly visible types that could have a lower visibility because it cannot know if the developer left the type public intentionally or not. Public types matched are nested in non-public types.
Notice that types tagged with one of the attribute NDepend.Attributes.CannotDecreaseVisibilityAttribute or NDepend.Attributes.IsNotDeadCodeAttribute, found in NDepend.API.dll are not matched. If you don't want to link NDepend.API.dll but still wish to rely on this facility, you can declare these attributes in your code.
How to Fix:
Declare each matched type with the specified optimal visibility in the CouldBeDeclared rule result column.
By default, this rule matches public types. If you are publishing an API many public types matched should remain public. In such situation, you can opt for the coarse solution to this problem by adding in the rule source code && !m.IsPubliclyVisible or you can prefer the finer solution by tagging each concerned type with CannotDecreaseVisibilityAttribute.
Fields that could have a lower visibility - Visibility
Narrowing visibility is a good practice because doing so promotes encapsulation. The scope from which fields can be consumed is then reduced to a minimum.
By default, this rule doesn't match publicly visible fields that could have a lower visibility because it cannot know if the developer left the field public intentionally or not. Public fields matched are declared in non-public types.
Notice that fields tagged with one of the attribute NDepend.Attributes.CannotDecreaseVisibilityAttribute or NDepend.Attributes.IsNotDeadCodeAttribute, found in NDepend.API.dll are not matched. If you don't want to link NDepend.API.dll but still wish to rely on this facility, you can declare these attributes in your code.
How to Fix:
Declare each matched field with the specified optimal visibility in the CouldBeDeclared rule result column.
By default, this rule matches public fields. If you are publishing an API some public fields matched should remain public. In such situation, you can opt for the coarse solution to this problem by adding in the rule source code && !m.IsPubliclyVisible or you can prefer the finer solution by tagging eah concerned field with CannotDecreaseVisibilityAttribute.
Types that could be declared as private, nested in a parent type - Visibility
The conditions for a type to be potentially nested into a parent type are:
• the parent type is the only type consuming it,
• the type and the parent type are declared in the same namespace.
Declaring a type as private into a parent type improves encapsulation. The scope from which the type can be consumed is then reduced to a minimum.
This rule doesn't match classes with extension methods because such class cannot be nested in another type.
How to Fix:
Nest each matched type into the specified parent type and declare it as private.
However nested private types are hardly testable. Hence this rule might not be applied to types consumed directly by tests.
Avoid publicly visible constant fields - Visibility
Notice that enumeration value fields suffer from the same potential pitfall. But enumeration values cannot be declared as static readonly hence the rule comes with the condition && !f.IsEnumValue to avoid matching these. Unless you decide to banish public enumerations, just let the rule as is.
How to Fix:
Declare matched fields as static readonly instead of constant. This way, the field value is safely changeable without the need to recompile client assemblies.
Fields should be declared as private or protected - Visibility
Fields should be considered as implementation details and as a consequence they should be declared as private, or protected if it makes sense for derived classes to use it.
If something goes wrong with a non-private field, the culprit can be anywhere, and so in order to track down the bug, you may have to look at quite a lot of code.
A private field, by contrast, can only be assigned from inside the same class, so if something goes wrong with that, there is usually only one source file to look at.
Issues of this rule are fast to get fixed, and they have a debt proportional to the number of methods assigning the field.
How to Fix:
Consider declaring a matched mutable field as private or marking it as readonly. If possible, refactor the code outside its parent type to eliminate its usage.
Alternatively, if external code requires access to the field, consider encapsulating the field accesses within a property. Using a property allows you to set debug breakpoints on the accessors, simplifying the tracking of read-write accesses in case of issues.
Constructors of abstract classes should be declared as protected or private - Visibility
Because a public constructor is creating instances of its class, and because it is forbidden to create instances of an abstract class, an abstract class with a public constructor is wrong design.
Notice that when the constructor of an abstract class is private, it means that derived classes must be nested in the abstract class.
How to Fix:
To fix a violation of this rule, either declare the constructor as protected, or do not declare the type as abstract.
Avoid public methods not publicly visible - Visibility
In such situation public means, can be accessed from anywhere my parent type is visible. Some developers think this is an elegant language construct, some others find it misleading.
This rule can be deactivated if you don't agree with it. Read the whole debate here: http://ericlippert.com/2014/09/15/internal-or-public/
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
How to Fix:
Declare the method as internal if it is used outside of its type, else declare it as private.
Event handler methods should be declared as private or protected - Visibility
Such method can also be declared as protected because some designers such as the ASP.NET designer, generates such method as protected to let a chance to sub-classes to call it.
How to Fix:
If you have the need that event handler method should be called from another class, then find a code structure that more closely matches the concept of what you're trying to do. Certainly you don't want the other class to click a button; you want the other class to do something that clicking a button also do.
Wrong usage of CannotDecreaseVisibilityAttribute - Visibility
Usage of this attribute means that a code element visibility is not optimal (it can be lowered like for example from public to internal) but shouldn’t be modified anyway. Typical reasons to do so include:
• Public code elements consumed through reflection, through a mocking framework, through XML or binary serialization, through designer, COM interfaces…
• Non-private code element invoked by test code, that would be difficult to reach from test if it was declared as private.
In such situation CannotDecreaseVisibilityAttribute is used to avoid that default rules about not-optimal visibility warn. Using this attribute can be seen as an extra burden, but it can also be seen as an opportunity to express in code: Don't change the visibility else something will be broken
In this context, this code rule matches code elements (types, methods, fields) that are tagged with this attribute, but still already have an optimal visibility.
How to Fix:
Just remove CannotDecreaseVisibilityAttribute tagging of types, methods and fields matched by this rule because this tag is not useful anymore.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Exception classes should be declared as public - Visibility
How to Fix:
Declare your custom exception classes as public to make them catchable in every context.
Methods that should be declared as 'public' in C#, 'Public' in VB.NET - Visibility
This query relies on the property NDepend.CodeModel.IMember.ShouldBePublic https://www.ndepend.com/api/webframe.html#NDepend.API~NDepend.CodeModel.IMember~ShouldBePublic.html
This is just a code query, it is not intended to advise you to declare the method as public, but to inform you that the code actually relies on the peculiar behavior of the attribute InternalsVisibleToAttribute.
Fields should be marked as ReadOnly when possible - Immutability
This source code of this rule is based on the conditon IField.IsImmutable. https://www.ndepend.com/api/webframe.html#NDepend.API~NDepend.CodeModel.IField~IsImmutable.html
A field that matches the condition IsImmutable is a field that is assigned only by constructors of its class.
For an instance field, this means its value will remain constant through the lifetime of the object.
For a static field, this means its value will remain constant through the lifetime of the program.
Using readonly is advantageous for enhancing code robustness and readability. Its true value becomes evident when collaborating with a team or performing maintenance. Declaring a field as readonly defines a contract for that field's usage in the code. It explicitly conveys that the field should not be altered after initialization and enforces this constraint.
How to Fix:
Declare the field with the C# readonly keyword (ReadOnly in VB.NET).
Avoid non-readonly static fields - Immutability
In Object-Oriented-Programming the natural artifact to hold states that can be modified is instance fields. Such mutable static fields create confusion about the expected state at runtime and impairs the code testability since the same mutable state is re-used for each test.
More discussion on the topic can be found here: https://blog.ndepend.com/the-proper-usages-of-the-keyword-static-in-c/
How to Fix:
If the static field is just assigned once in the program lifetime, make sure to declare it as readonly and assign it inline, or from the static constructor.
Else if methods other than the static constructor need to assign the state hold by the static field, refactoring must occur to ensure that this state is hold through an instance field.
Avoid static fields with a mutable field type - Immutability
In Object-Oriented-Programming the natural artifact to hold states that can be modified is instance fields. Hence such static fields create confusion about the expected state at runtime.
More discussion on the topic can be found here: https://blog.ndepend.com/the-proper-usages-of-the-keyword-static-in-c/
How to Fix:
To fix violations of this rule, make sure to hold mutable states through objects that are passed explicitly everywhere they need to be consumed, in opposition to mutable object hold by a static field that makes it modifiable from a bit everywhere in the program.
Structures should be immutable - Immutability
Structures are value types, which means that when you pass them as method arguments or assign them to new variables, you're working with copies of the original. This behavior is different from classes, where you work with references to the same object. Modifying copies of structures can lead to confusion and errors because developers are not accustomed to this behavior.
For more information, refer to this documentation: https://blog.ndepend.com/class-vs-struct-in-c-making-informed-choices/
How to Fix:
Make sure matched structures are immutable. This way, all automatic copies of an original instance, resulting from being passed by value will hold the same values and there will be no surprises.
Note that since C#7.2 you can prefix a structure declaration with the keyword readonly to enforce that it is an immutable structure.
If your structure is immutable then if you want to change a value, you have to consciously do it by creating a new instance of the structure with the modified data.
Immutable struct should be declared as readonly - Immutability
More can be read on the readonly struct topic in this documentation: https://learn.microsoft.com/en-us/dotnet/csharp/write-safe-efficient-code#declare-immutable-structs-as-readonly
How to Fix:
Just declare matched structures as readonly struct.
Property Getters should be pure - Immutability
This rule doesn't match property getters that assign a field not assigned by any other methods than the getter itself and the corresponding property setter. Hence this rule avoids matching lazy initialization at first access of a state. In such situation the getter assigns a field at first access and from the client point of view, lazy initialization is an invisible implementation detail.
A field assigned by a property with a name similar to the property name are not count either, also to avoid matching lazy initialization at first access situations.
How to Fix:
Make sure that matched property getters don't assign any field.
The estimated Debt, which means the effort to fix such issue, is equal to 2 minutes plus 5 minutes per field assigned and 5 minutes per other method assigning such field.
A field must not be assigned from outside its parent hierarchy types - Immutability
Fields should be considered as implementation details and as a consequence they should be declared as private.
If something goes wrong with a non-private field, the culprit can be anywhere, and so in order to track down the bug, you may have to look at quite a lot of code.
A private field, by contrast, can only be assigned from inside the same class, so if something goes wrong with that, there is usually only one source file to look at.
How to Fix:
Matched fields must be declared as protected and even better as private.
However, if the field exclusively references immutable states, it can remain accessible from the outside but must be declared as readonly.
The estimated Debt, which means the effort to fix such issue, is equal to 5 minutes per method outside the parent hierarchy that assigns the matched field.
Don't assign a field from many methods - Immutability
• For an instance field, constructor(s) of its class that assign the field are not counted.
• For a static field, the class constructor that assigns the field is not counted.
The default threshold for instance fields is equal to 4 or more than 4 methods assigning the instance field. Such situation makes harder to anticipate the field state at runtime. The code is then complicated to read, hard to debug and hard to maintain. Hard-to-solve bugs due to corrupted state are often the consequence of fields anarchically assigned.
The situation is even more complicated if the field is static. Indeed, such situation potentially involves global random accesses from various parts of the application. This is why this rule provides a lower threshold equals to 3 or more than 3 methods assigning the static field.
If the object containing such field is meant to be used from multiple threads, there are alarming chances that the code is unmaintainable and bugged. When multiple threads are involved, the rule of thumb is to use immutable objects.
If the field type is a reference type (interfaces, classes, strings, delegates) corrupted state might result in a NullReferenceException. If the field type is a value type (number, boolean, structure) corrupted state might result in wrong result not even signaled by an exception thrown.
How to Fix:
There is no straight advice to refactor the number of methods responsible for assigning a field. Sometime the situation is simple enough, like when a field that hold an indentation state is assigned by many writer methods. Such situation only requires to define two methods IndentPlus()/IndentMinus() that assign the field, called from all writers methods.
Sometime the solution involves rethinking and then rewriting a complex algorithm. Such field can sometime become just a variable accessed locally by a method or a closure. Sometime, just rethinking the life-time and the role of the parent object allows the field to become immutable (i.e assigned only by the constructor).
The estimated Debt, which means the effort to fix such issue, is equal to 4 minutes plus 5 minutes per method assigning the instance field or 10 minutes per method assigning the static field.
Do not declare read only fields with mutable reference types - Immutability
This situation can be misleading: the keyword readonly mistakenly suggests that the object remains constant, while in fact, the field reference remains fixed but the referenced object's state can still change.
How to Fix:
To fix a violation of this rule, replace the field type with an immutable type, or declare the field as private.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Public read only array fields can be modified - Immutability
This situation represents a security vulnerability. Because the field is read-only it cannot be changed to refer to a different array. However, the elements of the array that are stored in a read-only field can be changed. Code that makes decisions or performs operations that are based on the elements of a read-only array that can be publicly accessed might contain an exploitable security vulnerability.
How to Fix:
To fix the security vulnerability that is identified by this rule do not rely on the contents of a read-only array that can be publicly accessed. It is strongly recommended that you use one of the following procedures:
• Replace the array with a strongly typed collection that cannot be changed. See for example: System.Collections.Generic.IReadOnlyList<T> ; System.Collections.Generic.IReadOnlyCollection<T> ; System.Collections.ReadOnlyCollectionBase
• Or replace the public field with a method that returns a clone of a private array. Because your code does not rely on the clone, there is no danger if the elements are modified.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Types tagged with ImmutableAttribute must be immutable - Immutability
An attribute NDepend.Attributes.ImmutableAttribute can be used to express in code that a type is immutable. In such situation, the present code rule checks continuously that the type remains immutable whatever the modification done.
This rule warns when a type that is tagged with ImmutableAttribute is actually not immutable anymore.
Notice that ImmutableAttribute is defined in NDepend.API.dll and if you don't want to link this assembly, you can create your own ImmutableAttribute and adapt the rule.
How to Fix:
First understand which modification broke the type immutability. The list of culpritFields provided in this rule result can help. Then try to refactor the type to bring it back to immutability.
The estimated Debt, which means the effort to fix such issue, is equal to 5 minutes plus 10 minutes per culprit field.
Types immutable should be tagged with ImmutableAttribute - Immutability
This code query lists immutable type that are not tagged with an attribute named NDepend.Attributes.ImmutableAttribute. You can define such attribute in your code base. By using an ImmutableAttribute, you can express in source code the intention that a class is immutable, and should remain immutable in the future. Benefits of using an ImmutableAttribute are twofold:
• Not only the intention is expressed in source code,
• but it is also continuously checked by the rule Types tagged with ImmutableAttribute must be immutable.
How to Fix:
Just tag types matched by this code query with ImmutableAttribute that can be found in NDepend.API.dll, or by an attribute of yours defined in your own code (in which case this code query must be adapted).
Methods tagged with PureAttribute must be pure - Immutability
An attribute PureAttribute can be used to express in code that a method is pure. In such situation, the present code rule checks continuously that the method remains pure whatever the modification done.
This rule warns when a method that is tagged with PureAttribute is actually not pure anymore.
Notice that NDepend.Attributes.PureAttribute is defined in NDepend.API.dll and if you don't want to link this assembly, you can also use System.Diagnostics.Contracts.PureAttribute or create your own PureAttribute and adapt the rule.
Notice that System.Diagnostics.Contracts.PureAttribute is taken account by the compiler only when the VS project has Microsoft Code Contract enabled.
How to Fix:
First understand which modification broke the method purity. Then refactor the method to bring it back to purity.
Pure methods should be tagged with PureAttribute - Immutability
This code query lists pure methods that are not tagged with a PureAttribute. By using such attribute, you can express in source code the intention that a method is pure, and should remain pure in the future. Benefits of using a PureAttribute are twofold:
• Not only the intention is expressed in source code,
• but it is also continuously checked by the rule Methods tagged with PureAttribute must be pure.
This code query is not by default defined as a code rule because certainly many of the methods of the code base are matched. Hence fixing all matches and then maintaining the rule unviolated might require a lot of work. This may counter-balance such rule benefits.
How to Fix:
Just tag methods matched by this code query with NDepend.Attributes.PureAttribute that can be found in NDepend.API.dll, or with System.Diagnostics.Contracts.PureAttribute, or with an attribute of yours defined in your own code (in which case this code query must be adapted).
Notice that System.Diagnostics.Contracts.PureAttribute is taken account by the compiler only when the VS project has Microsoft Code Contract enabled.
Record should be immutable - Immutability
However it is still possible to create a mutable state in a record with a property setter that is not declared as init.
It is recommended to refrain from including mutable states in a record as it disrupts the value-based semantics. For example changing the state of a record object used as a key in a hash table can corrupt the hash table integrity.
Also changing the state of a record object can lead to unexpected value-based equality results. In both cases such code-smell ends up provoking bugs that are difficult to spot and difficult to fix.
How to Fix:
To fix an issue of this rule you must make sure that the matched record becomes immutable. To do so mutable property setters (culpritSetters in the result) of the setter must be transformed in property initializers with the init C# keyword. Callers of the mutable property setters (methodsCallingCulpritSetters in the result) must be also refactored to avoid changing the record states.
The estimated Debt, which means the effort to fix such issue, is equal to 8 minutes plus 3 minutes per mutable property setter and per method calling such mutable property setter.
Instance fields naming convention - Naming Conventions
• Instance field name starting with a lower-case letter
• Instance field name starting with "_" followed with a lower-case letter
• Instance field name starting with "m_" followed with an upper-case letter
The rule can be easily adapted to your own company naming convention.
In terms of behavior, a static field is something completely different than an instance field, so it is interesting to differentiate them at a glance through a naming convetion.
This is why it is advised to use a specific naming convention for instance field like name that starts with m_.
Related discussion: https://blog.ndepend.com/on-hungarian-notation-for-fields-in-csharp/
How to Fix:
Once the rule has been adapted to your own naming convention make sure to name all matched instance fields adequately.
Static fields naming convention - Naming Conventions
• Static field name starting with an upper-case letter
• Static field name starting with "_" followed with an upper-case letter
• Static field name starting with "s_" followed with an upper-case letter
The rule can be easily adapted to your own company naming convention.
In terms of behavior, a static field is something completely different than an instance field, so it is interesting to differentiate them at a glance through a naming convetion.
This is why it is advised to use a specific naming convention for static field like name that starts with s_.
Related discussion: https://blog.ndepend.com/on-hungarian-notation-for-fields-in-csharp/
How to Fix:
Once the rule has been adapted to your own naming convention make sure to name all matched static fields adequately.
Interface name should begin with a 'I' - Naming Conventions
Typically COM interfaces names don't follow this rule. Hence this code rule doesn't take care of interfaces tagged with ComVisibleAttribute.
How to Fix:
Make sure that matched interfaces names are prefixed with an upper I.
Abstract base class should be suffixed with 'Base' - Naming Conventions
Notice that this rule doesn't match abstract classes that are in a middle of a hierarchy chain. In other words, only base classes that derive directly from System.Object are matched.
How to Fix:
Suffix the names of matched base classes with Base.
Exception class name should be suffixed with 'Exception' - Naming Conventions
For exception base classes, the suffix ExceptionBase is also accepted.
How to Fix:
Suffix the names of matched exception classes with Exception.
Attribute class name should be suffixed with 'Attribute' - Naming Conventions
How to Fix:
Suffix the names of matched attribute classes with Attribute.
Types name should begin with an Upper character - Naming Conventions
Pascal Casing Style : The first letter in the identifier and the first letter of each subsequent concatenated word are capitalized. For example: BackColor
How to Fix:
Pascal Case the names of matched types.
Methods name should begin with an Upper character - Naming Conventions
Pascal Casing Style : The first letter in the identifier and the first letter of each subsequent concatenated word are capitalized. For example: ComputeSize
How to Fix:
Pascal Case the names of matched methods.
Do not name enum values 'Reserved' - Naming Conventions
Instead of using a reserved member, add a new member to the enumeration in the future version.
In most cases, the addition of the new member is not a breaking change, as long as the addition does not cause the values of the original members to change.
How to Fix:
To fix a violation of this rule, remove or rename the member.
Avoid types with name too long - Naming Conventions
This rule matches types with names with more than 40 characters.
How to Fix:
To fix a violation of this rule, rename the type with a shortest name or eventually split the type in several more fine-grained types.
Avoid methods with name too long - Naming Conventions
This rule matches methods with names with more than 40 characters.
However it is considered as a good practice to name unit tests in such a way with a very expressive name, hence this rule doens't match methods tagged with FactAttribute, TestAttribute and TestCaseAttribute.
How to Fix:
To fix a violation of this rule, rename the method with a shortest name that equally conveys the behavior of the method. Or eventually split the method into several smaller methods.
Avoid fields with name too long - Naming Conventions
This rule matches fields with names with more than 40 characters.
How to Fix:
To fix a violation of this rule, rename the field with a shortest name that equally conveys the same information.
Avoid having different types with same name - Naming Conventions
Such practice leads confusion and also naming collision in source files that use different types with same name.
How to Fix:
To fix a violation of this rule, rename concerned types.
Avoid prefixing type name with parent namespace name - Naming Conventions
For example a type named "RuntimeEnvironment" declared in a namespace named "Foo.Runtime" should be named "Environment".
Such situation results in redundant naming without any improvement in readability.
How to Fix:
To fix a violation of this rule, remove the prefix from the type name.
Avoid naming types and namespaces with the same identifier - Naming Conventions
For example when a type is named Environment and a namespace is named Foo.Environment.
Such situation provokes tedious compiler resolution collision, and makes the code less readable because concepts are not concisely identified.
How to Fix:
To fix a violation of this rule, renamed the concerned type or namespace.
Don't call your method Dispose - Naming Conventions
This rule warns when a method is named Dispose(), but the parent type doesn't implement System.IDisposable.
How to Fix:
To fix a violation of this rule, you can either have the parent type implement System.IDisposable, or rename the Dispose() method using a different identifier, such as Close() Terminate() Finish() Quit() Exit() Unlock() ShutDown()…
Methods prefixed with 'Try' should return a boolean - Naming Conventions
Such method usually returns a result through an out parameter. For example: System.Int32.TryParse(int,out string):bool
How to Fix:
To fix a violation of this rule, Rename the method, or transform it into an operation that can fail.
Properties and fields that represent a collection of items should be named Items. - Naming Conventions
Depending on the domain of your application, a proper identifier could be NewDirectories, Words, Values, UpdatedDates.
Also this rule doesn't warn when any word in the identifier ends with an s. This way identifiers like TasksToRun, KeysDisabled, VersionsSupported, ChildrenFilesPath, DatedValuesDescending, ApplicationNodesChanged or ListOfElementsInResult are valid and won't be seen as violations.
Moreover this rule won't warn for a field or property with an identifier that contain the word Empty. This is a common pattern to define an immutable and empty collection instance shared.
Before inspecting properties and fields, this rule gathers application and third-party collection types that might be returned by a property or a field. To do so this rule searches types that implement IEnumerable<T> except:
- Non generic types: Often a non generic type is not seen as a collection. For example System.String implements IEnumerable<char>, but a string is rarely named as a collection of characters. In others words, we have much more strings in our program named like FirstName than named like EndingCharacters.
- Dictionaries types: A dictionary is more than a collection of pairs, it is a mapping from one domain to another. A common practice is to suffix the name of a dictionary with Map Table or Dictionary, although often dictionaries names satify this rule with names like GuidsToPersons or PersonsByNames.
How to Fix:
Just rename the fields and properties accordingly, by making plural the word in the identifier that describes best the items in the collection.
For example:
- ListOfDir can be renamed Directories.
- Children can be renamed ChildrenItems
- QueueForCache can be renamed QueueOfItemsForCache
DDD ubiquitous language check - Naming Conventions
This rule is disabled per default because its source code needs to be customized to work, both with the core domain namespace name (that contains classes and types to be checked), and with the list of domain language terms.
If a term needs to be used both with singular and plural forms, both forms need to be mentioned, like Seat and Seats for example. Notice that this default rule is related with the other default rule Properties and fields that represent a collection of items should be named Items defined in the Naming Convention group.
This rule implementation relies on the NDepend API ExtensionMethodsString.GetWords(this string identifier) extension method that extracts terms from classes, methods and fields identifiers in a smart way.
How to Fix:
For each violation, this rule provides the list of words not in vocabulary.
To fix a violation of this rule, either rename the concerned code element or update the domain language terms list defined in this rule source code, with the missing term(s).
Avoid fields with same name in class hierarchy - Naming Conventions
The C# and VB.NET compilers allow this situation even if the base class field is visible to derived classes with a visibility different than private.
However this situation is certainly a sign of an erroneous attempt to redefine a field in a derived class.
How to Fix:
Check if the field in the derived class is indeed a redefinition of the base class field. Check also that both fields types corresponds. If fields are static, double check that only a single instance of the referenced object is needed. If all checks are positive delete the derived class field and make sure that the base class field is visible to derived classes with the protected visibility.
If no, rename the field in the derived class and be very careful in renaming all usages of this field, they might be related with the base class field.
Avoid various capitalizations for method name - Naming Conventions
With this rule you'll discover various names like ProcessOrderId and ProcessOrderID. It is important to choose a single capitalization used accross the whole application to improve overall readability, maintainability, team collaboration and consistency.
Matched methods are not necessarily declared in the same type. However if various capitalizations of a method name are found within the same type, the issue severity goes from Medium to Critical. Indeed, this situation is not just a matter of convention, it is error-prone. It forces type's clients to investigate which version of the method to call.
How to Fix:
Choose a single capitalization for the method name used accross the whole application.
Or alternatively make the distinction clear by having different method names that don't only differ by capitalization.
The technical-debt for each issue, the estimated cost to fix an issue, is proportional to the number of capitalizations found (2 minimum).
Controller class name should be suffixed with 'Controller' - Naming Conventions
For Controller base classes, the suffix ControllerBase is also accepted.
How to Fix:
Suffix the names of matched Controller classes with Controller.
Nested class members should not mask outer class' static members - Naming Conventions
How to Fix:
To avoid such naming collision, members of the inner class should be assigned unique and descriptive names.
Avoid referencing source file out of the project directory - Source Files Organization
Doing so can be used to share types definitions across several assemblies. This provokes type duplication at binary level. Hence maintainability is degraded and subtle versioning bug can appear.
This rule matches types whose source files are not declared under the directory that contains the related Visual Studio project file, or under any sub-directory of this directory.
This practice can be tolerated for certain types shared across executable assemblies. Such type can be responsible for startup related concerns, such as registering custom assembly resolving handlers or checking the .NET Framework version before loading any custom library.
How to Fix:
To fix a violation of this rule, prefer referencing from a VS project only source files defined in sub-directories of the VS project file location.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Avoid duplicating a type definition across assemblies - Source Files Organization
This rule warns about using this feature to share code across several assemblies. This provokes type duplication at binary level. Hence maintainability is degraded and subtle versioning bug can appear.
Each match represents a type duplicated. Unfolding the types in the column typesDefs will show the multiple definitions across multiple assemblies.
This practice can be tolerated for certain types shared across executable assemblies. Such type can be responsible for startup related concerns, such as registering custom assembly resolving handlers or checking the .NET Framework version before loading any custom library.
How to Fix:
To fix a violation of this rule, prefer sharing types through DLLs or if the types with same full name are different, rename them.
Avoid defining multiple types in a source file - Source Files Organization
Each match of this rule is a source file that contains several types definitions, indexed by one of those types, preferably the one with the same name than the source file name without file extension, if any.
Notice that types nested in a parent type, enumerations and types with file visibility are exempt from counting. This is because it is considered acceptable to declare these types within the same source file as their principal user type.
How to Fix:
To fix a violation of this rule, create a source file for each type.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Namespace name should correspond to file location - Source Files Organization
Following this practice is a widely accepted convention, and failing to adhere to it can result in source code that is less maintainable and harder to navigate.
This rule applies to all namespaces declared in source files where the file location does not align with the namespace name.
Please note that comparisons between namespaces and directory names are case-sensitive. Additionally, there is a boolean flag, justACaseSensitiveIssue, which indicates whether this misalignment is solely due to a case sensitivity problem. In such cases, the technical debt associated with this issue is a bit lower.
How to Fix:
To fix a violation of this rule, make sure that the namespace and the directory sub-paths that contains the source filed, are aligned.
Types with source files stored in the same directory, should be declared in the same namespace - Source Files Organization
Following this practice is a widely accepted convention, and failing to adhere to it can result in source code that is less maintainable and harder to navigate.
Respecting this convention means that types with source files stored in the same directory, should be declared in the same namespace.
For each directory that contains several source files, where most types are declared in a namespace (what we call the main namespace) and a few types are declared out of the main namespace, this code rule matches:
• The main namespace
• typesOutOfMainNamespace: Types declared in source files in the main namespace's directory but that are not in the main namespace.
• typesInMainNamespace: And for informational purposes, types declared in source files in the main namespace's directory, and that are in the main namespace.
How to Fix:
Violations of this rule are types in the typesOutOfMainNamespace column. Typically such type …
• … is contained in the wrong namespace but its source file is stored in the right directory. In such situation the type should be contained in main namespace.
• … is contained in the right namespace but its source file is stored in the wrong directory In such situation the source file of the type must be moved to the proper parent namespace directory.
• … is declared in multiple source files, stored in different directories. In such situation it is preferable that all source files are stored in a single directory.
The estimated Debt, which means the effort to fix such issue, is equal to 2 minutes plus 5 minutes per type in typesOutOfMainNamespace.
Types declared in the same namespace, should have their source files stored in the same directory - Source Files Organization
Following this practice is a widely accepted convention, and failing to adhere to it can result in source code that is less maintainable and harder to navigate.
Respecting this convention means that types declared in the same namespace, should have their source files stored in the same directory.
For each namespace that contains types whose source files are declared in several directories, infer the main directory, the directory that naturally hosts source files of types, preferably the directory whose name corresponds with the namespace name. In this context, this code rule matches:
• The namespace
• typesDeclaredOutOfMainDir: types in the namespace whose source files are stored out of the main directory.
• The main directory
• typesDeclaredInMainDir: for informational purposes, types declared in the namespace, whose source files are stored in the main directory.
How to Fix:
Violations of this rule are types in the typesDeclaredOutOfMainDir column. Typically such type…
• … is contained in the wrong namespace but its source file is stored in the right directory. In such situation the type should be contained in the namespace corresponding to the parent directory.
• … is contained in the right namespace but its source file is stored in the wrong directory. In such situation the source file of the type must be moved to the main directory.
• … is declared in multiple source files, stored in different directories. In such situation it is preferable that all source files are stored in a single directory.
The estimated Debt, which means the effort to fix such issue, is equal to 2 minutes plus 5 minutes per type in typesDeclaredOutOfMainDir.
Mark ISerializable types with SerializableAttribute - System
This rule matches types that implement ISerializable and that are not tagged with SerializableAttribute.
How to Fix:
To fix a violation of this rule, tag the matched type with SerializableAttribute .
Mark assemblies with CLSCompliant (deprecated) - System
The Common Language Specification (CLS) defines naming restrictions, data types, and rules to which assemblies must conform if they are to be used across programming languages. Good design dictates that all assemblies explicitly indicate CLS compliance with CLSCompliantAttribute. If the attribute is not present on an assembly, the assembly is not compliant.
Notice that it is possible for a CLS-compliant assembly to contain types or type members that are not compliant.
This rule matches assemblies that are not tagged with System.CLSCompliantAttribute.
How to Fix:
To fix a violation of this rule, tag the assembly with CLSCompliantAttribute.
Instead of marking the whole assembly as non-compliant, you should determine which type or type members are not compliant and mark these elements as such. If possible, you should provide a CLS-compliant alternative for non-compliant members so that the widest possible audience can access all the functionality of your assembly.
Mark assemblies with ComVisible (deprecated) - System
The ComVisibleAttribute attribute determines how COM clients access managed code. Good design dictates that assemblies explicitly indicate COM visibility. COM visibility can be set for a whole assembly and then overridden for individual types and type members. If the attribute is not present, the contents of the assembly are visible to COM clients.
This rule matches assemblies that are not tagged with System.Runtime.InteropServices.ComVisibleAttribute.
How to Fix:
To fix a violation of this rule, tag the assembly with ComVisibleAttribute.
If you do not want the assembly to be visible to COM clients, set the attribute value to false.
Mark attributes with AttributeUsageAttribute - System
The System.AttributeTargets enumeration defines the targets that you can specify for a custom attribute. If you omit AttributeUsageAttribute, your custom attribute will be valid for all targets, as defined by the All value of AttributeTargets enumeration.
This rule matches attribute classes that are not tagged with System.AttributeUsageAttribute.
Abstract attribute classes are not matched since AttributeUsageAttribute can be deferred to derived classes.
Attribute classes that have a base class tagged with AttributeUsageAttribute are not matched since in this case attribute usage is inherited.
How to Fix:
To fix a violation of this rule, specify targets for the attribute by using AttributeUsageAttribute with the proper AttributeTargets values.
Remove calls to GC.Collect() - System
More in information on this here: http://blogs.msdn.com/ricom/archive/2004/11/29/271829.aspx
This rule matches application methods that call an overload of the method GC.Collect().
How to Fix:
Remove matched calls to GC.Collect().
Don't call GC.Collect() without calling GC.WaitForPendingFinalizers() - System
But if you wish to call GC.Collect() anyway, you must do it this way:
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
To make sure that finalizer got executed, and object with finalizer got cleaned properly.
This rule matches application methods that call an overload of the method GC.Collect(), without calling GC.WaitForPendingFinalizers().
How to Fix:
To fix a violation of this rule, if you really need to call GC.Collect(), make sure to call GC.WaitForPendingFinalizers() properly.
Enum Storage should be Int32 - System
Even though you can change this underlying type, it is not necessary or recommended for most scenarios. Note that using a data type smaller than Int32 doesn't result in a significant performance improvement. If you cannot use the default data type, you should use one of the Common Language System (CLS)-compliant integral types, Byte, Int16, Int32, or Int64 to make sure that all values of the enumeration can be represented in CLS-compliant programming languages.
This rule matches enumerations whose underlying type used to store values is not System.Int32.
How to Fix:
To fix a violation of this rule, unless size or compatibility issues exist, use Int32. For situations where Int32 is not large enough to hold the values, use Int64. If backward compatibility requires a smaller data type, use Byte or Int16.
Do not raise too general exception types - System
• System.Exception
• System.ApplicationException
• System.SystemException
If you throw such a general exception type in a library or framework, it compels client code to catch all exceptions, including unknown exceptions that they do not know how to handle.
This rule matches methods that create an instance of such general exception class.
How to Fix:
To fix a violation of this rule, change the type of the thrown exception to either a more derived type that already exists in the framework, or create your own type that derives from System.Exception.
The estimated Debt, which means the effort to fix such issue, is equal to 15 minutes per method matched, plus 5 minutes per too general exception types instantiated by the method.
Do not raise reserved exception types - System
• System.ExecutionEngineException
• System.IndexOutOfRangeException
• System.OutOfMemoryException
• System.StackOverflowException
• System.InvalidProgramException
• System.AccessViolationException
• System.CannotUnloadAppDomainException
• System.BadImageFormatException
• System.DataMisalignedException
Do not throw an exception of such reserved type.
This rule matches methods that create an instance of such reserved exception class.
How to Fix:
To fix a violation of this rule, change the type of the thrown exception to a specific type that is not one of the reserved types.
Concerning the particular case of a method throwing System.NullReferenceException, often the fix will be either to throw instead System.ArgumentNullException, either to use a contract (through MS Code Contracts API or Debug.Assert()) to signify that a null reference at that point can only be the consequence of a bug.
More generally the idea of using a contract instead of throwing an exception in case of corrupted state / bug consequence detected is a powerful idea. It replaces a behavior (throwing exception) with a declarative assertion that basically means: at that point a bug somehow provoqued the detected corrupted state and continuing any processing from now is potentially harmful. The process should be shutdown and the circonstances of the failure should be reported as a bug to the product team.
Uri fields or properties should be of type System.Uri - System
This rule matches fields and properties with the name ending with 'Uri' or 'Url' that are not typed with System.Uri.
How to Fix:
Rename the field or property, or change the field or property type to System.Uri.
By default issues of this rule have a Low severity because they reflect more an advice than a problem.
Types should not derive from System.ApplicationException - System
The recommendation has changed and new exceptions should derive from System.Exception or one of its subclasses in the System namespace.
This rule matches application exception classes that derive from ApplicationException.
How to Fix:
Make sure that matched exception types, derive from System.Exception or one of its subclasses in the System namespace.
Don't Implement ICloneable - System
First, this interface existed even before .NET 2.0 that introduced generics. Hence this interface is not generic and the Clone() method returns an object reference that needs to be downcasted to be useful.
Second, this interface doesn't make explicit whether the cloning should be deep or shallow. The difference between the two behaviors is fundamental (explanation here https://stackoverflow.com/a/184745/27194). Not being able to make the intention explicit leads to confusion.
Third, classes that derive from a class that implements ICloneable must also implement the Clone() method, and it is easy to forget this constraint.
This rule doesn't warn for classes that derive from a class that implements ICloneable. In this case the issue must be fixed in the base class, or is maybe not fixable if the base class is declared in a third-party assembly.
How to Fix:
Don't implement anymore this interface.
You can rename the remaining Clone() methods to DeepClone() or ShallowClone() with a typed result.
Or you can propose two custom generic interfaces IDeepCloneable<T> with the single method DeepClone():T and IShallowCloneable<T> with the single method ShallowClone():T.
Finally you can write custom NDepend rules to make sure that all classes that derive from a class with a virtual clone method, override this method.
Collection properties should be read only - System.Collections
Both binary and XML serialization support read-only properties that are collections. The System.Xml.Serialization.XmlSerializer class has specific requirements for types that implement ICollection and System.Collections.IEnumerable in order to be serializable.
This rule matches property setter methods that assign a collection object.
How to Fix:
To fix a violation of this rule, make the property read-only and, if the design requires it, add methods to clear and re-populate the collection.
Don't use .NET 1.x HashTable and ArrayList - System.Collections
This rule warns about application methods that use a non-generic collection class, including ArrayList, HashTable, Queue, Stack or SortedList.
How to Fix:
List<T> should be preferred over ArrayList. It is generic hence you get strongly typed elements. Also, it is faster with T as a value types since it avoids boxing.
For the same reasons:
• Dictionary<K,V> should be prevered over HashTable.
• Queue<T> should be prevered over Queue.
• Stack<T> should be prevered over Stack.
• SortedDictionary<K,V> or SortedList<K,V> should be prevered over SortedList.
You can be forced to use non generic collections because you are using third party code that requires working with these classes or because you are coding with .NET 1.x, but nowadays this situation should question about using newer updates of .NET. .NET 1.x is an immature platform conpared to newer .NET updates.
Caution with List.Contains() - System.Collections
The cost of checking if a list contains an object is proportional to the size of the list. In other words it is a O(N) operation. For large lists and/or frequent calls to Contains(), prefer using the System.Collections.Generic.HashSet<T> class where calls to Contains() take a constant time (O(0) operation).
This code query is not a code rule, because more often than not, calling O(N) Contains() is not a mistake. This code query aims at pointing out this potential performance pitfall.
Prefer return collection abstraction instead of implementation - System.Collections
Most often than not, clients of a method don't need to know the exact implementation of the collection returned. It is preferable to return a collection interface such as IList<T>, ICollection<T>, IEnumerable<T> or IDictionary<TKey,TValue>.
Using the collection interface instead of the implementation shouldn't applies to all cases, hence this code query is not code rule.
P/Invokes should be static and not be publicly visible - System.Runtime.InteropServices
Such methods should not be exposed. By keeping these methods private or internal, you make sure that your library cannot be used to breach security by allowing callers access to unmanaged APIs that they could not call otherwise.
This rule matches methods tagged with DllImportAttribute attribute that are declared as public or declared as non-static.
How to Fix:
To fix a violation of this rule, change the access level of the method and/or declare it as static.
Move P/Invokes to NativeMethods class - System.Runtime.InteropServices
• NativeMethods - This class does not suppress stack walks for unmanaged code permission. (System.Security.SuppressUnmanagedCodeSecurityAttribute must not be applied to this class.) This class is for methods that can be used anywhere because a stack walk will be performed.
• SafeNativeMethods - This class suppresses stack walks for unmanaged code permission. (System.Security.SuppressUnmanagedCodeSecurityAttribute is applied to this class.) This class is for methods that are safe for anyone to call. Callers of these methods are not required to perform a full security review to make sure that the usage is secure because the methods are harmless for any caller.
• UnsafeNativeMethods - This class suppresses stack walks for unmanaged code permission. (System.Security.SuppressUnmanagedCodeSecurityAttribute is applied to this class.) This class is for methods that are potentially dangerous. Any caller of these methods must perform a full security review to make sure that the usage is secure because no stack walk will be performed.
These classes are declared as static internal. The methods in these classes are static and internal.
This rule matches P/Invoke methods not declared in such NativeMethods class.
How to Fix:
To fix a violation of this rule, move the method to the appropriate NativeMethods class. For most applications, moving P/Invokes to a new class that is named NativeMethods is enough.
NativeMethods class should be static and internal - System.Runtime.InteropServices
This code rule warns about NativeMethods classes that are not declared static and internal.
How to Fix:
Matched NativeMethods classes must be declared as static and internal.
Don't create threads explicitly - System.Threading
Prefer using the thread pool instead of creating manually your own threads. Threads are costly objects. They take approximately 200,000 cycles to create and about 100,000 cycles to destroy. By default they reserve 1 Mega Bytes of virtual memory for its stack and use 2,000-8,000 cycles for each context switch.
As a consequence, it is preferable to let the thread pool recycle threads.
How to Fix:
Instead of creating explicitly threads, use the Task Parallel Library (TPL) that relies on the CLR thread pool.
Introduction to TPL: https://msdn.microsoft.com/en-us/library/dd460717(v=vs.110).aspx
TPL and the CLR v4 thread pool: http://www.danielmoth.com/Blog/New-And-Improved-CLR-4-Thread-Pool-Engine.aspx
By default issues of this rule have a Critical severity because creating threads can have severe consequences.
Don't use dangerous threading methods - System.Threading
• Usage of Thread.Abort() is dangerous. More information on this here: http://www.interact-sw.co.uk/iangblog/2004/11/12/cancellation
• Usage of Thread.Sleep() is a sign of flawed design. More information on this here: http://msmvps.com/blogs/peterritchie/archive/2007/04/26/thread-sleep-is-a-sign-of-a-poorly-designed-program.aspx
• Suspend() and Resume() are dangerous threading methods, marked as obsolete. More information on workaround here: http://stackoverflow.com/questions/382173/what-are-alternative-ways-to-suspend-and-resume-a-thread
How to Fix:
Suppress calls to Thread methods exposed in the suppressCallsTo column in the rule result.
Use instead facilities offered by the Task Parallel Library (TPL) : https://msdn.microsoft.com/en-us/library/dd460717(v=vs.110).aspx
Monitor TryEnter/Exit must be both called within the same method - System.Threading
Doing so makes the code less readable, because it gets harder to locate when critical sections begin and end.
Also, you expose yourself to complex and error-prone scenarios.
How to Fix:
Refactor matched methods to make sure that Monitor critical sections begin and end within the same method. Basics scenarios can be handled through the C# lock keyword. Using explicitly the class Monitor should be left for advanced situations, that require calls to methods like Wait() and Pulse().
More information on using the Monitor class can be found here: http://www.codeproject.com/Articles/13453/Practical-NET-and-C-Chapter
ReaderWriterLock AcquireLock/ReleaseLock must be both called within the same method - System.Threading
Doing so makes the code less readable, because it gets harder to locate when critical sections begin and end.
Also, you expose yourself to complex and error-prone scenarios.
How to Fix:
Refactor matched methods to make sure that ReaderWriterLock read or write critical sections begin and end within the same method.
Don't tag instance fields with ThreadStaticAttribute - System.Threading
How to Fix:
Refactor the code to make sure that all fields tagged with ThreadStaticAttribute are static.
Method non-synchronized that read mutable states - System.Threading
Mutable type states are static fields that can be modified through the lifetime of the program.
This query lists methods that read mutable state without synchronizing access. In the case of multi-threaded program, doing so can lead to state corruption.
This code query is not a code rule because more often than not, a match of this query is not an issue.
Method should not return concrete XmlNode - System.Xml
XmlNode implements the interface System.Xml.Xpath.IXPathNavigable. In most situation, returning this interface instead of the concrete type is a better design choice that will abstract client code from implementation details.
How to Fix:
To fix a violation of this rule, change the concrete returned type to the suggested interface IXPathNavigable and refactor clients code if possible.
Types should not derive from System.Xml.XmlDocument - System.Xml
Do not create a subclass of XmlDocument if you want to create an XML view of an underlying object model or data source.
How to Fix:
Instead of subclassing XmlDocument, you can use the interface System.Xml.XPath.IXPathNavigable implemented by the class XmlDocument.
An alternative of using XmlDocument, is to use System.Xml.Linq.XDocument, aka LINQ2XML. More information on this can be found here: http://stackoverflow.com/questions/1542073/xdocument-or-xmldocument
Float and Date Parsing must be culture aware - System.Globalization
This rule warns about the usage of non-globalized overloads of the methods Parse(), TryParse() and ToString(), of the types DateTime, float, double and decimal. This is the symptom that your application is at least partially not globalized.
Non-globalized overloads of these methods are the overloads that don't take a parameter of type IFormatProvider.
How to Fix:
Globalize your applicaton and make sure to use the globalized overloads of these methods. In the column MethodsCallingMe of this rule result are listed the methods of your application that call the non-globalized overloads.
More information on Creating Globally Aware Applications here: https://msdn.microsoft.com/en-us/library/cc853414(VS.95).aspx
The estimated Debt, which means the effort to fix such issue, is equal to 5 minutes per application method calling at least one non-culture aware method called, plus 3 minutes per non-culture aware method called.
Mark assemblies with assembly version - System.Reflection
• Assembly name
• Version number
• Culture
• Public key (for strong-named assemblies).
The .NET Framework uses the version number to uniquely identify an assembly, and to bind to types in strong-named assemblies. The version number is used together with version and publisher policy. By default, applications run only with the assembly version with which they were built.
This rule matches assemblies that are not tagged with System.Reflection.AssemblyVersionAttribute.
How to Fix:
To fix a violation of this rule, add a version number to the assembly by using the System.Reflection.AssemblyVersionAttribute attribute.
Assemblies should have the same version - System.Reflection
Before fixing these issues, double check if there is a valid reason for dealing with more than one assembly version number. Typically this happens when the analyzed code base is made of assemblies that are not compiled, developed or deployed together.
How to Fix:
If all assemblies of your application should have the same version number, just use the attribute System.Reflection.AssemblyVersion in a source file shared by the assemblies.
Typically this source file is generated by a dedicated MSBuild task like this one http://www.msbuildextensionpack.com/help/4.0.5.0/html/d6c3b5e8-00d4-c826-1a73-3cfe637f3827.htm.
Here you can find interesting assemblies versioning advices. http://stackoverflow.com/a/3905443/27194
By default issues of this rule have a severity set to major since unproper assemblies versioning can lead to complicated deployment problem.
Assemblies Referenced in Multiple Versions - System.Reflection
Such situations may result in unexpected behavior and unexpected bugs.
The issue explanation provides a list of assemblies referencing different versions of the target assembly.
This list includes both application assemblies and third-party assemblies.
The assembly scan is transitive since references of third-party assemblies are considered.
How to Fix:
Make sure that all packages consummed by the application are referenced in a single version.
To do so rely on Transitive pinning in Central Package Management. Set the MSBuild property CentralPackageTransitivePinningEnabled to true in a Directory.Packages.props or Directory.Build.props import file. More on this here: https://blog.ndepend.com/understand-nuget-central-package-management-and-transitive-pinning-with-examples/
Public methods returning a reference needs a contract to ensure that a non-null reference is returned - Microsoft.Contracts
Contract.Ensure() is defined in the Microsoft Code Contracts for .NET library, and is typically used to write a code contract on returned reference: Contract.Ensures(Contract.Result<ReturnType>() != null, "returned reference is not null"); https://visualstudiogallery.msdn.microsoft.com/1ec7db13-3363-46c9-851f-1ce455f66970
How to Fix:
Use Microsoft Code Contracts for .NET on the public surface of your API, to remove most ambiguity presented to your client. Most of such ambiguities are about null or not null references.
Don't use null reference if you need to define a method that might not return a result. Use instead the TryXXX() pattern exposed for example in the System.Int32.TryParse() method.
The estimated Debt, which means the effort to fix such issue, is equal to 5 minutes per public application method that might return a null reference plus 3 minutes per method calling such method.
Classes tagged with InitializeOnLoad should have a static constructor - Unity
The static constructors of the class tagged with this attribute is responsible for the initialization.
How to Fix:
Create a static constructor for the matched classes.
Avoid using non-generic GetComponent - Unity
How to Fix:
Refactor GetComponent(typeof(MyType)) calls in GetComponent<MyType>().
Avoid empty Unity message - Unity
How to Fix:
Remove matched methods to avoid unnecessary processing.
Avoid using Time.fixedDeltaTime with Update - Unity
How to Fix:
Refactor calls to Time.fixedDeltaTime with Time.deltaTime within Update() and FixedUpdate() functions
Use CreateInstance to create a scriptable object - Unity
This is because the Unity egine needs to create the scriptable object itself to handle Unity message methods.
How to Fix:
Replace new Foo() expressions with ScriptableObject.CreateInstance<Foo>() expressions.
The SerializeField attribute is redundant on public fields - Unity
Declaring a field as public makes a field display in the Inspector and causes it to be saved, as well as letting the field be publicly accessed by other scripts.
Hence the SerializeField attribute is redundant for public fields.
How to Fix:
Remove the SerializeField attribute on matched public fields.
InitializeOnLoadMethod should tag only static and parameterless methods - Unity
The attribute RuntimeInitializeOnLoadMethodAttribute has same behavior except that the methods are invoked after the game has been loaded.
Both attributes can only tag static and parameterless methods.
How to Fix:
Make the matched methods static and parameterless.
Prefer using SetPixels32() over SetPixels() - Unity
The structure Color32 uses a byte value within the range [0,255] to represent each color component.
Hence Color32 consumes 4 times less memory and is much faster to work with.
How to Fix:
If 32bit-RGBA is compatible with your scenario, use SetPixels32() instead.
Don't use System.Reflection in performance critical messages - Unity
Don't use it in performance critical messages like Update, FixedUpdate, LateUpdate, or OnGUI.
How to Fix:
Don't use reflection in matched methods.
Discard generated Assemblies from JustMyCode - Defining JustMyCode
So far this query only matches application assemblies tagged with System.CodeDom.Compiler.GeneratedCodeAttribute, ASP.NET Core Razor assemblies suffixed with .Views.dll and assemblies with no C#, VB or F# code. Make sure to make this query richer to discard your generated assemblies from the NDepend rules results.
notmycode queries are executed before running others queries and rules. Also modifying a notmycode query provokes re-run of queries and rules that rely on the JustMyCode code base view.
Several notmycode queries can be written to match assemblies, in which case this results in cumulative effect.
Online documentation: https://www.ndepend.com/docs/cqlinq-syntax#NotMyCode
Discard generated Namespaces from JustMyCode - Defining JustMyCode
So far this query matches the My namespaces generated by the VB.NET compiler. This query also matches namespaces named mshtml or Microsoft.Office.* that are generated by tools.
notmycode queries are executed before running others queries and rules. Also modifying a notmycode query provokes re-run of queries and rules that rely on the JustMyCode code base view.
Several notmycode queries can be written to match namespaces, in which case this results in cumulative effect.
Online documentation: https://www.ndepend.com/docs/cqlinq-syntax#NotMyCode
Discard generated Types from JustMyCode - Defining JustMyCode
So far this query matches several well-identified generated types, like the ones tagged with System.CodeDom.Compiler.GeneratedCodeAttribute. Make sure to make this query richer to discard your generated types from the NDepend rules results.
notmycode queries are executed before running others queries and rules. Also modifying a notmycode query provokes re-run of queries and rules that rely on the JustMyCode code base view.
Several notmycode queries can be written to match types, in which case this results in cumulative effect.
Online documentation: https://www.ndepend.com/docs/cqlinq-syntax#NotMyCode
Discard generated and designer Methods from JustMyCode - Defining JustMyCode
So far this query matches several well-identified generated methods, like the ones tagged with System.CodeDom.Compiler.GeneratedCodeAttribute, or the ones declared in a source file suffixed with .designer.cs. Make sure to make this query richer to discard your generated methods from the NDepend rules results.
notmycode queries are executed before running others queries and rules. Also modifying a notmycode query provokes re-run of queries and rules that rely on the JustMyCode code base view.
Several notmycode queries can be written to match methods, in which case this results in cumulative effect.
Online documentation: https://www.ndepend.com/docs/cqlinq-syntax#NotMyCode
Discard generated Fields from JustMyCode - Defining JustMyCode
This query matches application fields tagged with System.CodeDom.Compiler.GeneratedCodeAttribute, and Windows Form, WPF and UWP fields generated by the designer. Make sure to make this query richer to discard your generated fields from the NDepend rules results.
notmycode queries are executed before running others queries and rules. Also modifying a notmycode query provokes re-run of queries and rules that rely on the JustMyCode code base view.
Several notmycode queries can be written to match fields, in which case this results in cumulative effect.
Online documentation: https://www.ndepend.com/docs/cqlinq-syntax#NotMyCode
JustMyCode code elements - Defining JustMyCode
This means concretely that the ICodeBaseView JustMyCode only shows these code elements. This code base view is used by many default code rule to avoid being warned on code elements that you don't consider as your code - typically the code elements generated by a tool.
These code elements are the ones that are not matched by any quere prefixed with notmycode.
NotMyCode code elements - Defining JustMyCode
This means concretely that the ICodeBaseView JustMyCode hide these code elements. This code base view is used by many default code rules to avoid being warned on code elements that you don't consider as your code - typically the code elements generated by a tool.
These code elements are the ones matched by queries prefixed with notmycode.
# New Issues since Baseline - Issues
# Issues Fixed since Baseline - Issues
# Issues Worsened since Baseline - Issues
Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
# Issues with severity Blocker - Issues
The severity of an issue is inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > Issue and Debt.
# Issues with severity Critical - Issues
The severity of an issue is inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > Issue and Debt.
# Issues with severity High - Issues
The severity of an issue is inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > issue and Debt.
# Issues with severity Medium - Issues
The severity of an issue is inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > issue and Debt.
# Issues with severity Low - Issues
Issues with a Low or Medium severity level represents small improvements, ways to make the code looks more elegant.
The Broken Window Theory https://en.wikipedia.org/wiki/Broken_windows_theory states that:
"Consider a building with a few broken windows. If the windows are not repaired, the tendency is for vandals to break a few more windows. Eventually, they may even break into the building, and if it's unoccupied, perhaps become squatters or light fires inside."
Issues with a Low or Medium severity level represents the broken windows of a code base. If they are not fixed, the tendency is for developers to not care for living in an elegant code, which will result in extra-maintenance-cost in the long term.
The severity of an issue is inferred from the issue annual interest and thresholds defined in the NDepend Project Properties > issue and Debt.
# Blocker/Critical/High Issues - Issues
An issue with the severity Blocker cannot move to production, it must be fixed.
An issue with a severity level Critical shouldn't move to production. It still can for business imperative needs purposes, but at worth it must be fixed during the next iterations.
An issue with a severity level High should be fixed quickly, but can wait until the next scheduled interval.
# Issues - Issues
# Suppressed Issues - Issues
# Rules - Rules
When no baseline is available, rules that rely on diff are not counted. If you observe that this count slightly decreases with no apparent reason, the reason is certainly that rules that rely on diff are not counted because the baseline is not defined.
# Rules Violated - Rules
When no baseline is available, rules that rely on diff are not counted. If you observe that this count slightly decreases with no apparent reason, the reason is certainly that rules that rely on diff are not counted because the baseline is not defined.
# Critical Rules Violated - Rules
The concept of critical rule is useful to pinpoint certain rules that should not be violated.
When no baseline is available, rules that rely on diff are not counted. If you observe that this count slightly decreases with no apparent reason, the reason is certainly that rules that rely on diff are not counted because the baseline is not defined.
# Quality Gates - Quality Gates
When no baseline is available, quality gates that rely on diff are not counted. If you observe that this count slightly decreases with no apparent reason, the reason is certainly that quality gates that rely on diff are not counted because the baseline is not defined.
# Quality Gates Warn - Quality Gates
When no baseline is available, quality gates that rely on diff are not counted. If you observe that this count slightly decreases with no apparent reason, the reason is certainly that quality gates that rely on diff are not counted because the baseline is not defined.
# Quality Gates Fail - Quality Gates
When no baseline is available, quality gates that rely on diff are not counted. If you observe that this count slightly decreases with no apparent reason, the reason is certainly that quality gates that rely on diff are not counted because the baseline is not defined.
Percentage Debt (Metric) - Debt
Infer a percentage from:
• the estimated total time to develop the code base
• and the the estimated total time to fix all issues (the Debt).
Estimated total time to develop the code base is inferred from # lines of code of the code base and from the Estimated number of man-day to develop 1000 logical lines of code setting found in NDepend Project Properties > Issue and Debt.
Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
Debt (Metric) - Debt
Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
New Debt since Baseline (Metric) - Debt
Debt added (or fixed if negative) since baseline.
Debt documentation: https://www.ndepend.com/docs/technical-debt#Debt
Annual Interest (Metric) - Debt
Annual Interest documentation: https://www.ndepend.com/docs/technical-debt#AnnualInterest
New Annual Interest since Baseline (Metric) - Debt
Annual Interest added (or fixed if negative) since baseline.
Annual Interest documentation: https://www.ndepend.com/docs/technical-debt#AnnualInterest
Breaking Point - Debt
The debt is the estimated cost-to-fix the issues.
The annual interest is the estimated cost-to-not-fix the issues, per year.
Hence the breaking point is the point in time from now, when not fixing the issues cost as much as fixing the issue.
Breaking Point documentation: https://www.ndepend.com/docs/technical-debt#BreakingPoint
Breaking Point of Blocker / Critical / High Issues - Debt
The debt is the estimated cost-to-fix the issues.
The annual interest is the estimated cost-to-not-fix the issues, per year.
Hence the breaking point is the point in time from now, when not fixing the issues cost as much as fixing the issue.
Breaking Point documentation: https://www.ndepend.com/docs/technical-debt#BreakingPoint
# Lines of Code - Code Size
# Lines of Code (JustMyCode) - Code Size
# Lines of Code (NotMyCode) - Code Size
# Lines of Code Added since the Baseline - Code Size
# Source Files - Code Size
If a value 0 is obtained, it means that at analysis time, assemblies PDB files were not available. https://www.ndepend.com/docs/ndepend-analysis-inputs-explanation
So far source files cannot be matched by a code query. However editing the query "Application Types" and then Group by source file declarations will list source files with types source declarations.
# Line Feed - Code Size
In other words this is the number of physical lines of code while the trend metric # Lines of Code counts the number of logical lines of code (see https://www.ndepend.com/docs/code-metrics#NbLinesOfCode).
# IL Instructions - Code Size
# IL Instructions (NotMyCode) - Code Size
# Lines of Comments - Code Size
So far commenting information is only extracted from C# source code and VB.NET support is planned.
Percentage of Comments - Code Size
So far commenting information is only extracted from C# source code and VB.NET support is planned.
# Assemblies - Code Size
# Namespaces - Code Size
# Types - Code Size
# Public Types - Code Size
# Classes - Code Size
# Abstract Classes - Code Size
# Interfaces - Code Size
# Structures - Code Size
# Methods - Code Size
# Abstract Methods - Code Size
# Concrete Methods - Code Size
# Fields - Code Size
Max # Lines of Code for Methods (JustMyCode) - Maximum and Average
Average # Lines of Code for Methods - Maximum and Average
Average # Lines of Code for Methods with at least 3 Lines of Code - Maximum and Average
Max # Lines of Code for Types (JustMyCode) - Maximum and Average
Average # Lines of Code for Types - Maximum and Average
Max Cyclomatic Complexity for Methods - Maximum and Average
Average Cyclomatic Complexity for Methods - Maximum and Average
Max IL Cyclomatic Complexity for Methods - Maximum and Average
Average IL Cyclomatic Complexity for Methods - Maximum and Average
Max IL Nesting Depth for Methods - Maximum and Average
Average IL Nesting Depth for Methods - Maximum and Average
Max # of Methods for Types - Maximum and Average
Average # Methods for Types - Maximum and Average
Max # of Methods for Interfaces - Maximum and Average
Average # Methods for Interfaces - Maximum and Average
Percentage Code Coverage - Coverage
# Lines of Code Covered - Coverage
# Lines of Code Not Covered - Coverage
# Lines of Code Uncoverable - Coverage
A method, type or assembly can be excluded from coverage either by using a .runsettings file, or by using an Uncoverable attribute.
A .runsettings file can be specified through: NDepend Project Properties > Analysis > Code Coverage > Settings > Exclusion Coverage File
Typically the attribute System.Diagnostics.CodeAnalysis.ExcludeFromCodeCoverageAttribute is used as the Uncoverable attribute.
An additional custom Uncoverable attribute can be defined in the: NDepend Project Properties > Analysis > Code Coverage > Settings > Un-Coverable attributes.
If coverage is imported from VS coverage technologies those attributes are also considered as Uncoverable attribute: System.Diagnostics.DebuggerNonUserCodeAttribute System.Diagnostics.DebuggerHiddenAttribute.
If coverage data imported at analysis time is not in-sync with the analyzed code base, this query will also list methods not defined in the coverage data imported.
# Lines of Code in Types 100% Covered - Coverage
Covering 90% of a class is not enough.
• It means that this 10% uncovered code is hard-to-test,
• which means that this code is not well-designed,
• which means that it is error-prone.
Better test error-prone code, isn't it?
# Lines of Code in Methods 100% Covered - Coverage
A line of code covered by tests is even more valuable if it is in a method 100% covered by test.
Max C.R.A.P Score - Coverage
The Formula is: CRAP(m) = CC(m)^2 * (1 – cov(m)/100)^3 + CC(m)
• where CC(m) is the cyclomatic complexity of the method m
• and cov(m) is the percentage coverage by tests of the method m
Matched methods cumulates two highly error prone code smells:
• A complex method, difficult to develop and maintain.
• Non 100% covered code, difficult to refactor without any regression bug.
The higher the CRAP score, the more painful to maintain and error prone is the method.
An arbitrary threshold of 30 is fixed for this code rule as suggested by inventors.
Notice that no amount of testing will keep methods with a Cyclomatic Complexity higher than 30, out of CRAP territory.
Notice that CRAP score is not computed for too short methods with less than 10 lines of code.
To list methods with higher C.R.A.P scores, please refer to the default rule: Test and Code Coverage > C.R.A.P method code metric
Average C.R.A.P Score - Coverage
The Formula is: CRAP(m) = CC(m)^2 * (1 – cov(m)/100)^3 + CC(m)
• where CC(m) is the cyclomatic complexity of the method m
• and cov(m) is the percentage coverage by tests of the method m
Matched methods cumulates two highly error prone code smells:
• A complex method, difficult to develop and maintain.
• Non 100% covered code, difficult to refactor without any regression bug.
The higher the CRAP score, the more painful to maintain and error prone is the method.
An arbitrary threshold of 30 is fixed for this code rule as suggested by inventors.
Notice that no amount of testing will keep methods with a Cyclomatic Complexity higher than 30, out of CRAP territory.
Notice that CRAP score is not computed for too short methods with less than 10 lines of code.
To list methods with higher C.R.A.P scores, please refer to the default rule: Test and Code Coverage > C.R.A.P method code metric
Percentage JustMyCode Coverage - Coverage
# Lines of JustMyCode Covered - Coverage
# Lines of JustMyCode Not Covered - Coverage
# Third-Party Assemblies Used - Third-Party Usage
# Third-Party Namespaces Used - Third-Party Usage
# Third-Party Types Used - Third-Party Usage
# Third-Party Methods Used - Third-Party Usage
# Third-Party Fields Used - Third-Party Usage
# Third-Party Code Elements Used - Third-Party Usage
New assemblies - Code Diff Summary
This code query lists assemblies that have been added since the baseline.
Assemblies removed - Code Diff Summary
This code query lists assemblies that have been removed since the baseline.
Assemblies where code was changed - Code Diff Summary
This code query lists assemblies in which, code has been changed since the baseline.
New namespaces - Code Diff Summary
This code query lists namespaces that have been added since the baseline.
Namespaces removed - Code Diff Summary
This code query lists namespaces that have been removed since the baseline.
Namespaces where code was changed - Code Diff Summary
This code query lists namespaces in which, code has been changed since the baseline.
New types - Code Diff Summary
This code query lists types that have been added since the baseline.
Types removed - Code Diff Summary
This code query lists types that have been removed since the baseline.
Types where code was changed - Code Diff Summary
This code query lists types in which, code has been changed since the baseline.
To visualize changes in code, right-click a matched type and select:
• Compare older and newer versions of source file
• Compare older and newer versions decompiled with Reflector
Heuristic to find types moved from one namespace or assembly to another - Code Diff Summary
This code query lists types moved from one namespace or assembly to another. The heuristic implemented consists in making a join LINQ query on type name (without namespace prefix), applied to the two sets of types added and types removed.
Types directly using one or several types changed - Code Diff Summary
This code query lists types unchanged since the baseline but that use directly some types where code has been changed since the baseline.
For such matched type, the code hasen't been changed, but still the overall behavior might have been changed.
The query result includes types changed directly used,
Types indirectly using one or several types changed - Code Diff Summary
This code query lists types unchanged since the baseline but that use directly or indirectly some types where code has been changed since the baseline.
For such matched type, the code hasen't been changed, but still the overall behavior might have been changed.
The query result includes types changed directly used, and the depth of usage of types indirectly used, depth of usage as defined in the documentation of DepthOfIsUsingAny() NDepend API method: https://www.ndepend.com/api/webframe.html#NDepend.API~NDepend.CodeModel.ExtensionMethodsSequenceUsage~DepthOfIsUsingAny.html
New methods - Code Diff Summary
This code query lists methods that have been added since the baseline.
Methods removed - Code Diff Summary
This code query lists methods that have been removed since the baseline.
Methods where code was changed - Code Diff Summary
This code query lists methods in which, code has been changed since the baseline.
To visualize changes in code, right-click a matched method and select:
• Compare older and newer versions of source file
• Compare older and newer versions decompiled with Reflector
Methods directly calling one or several methods changed - Code Diff Summary
This code query lists methods unchanged since the baseline but that call directly some methods where code has been changed since the baseline.
For such matched method, the code hasen't been changed, but still the overall behavior might have been changed.
The query result includes methods changed directly used,
Methods indirectly calling one or several methods changed - Code Diff Summary
This code query lists methods unchanged since the baseline but that use directly or indirectly some methods where code has been changed since the baseline.
For such matched method, the code hasen't been changed, but still the overall behavior might have been changed.
The query result includes methods changed directly used, and the depth of usage of methods indirectly used, depth of usage as defined in the documentation of DepthOfIsUsingAny() NDepend API method: https://www.ndepend.com/api/webframe.html#NDepend.API~NDepend.CodeModel.ExtensionMethodsSequenceUsage~DepthOfIsUsingAny.html
New fields - Code Diff Summary
This code query lists fields that have been added since the baseline.
Fields removed - Code Diff Summary
This code query lists fields that have been removed since the baseline.
Third party types that were not used and that are now used - Code Diff Summary
This code query lists types defined in third-party assemblies, that were not used at baseline time, and that are now used.
Third party types that were used and that are not used anymore - Code Diff Summary
This code query lists types defined in third-party assemblies, that were used at baseline time, and that are not used anymore.
Third party methods that were not used and that are now used - Code Diff Summary
This code query lists methods defined in third-party assemblies, that were not used at baseline time, and that are now used.
Third party methods that were used and that are not used anymore - Code Diff Summary
This code query lists methods defined in third-party assemblies, that were used at baseline time, and that are not used anymore.
Third party fields that were not used and that are now used - Code Diff Summary
This code query lists fields defined in third-party assemblies, that were not used at baseline time, and that are now used.
Third party fields that were used and that are not used anymore - Code Diff Summary
This code query lists fields defined in third-party assemblies, that were used at baseline time, and that are not used anymore.
Most used types (Rank) - Statistics
See the definition of the TypeRank metric here: https://www.ndepend.com/docs/code-metrics#TypeRank
This code query lists the 100 application types with the higher rank.
The main consequence of being used a lot for a type is that each change (both syntax change and behavior change) will result in potentially a lot of pain since most types clients will be impacted.
Hence it is preferable that types with higher TypeRank, are interfaces, that are typically less subject changes.
Also interfaces avoid clients relying on implementations details. Hence, when the behavior of classes implementing an interface changes, this shouldn't impact clients of the interface. This is in essence the Liskov Substitution Principle. http://en.wikipedia.org/wiki/Liskov_substitution_principle
Most used methods (Rank) - Statistics
See the definition of the MethodRank metric here: https://www.ndepend.com/docs/code-metrics#MethodRank
This code query lists the 100 application methods with the higher rank.
The main consequence of being used a lot for a method is that each change (both signature change and behavior change) will result in potentially a lot of pain since most methods callers will be impacted.
Hence it is preferable that methods with highest MethodRank, are abstract methods, that are typically less subject to signature changes.
Also abstract methods avoid callers relying on implementations details. Hence, when the code of a method implementing an abstract method changes, this shouldn't impact callers of the abstract method. This is in essence the Liskov Substitution Principle. http://en.wikipedia.org/wiki/Liskov_substitution_principle
Most used assemblies (#AssembliesUsingMe) - Statistics
Most used namespaces (#NamespacesUsingMe ) - Statistics
Most used types (#TypesUsingMe ) - Statistics
Most used methods (#MethodsCallingMe ) - Statistics
Namespaces that use many other namespaces (#NamespacesUsed ) - Statistics
Types that use many other types (#TypesUsed ) - Statistics
Methods that use many other methods (#MethodsCalled ) - Statistics
High-level to low-level assemblies (Level) - Statistics
High-level to low-level namespaces (Level) - Statistics
High-level to low-level types (Level) - Statistics
High-level to low-level methods (Level) - Statistics
Check that the assembly Asm1 is not using the assembly Asm2 - Check Architecture
It shows how to be warned if a particular assembly is using another particular assembly.
Such rule can be generated for assemblies A and B:
• by right clicking the cell in the Dependency Matrix with B in row and A in column,
• or by right-clicking the concerned arrow in the Dependency Graph from A to B,
and in both cases, click the menu Generate a code rule that warns if this dependency exists
The generated rule will look like this one. It is now up to you to adapt this rule to check exactly your needs.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the namespace N1.N2 is not using the namespace N3.N4.N5 - Check Architecture
It shows how to be warned if a particular namespace is using another particular namespace.
Such rule can be generated for namespaces A and B:
• by right clicking the cell in the Dependency Matrix with B in row and A in column,
• or by right-clicking the concerned arrow in the Dependency Graph from A to B,
and in both cases, click the menu Generate a code rule that warns if this dependency exists
The generated rule will look like this one. It is now up to you to adapt this rule to check exactly your needs.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the assembly Asm1 is only using the assemblies Asm2, Asm3 or System.Runtime - Check Architecture
It shows how to enforce that a particular assembly is only using a particular set of assemblies.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the namespace N1.N2 is only using the namespaces N3.N4, N5 or System - Check Architecture
It shows how to enforce that a particular namespace is only using a particular set of namespaces.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that AsmABC is the only assembly that is using System.Collections.Concurrent - Check Architecture
It shows how to enforce that a particular assembly is only used by another particular assembly.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that only 3 assemblies are using System.Collections.Concurrent - Check Architecture
It shows how to enforce that a particular assembly is only used by 3 any others assemblies.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that all methods that call Foo.Fct1() also call Foo.Fct2(Int32) - Check Architecture
It shows how to enforce that if a method calls a particular method, it must call another particular method.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that all types that derive from Foo, also implement IFoo - Check Architecture
It shows how to enforce that all classes that derive from a particular base class, also implement a particular interface.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that all types that has the attribute FooAttribute are declared in the namespace N1.N2* - Check Architecture
It shows how to enforce that all types that are tagged with a particular attribute, are declared in a particular namespace.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that all synchronization objects are only used from the namespaces under MyNamespace.Sync - Check Architecture
It shows how to enforce that all synchronization objects are used from a particular namespace.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the namespace N1.N2 is 100% covered by tests - Check Coverage on particular Code Elements
To execute this sample rule, coverage data must be imported. More info here: https://www.ndepend.com/docs/code-coverage
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the assembly Asm is 100% covered by tests - Check Coverage on particular Code Elements
To execute this sample rule, coverage data must be imported. More info here: https://www.ndepend.com/docs/code-coverage
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the class Namespace.Foo is 100% covered by tests - Check Coverage on particular Code Elements
To execute this sample rule, coverage data must be imported. More info here: https://www.ndepend.com/docs/code-coverage
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that the method Namespace.Foo.Method(Int32) is 100% covered by tests - Check Coverage on particular Code Elements
To execute this sample rule, coverage data must be imported. More info here: https://www.ndepend.com/docs/code-coverage
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that all types that derive from Foo, has a name that ends up with Foo - Custom Naming Conventions
It shows how to enforce that all classes that derive from a particular class, are named with a particular suffix.
How to Fix:
This is a sample rule there is nothing to fix as is.
Check that all namespaces begins with CompanyName.ProductName - Custom Naming Conventions
This rule must be adapted with your own "CompanyName.ProductName".
How to Fix:
Update all namespaces definitions in source code to satisfy this rule.